Фильтр Блума — это вероятностная структура данных , эффективно использующая память , придуманная Бертоном Говардом Блумом в 1970 году, которая используется для проверки того, является ли элемент членом множества . Ложноположительные совпадения возможны, но ложноотрицательные — нет, другими словами, запрос возвращает либо «возможно в множестве», либо «определенно не в множестве». Элементы можно добавлять в множество, но нельзя удалять (хотя это можно решить с помощью варианта фильтра Блума с подсчетом); чем больше элементов добавляется, тем больше вероятность ложноположительных результатов.
Блум предложил метод для приложений, где объем исходных данных потребовал бы непрактично большого объема памяти, если бы применялись «обычные» методы хеширования без ошибок. Он привел пример алгоритма переноса для словаря из 500 000 слов, из которых 90% следуют простым правилам переноса, но оставшиеся 10% требуют дорогостоящего доступа к диску для извлечения определенных шаблонов переноса. При достаточном объеме основной памяти безошибочный хеш можно использовать для устранения всех ненужных доступов к диску; с другой стороны, при ограниченной основной памяти метод Блума использует меньшую область хеширования, но все равно устраняет большинство ненужных доступов. Например, область хеширования, составляющая всего 18% от размера, необходимого для идеального безошибочного хеша, все еще устраняет 87% доступов к диску. [1]
В более общем случае для 1% вероятности ложного срабатывания требуется менее 10 бит на элемент, независимо от размера или количества элементов в наборе. [2]
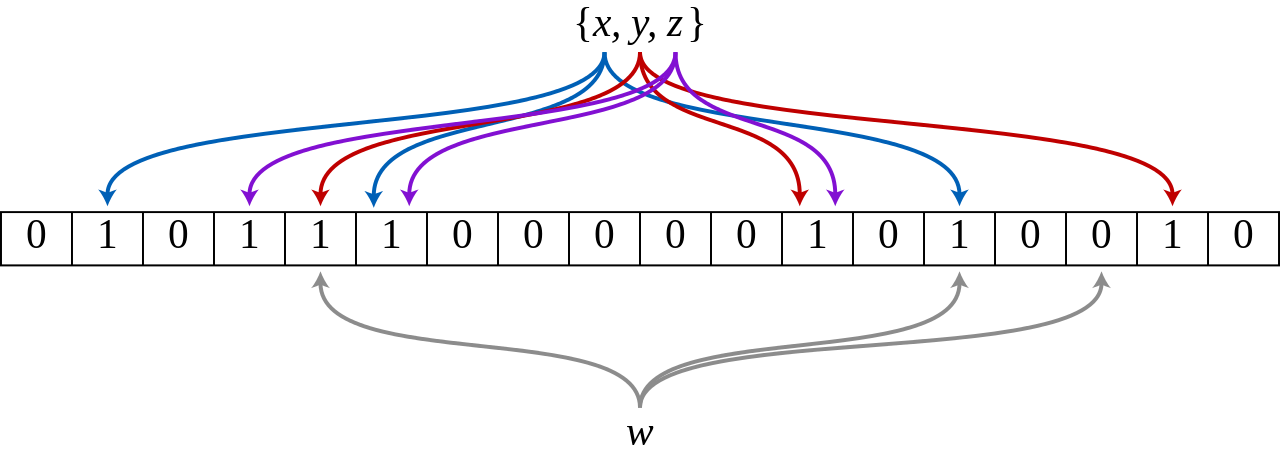
Пустой фильтр Блума — это битовый массив из m битов, все из которых установлены в 0. Он оснащен k различными хэш-функциями , которые сопоставляют элементы множества с одной из m возможных позиций массива. Чтобы быть оптимальными, хэш-функции должны быть равномерно распределены и независимы . Обычно k — это небольшая константа, которая зависит от желаемой частоты ложных ошибок ε , в то время как m пропорциональна k и количеству добавляемых элементов.
Чтобы добавить элемент, передайте его каждой из k хэш-функций, чтобы получить k позиций массива. Установите биты во всех этих позициях на 1.
Чтобы проверить , находится ли элемент в наборе, передайте его каждой из k хэш-функций, чтобы получить k позиций массива. Если какой-либо из битов в этих позициях равен 0, элемент определенно не находится в наборе; если бы это было так, то все биты были бы установлены в 1 при его вставке. Если все биты равны 1, то либо элемент находится в наборе, либо биты случайно были установлены в 1 во время вставки других элементов, что привело к ложному срабатыванию . В простом фильтре Блума нет способа различить эти два случая, но более продвинутые методы могут решить эту проблему.
Требование проектирования k различных независимых хэш-функций может быть непомерно большим для больших k . Для хорошей хэш-функции с широким выходом должно быть мало корреляций между различными битовыми полями такого хеша, если они вообще будут, поэтому этот тип хеша можно использовать для генерации нескольких «разных» хэш-функций путем нарезки его выходных данных на несколько битовых полей. В качестве альтернативы можно передать k различных начальных значений (например, 0, 1, ..., k − 1) в хэш-функцию, которая принимает начальное значение; или добавить (или присоединить) эти значения к ключу. Для больших m и/или k независимость между хэш-функциями может быть ослаблена с незначительным увеличением частоты ложных срабатываний. [3] (В частности, Dillinger & Manolios (2004b) показывают эффективность вывода индексов k с использованием улучшенного двойного хэширования и тройного хэширования , вариантов двойного хэширования , которые фактически являются простыми генераторами случайных чисел, затравленными двумя или тремя хэш-значениями.)
Удаление элемента из этого простого фильтра Блума невозможно, поскольку нет способа определить, какой из k битов, с которыми он сопоставляется, должен быть очищен. Хотя установка любого из этих k битов в ноль достаточна для удаления элемента, это также удалит любые другие элементы, которые случайно сопоставляются с этим битом. Поскольку простой алгоритм не предоставляет способа определить, были ли добавлены какие-либо другие элементы, которые влияют на биты для удаляемого элемента, очистка любого из битов приведет к возможности ложных отрицательных результатов.
Однократное удаление элемента из фильтра Блума можно смоделировать, имея второй фильтр Блума, содержащий элементы, которые были удалены. Однако ложные положительные результаты во втором фильтре становятся ложными отрицательными результатами в составном фильтре, что может быть нежелательным. При таком подходе повторное добавление ранее удаленного элемента невозможно, так как его пришлось бы удалить из «удаленного» фильтра.
Часто бывает так, что все ключи доступны, но их перебор обходится дорого (например, требуется много чтений с диска). Когда уровень ложных срабатываний становится слишком высоким, фильтр можно сгенерировать заново; это должно быть относительно редким событием.

Несмотря на риск ложных срабатываний, фильтры Блума имеют существенное преимущество в пространстве по сравнению с другими структурами данных для представления наборов, такими как самобалансирующиеся двоичные деревья поиска , попытки , хэш-таблицы или простые массивы или связанные списки записей. Большинство из них требуют хранения по крайней мере самих элементов данных, что может потребовать от небольшого количества бит для небольших целых чисел до произвольного количества бит, например, для строк ( попытки являются исключением, поскольку они могут совместно использовать хранилище между элементами с одинаковыми префиксами). Однако фильтры Блума вообще не хранят элементы данных, и для фактического хранения должно быть предоставлено отдельное решение. Связанные структуры влекут за собой дополнительные линейные накладные расходы на пространство для указателей. Фильтр Блума с ошибкой 1% и оптимальным значением k , напротив, требует всего около 9,6 бит на элемент, независимо от размера элементов. Это преимущество частично обусловлено его компактностью, унаследованной от массивов, и частично его вероятностной природой. Показатель ложноположительных результатов в 1% можно снизить в десять раз, добавив всего лишь около 4,8 бит на элемент.
Однако, если число потенциальных значений невелико и многие из них могут быть в наборе, фильтр Блума легко превзойдет детерминированный битовый массив , который требует только один бит для каждого потенциального элемента. Хеш-таблицы получат преимущество в пространстве и времени, если они начнут игнорировать коллизии и хранить только то, содержит ли каждое ведро запись; в этом случае они фактически станут фильтрами Блума с k = 1. [4 ]
Фильтры Блума также обладают необычным свойством, заключающимся в том, что время, необходимое для добавления элементов или проверки наличия элемента в наборе, является фиксированной константой, O( k ) , совершенно независимой от количества элементов, уже находящихся в наборе. Никакая другая структура данных с константным пространством не обладает этим свойством, но среднее время доступа к разреженным хэш-таблицам может сделать их на практике быстрее, чем некоторые фильтры Блума. Однако в аппаратной реализации фильтр Блума блистает, поскольку его k поисков независимы и могут быть распараллелены.
Чтобы понять его пространственную эффективность, полезно сравнить общий фильтр Блума с его частным случаем, когда k = 1. Если k = 1 , то для того, чтобы поддерживать достаточно низкий уровень ложных срабатываний, следует установить небольшую часть битов, что означает, что массив должен быть очень большим и содержать длинные серии нулей. Информационное содержание массива относительно его размера невелико. Обобщенный фильтр Блума ( k больше 1) позволяет устанавливать гораздо больше битов, сохраняя при этом низкий уровень ложных срабатываний; если параметры ( k и m ) выбраны правильно, будет установлено около половины битов [5] , и они будут, по-видимому, случайными, что минимизирует избыточность и максимизирует информационное содержание.

Предположим, что хэш-функция выбирает каждую позицию массива с равной вероятностью. Если m — число бит в массиве, вероятность того, что определенный бит не будет установлен в 1 определенной хэш-функцией во время вставки элемента, равна
Если k — число хэш-функций, и каждая из них не имеет значительной корреляции друг с другом, то вероятность того, что бит не будет установлен в 1 ни одной из хэш-функций, равна
Мы можем использовать известное тождество для e −1
сделать вывод, что при больших m ,
Если мы вставили n элементов, вероятность того, что определенный бит все еще равен 0, равна
вероятность того, что это 1, поэтому
Теперь проверим членство элемента, которого нет в наборе. Каждая из k позиций массива, вычисленных хэш-функциями, равна 1 с вероятностью, как указано выше. Вероятность того, что все они равны 1, что заставило бы алгоритм ошибочно утверждать, что элемент находится в наборе, часто задается как
Это не совсем верно, поскольку предполагает независимость вероятностей установки каждого бита. Однако, предполагая, что это близкое приближение, мы получаем, что вероятность ложных срабатываний уменьшается с увеличением m (количества бит в массиве) и увеличивается с увеличением n (количества вставленных элементов).
Истинная вероятность ложного срабатывания, без предположения независимости, равна
где {фигурные скобки} обозначают числа Стерлинга второго рода . [6]
Альтернативный анализ, приходящий к тому же приближению без предположения о независимости, представлен Митценмахером и Упфалом. [7] После того, как все n элементов были добавлены в фильтр Блума, пусть q будет долей m битов, которые установлены в 0. (То есть, количество битов, все еще установленных в 0, равно qm .) Затем, при проверке принадлежности элемента, не входящего в набор, для позиции массива, заданной любой из k хэш-функций, вероятность того, что бит будет установлен в 1, равна . Таким образом, вероятность того, что все k хэш-функции обнаружат свой бит, установленный в 1, равна . Кроме того, ожидаемое значение q является вероятностью того, что заданная позиция массива останется нетронутой каждой из k хэш-функций для каждого из n элементов, что равно (как указано выше)
Можно доказать, без предположения о независимости, что q очень сильно сконцентрировано вокруг своего ожидаемого значения. В частности, из неравенства Азумы–Хеффдинга они доказывают, что [8]
В связи с этим мы можем сказать, что точная вероятность ложных срабатываний составляет
как и прежде.
Число хэш-функций k должно быть положительным целым числом. Оставив это ограничение в стороне, для заданных m и n значение k , которое минимизирует вероятность ложного срабатывания, равно
Необходимое количество бит m , учитывая n (количество вставленных элементов) и желаемую вероятность ложного срабатывания ε (и предполагая, что используется оптимальное значение k ), можно вычислить, подставив оптимальное значение k в выражение вероятности выше:
что можно упростить до:
Это приводит к:
Таким образом, оптимальное количество бит на элемент равно
с соответствующим числом хэш-функций k (без учета целочисленности):
Это означает, что для заданной вероятности ложного срабатывания ε длина фильтра Блума m пропорциональна количеству фильтруемых элементов n , а требуемое количество хеш-функций зависит только от целевой вероятности ложного срабатывания ε . [9]
Формула является приближенной по трем причинам. Во-первых, и это вызывает наименьшее беспокойство, она приближается как , что является хорошим асимптотическим приближением (т. е., которое выполняется при m →∞). Во-вторых, что вызывает большее беспокойство, она предполагает, что во время проверки принадлежности событие, когда один проверенный бит устанавливается в 1, не зависит от события, когда любой другой проверенный бит устанавливается в 1. В-третьих, что вызывает наибольшее беспокойство, она предполагает, что является случайным целым.
Однако Гоэль и Гупта [10] дают строгую верхнюю границу, которая не делает приближений и не требует никаких предположений. Они показывают, что вероятность ложного срабатывания для конечного фильтра Блума с m битами ( ), n элементами и k хэш-функциями не превышает
Эту границу можно интерпретировать как то, что приближенную формулу можно применять со штрафом не более чем на половину дополнительного элемента и не более чем на один бит меньше.
Число элементов в фильтре Блума можно приблизительно рассчитать по следующей формуле:
где — оценка количества элементов в фильтре, m — длина (размер) фильтра, k — количество хэш-функций, а X — количество битов, установленных в единицу. [11]
Фильтры Блума — это способ компактного представления набора элементов. Обычно пытаются вычислить размер пересечения или объединения двух множеств. Фильтры Блума можно использовать для аппроксимации размера пересечения и объединения двух множеств. Для двух фильтров Блума длины m их количество можно оценить как
и
Размер их союза можно оценить как
где — число битов, установленных в единицу в любом из двух фильтров Блума. Наконец, пересечение можно оценить как
используя три формулы вместе. [11]
Классические фильтры Блума используют биты пространства на вставленный ключ, где — частота ложных срабатываний фильтра Блума. Однако пространство, которое строго необходимо для любой структуры данных, играющей ту же роль, что и фильтр Блума, — только на ключ. [26] Следовательно, фильтры Блума используют на 44% больше пространства, чем эквивалентная оптимальная структура данных.
Паг и др. предлагают структуру данных, которая использует биты, поддерживая при этом постоянные амортизированные операции с ожидаемым временем. [27] Их структура данных в основном теоретическая, но она тесно связана с широко используемым фильтром факторизации , который может быть параметризован для использования битов пространства для произвольного параметра , поддерживая при этом операции с временем. [28] Преимущества фильтра факторизации по сравнению с фильтром Блума включают в себя локальность ссылок и способность поддерживать удаления.
Другой альтернативой классическому фильтру Блума является фильтр кукушки , основанный на экономичных по пространству вариантах хеширования кукушки . В этом случае создается хеш-таблица, не содержащая ни ключей, ни значений, а только короткие отпечатки (небольшие хеши) ключей. Если при поиске ключа обнаруживается совпадающий отпечаток, то ключ, вероятно, находится в наборе. Фильтры кукушки поддерживают удаления и имеют лучшую локальность ссылок, чем фильтры Блума. [29] Кроме того, в некоторых режимах параметров фильтры кукушки могут быть параметризованы для обеспечения почти оптимальных гарантий пространства. [29]
Многие альтернативы фильтрам Блума, включая фильтры коэффициентов и фильтры кукушки , основаны на идее хеширования ключей для случайных -битных отпечатков пальцев и последующего сохранения этих отпечатков пальцев в компактной хеш-таблице. Эта техника, впервые представленная Картером и др. в 1978 году, [26] основана на том факте, что компактные хеш-таблицы могут быть реализованы для использования примерно на бит меньше пространства, чем их некомпактные аналоги. Используя краткие хеш-таблицы, использование пространства может быть сокращено до бит [30] , при этом поддерживая операции с постоянным временем в широком диапазоне режимов параметров.
Putze, Sanders & Singler (2007) изучили несколько вариантов фильтров Блума, которые либо быстрее, либо используют меньше места, чем классические фильтры Блума. Основная идея быстрого варианта заключается в размещении значений хэша k, связанных с каждым ключом, в одном или двух блоках, имеющих тот же размер, что и блоки кэш-памяти процессора (обычно 64 байта). Это, предположительно, улучшит производительность за счет сокращения количества потенциальных промахов кэш-памяти . Однако предлагаемые варианты имеют недостаток, заключающийся в использовании примерно на 32% больше места, чем классические фильтры Блума.
Вариант с эффективным использованием пространства основан на использовании одной хэш-функции, которая генерирует для каждого ключа значение в диапазоне , где — запрашиваемая частота ложных срабатываний. Затем последовательность значений сортируется и сжимается с использованием кодирования Голомба (или какой-либо другой техники сжатия), чтобы занять пространство, близкое к битам. Чтобы запросить фильтр Блума для данного ключа, достаточно проверить, хранится ли его соответствующее значение в фильтре Блума. Распаковка всего фильтра Блума для каждого запроса сделала бы этот вариант совершенно непригодным для использования. Чтобы преодолеть эту проблему, последовательность значений делится на небольшие блоки одинакового размера, которые сжимаются по отдельности. Во время запроса в среднем нужно будет распаковать только половину блока. Из-за накладных расходов на распаковку этот вариант может быть медленнее классических фильтров Блума, но это может быть компенсировано тем фактом, что необходимо вычислить одну хэш-функцию.
Граф и Лемир (2020) описывают подход, называемый фильтром xor, в котором они хранят отпечатки пальцев в определенном типе идеальной хеш- таблицы, создавая фильтр, который более эффективен в плане памяти ( бит на ключ) и быстрее, чем фильтры Блума или кукушки. (Экономия времени достигается за счет того, что для поиска требуется ровно три доступа к памяти, которые могут выполняться параллельно.) Однако создание фильтра сложнее, чем у фильтров Блума и кукушки, и изменить набор после создания невозможно.
Существует более 60 вариантов фильтров Блума, множество обзоров в этой области и продолжающееся бурление приложений (см., например, Luo и др. [31] ). Некоторые из вариантов достаточно сильно отличаются от первоначального предложения, чтобы быть нарушениями или ответвлениями исходной структуры данных и ее философии. [31] Обработка, которая объединяет фильтры Блума с другими работами по случайным проекциям , сжатому зондированию и локально-чувствительному хешированию, еще предстоит сделать (хотя см. Dasgupta и др . [32] для одной попытки, вдохновленной нейронаукой).

Сети доставки контента используют веб-кэши по всему миру для кэширования и предоставления веб-контента пользователям с большей производительностью и надежностью. Ключевым применением фильтров Блума является их использование для эффективного определения того, какие веб-объекты следует хранить в этих веб-кэшах. Почти три четверти URL-адресов, к которым обращаются из типичного веб-кэша, являются «одноразовыми», к которым пользователи обращаются только один раз и никогда больше. Очевидно, что хранение одноразовых чудес в веб-кэше — это расточительство дисковых ресурсов, поскольку к ним больше никогда не будут обращаться. Чтобы предотвратить кэширование одноразовых чудес, фильтр Блума используется для отслеживания всех URL-адресов, к которым обращаются пользователи. Веб-объект кэшируется только тогда, когда к нему обращались хотя бы один раз, т. е. объект кэшируется при втором запросе. Использование фильтра Блума таким образом значительно снижает нагрузку на запись на диск, поскольку большинство одноразовых чудес не записываются в дисковый кэш. Кроме того, отфильтровывание «чудес с одним попаданием» также экономит место в кэше на диске, увеличивая частоту попаданий в кэш. [13]
Кисс и др . [33] описали новую конструкцию фильтра Блума, которая позволяет избежать ложных положительных результатов в дополнение к типичному отсутствию ложных отрицательных результатов. Конструкция применяется к конечной вселенной, из которой берутся элементы набора. Она основана на существующей неадаптивной схеме комбинаторного группового тестирования Эппштейна, Гудрича и Хиршберга. В отличие от типичного фильтра Блума, элементы хэшируются в битовый массив с помощью детерминированных, быстрых и простых в вычислении функций. Максимальный размер набора, для которого полностью избегаются ложные положительные результаты, является функцией размера вселенной и контролируется объемом выделенной памяти.
В качестве альтернативы, начальный фильтр Блума может быть построен стандартным способом, а затем, с конечным и легко перечислимым доменом, все ложные срабатывания могут быть исчерпывающе найдены, а затем второй фильтр Блума построен из этого списка; ложные срабатывания во втором фильтре аналогичным образом обрабатываются путем построения третьего и т. д. Поскольку вселенная конечна, а набор ложных срабатываний строго сокращается с каждым шагом, эта процедура приводит к конечному каскаду фильтров Блума, которые (в этом замкнутом конечном домене) будут производить только истинно положительные и истинно отрицательные результаты. Чтобы проверить членство в каскаде фильтров, запрашивается начальный фильтр, и, если результат положительный, затем обращается ко второму фильтру и т. д. Эта конструкция используется в CRLite , предлагаемом механизме распределения статуса отзыва сертификатов для Web PKI, а прозрачность сертификатов используется для закрытия набора существующих сертификатов. [34]
Фильтры подсчета предоставляют способ реализовать операцию удаления в фильтре Блума без повторного создания фильтра заново. В фильтре подсчета позиции массива (корзины) расширяются от однобитовых до многобитовых счетчиков. Фактически, обычные фильтры Блума можно рассматривать как фильтры подсчета с размером корзины в один бит. Фильтры подсчета были введены Фаном и др. (2000).
Операция вставки расширена для увеличения значения ведер, а операция поиска проверяет, что каждое из требуемых ведер не равно нулю. Операция удаления затем состоит из уменьшения значения каждого из соответствующих ведер.
Арифметическое переполнение ведер является проблемой, и ведра должны быть достаточно большими, чтобы этот случай был редким. Если это происходит, то операции увеличения и уменьшения должны оставлять ведро установленным на максимально возможное значение, чтобы сохранить свойства фильтра Блума.
Размер счетчиков обычно составляет 3 или 4 бита. Таким образом, подсчетные фильтры Блума используют в 3–4 раза больше места, чем статические фильтры Блума. Напротив, структуры данных Pagh, Pagh & Rao (2005) и Fan et al. (2014) также допускают удаления, но используют меньше места, чем статический фильтр Блума.
Другая проблема с подсчетными фильтрами — ограниченная масштабируемость. Поскольку таблица подсчетных фильтров Блума не может быть расширена, максимальное количество ключей, которые могут одновременно храниться в фильтре, должно быть известно заранее. После превышения проектной емкости таблицы частота ложных срабатываний будет быстро расти по мере добавления новых ключей.
Бономи и др. (2006) представили структуру данных, основанную на хешировании d-left, которая функционально эквивалентна, но использует примерно вдвое меньше места, чем подсчет фильтров Блума. Проблема масштабируемости не возникает в этой структуре данных. После превышения проектной емкости ключи можно повторно вставить в новую хеш-таблицу двойного размера.
Вариант с эффективным использованием пространства, предложенный Putze, Sanders & Singler (2007), также может быть использован для реализации счетных фильтров путем поддержки вставок и удалений.
Rottenstreich, Kanizo & Keslassy (2012) представили новый общий метод, основанный на переменных приращениях, который значительно повышает вероятность ложного срабатывания подсчета фильтров Блума и их вариантов, при этом по-прежнему поддерживая удаления. В отличие от подсчета фильтров Блума, при каждой вставке элемента хешированные счетчики увеличиваются на хешированный переменный прирост вместо единичного приращения. Для запроса элемента учитываются точные значения счетчиков, а не только их положительность. Если сумма, представленная значением счетчика, не может быть составлена из соответствующего переменного приращения для запрашиваемого элемента, на запрос может быть возвращен отрицательный ответ.
Ким и др. (2019) показывают, что ложное срабатывание подсчетного фильтра Блума уменьшается от k=1 до определенной точки и увеличивается от до положительной бесконечности, и находится в зависимости от порогового значения подсчета. [35]
Фильтры Блума могут быть организованы в распределенные структуры данных для выполнения полностью децентрализованных вычислений агрегатных функций . Децентрализованное агрегирование делает коллективные измерения локально доступными в каждом узле распределенной сети без привлечения централизованной вычислительной сущности для этой цели. [36]
Параллельные фильтры Блума могут быть реализованы для использования преимуществ множественных элементов обработки (PE), присутствующих в параллельных машинах без общего доступа . Одним из основных препятствий для параллельного фильтра Блума является организация и передача неупорядоченных данных, которые, как правило, равномерно распределяются по всем PE при инициализации или при пакетных вставках. Для упорядочения данных могут использоваться два подхода, либо приводящие к фильтру Блума по всем данным, хранящимся на каждом PE, называемому реплицирующим фильтром Блума, либо фильтр Блума по всем данным, разделенным на равные части, причем каждый PE хранит одну его часть. [37] Для обоих подходов используется фильтр Блума «Single Shot», который вычисляет только один хэш, что приводит к одному перевернутому биту на элемент, чтобы уменьшить объем коммуникации.
Распределенные фильтры Блума инициируются путем хеширования всех элементов на их локальном PE, а затем локальной сортировки их по хэшам. Это можно сделать за линейное время, например, с помощью сортировки ведром , а также позволяет локально обнаруживать дубликаты. Сортировка используется для группировки хэшей с назначенным им PE в качестве разделителя для создания фильтра Блума для каждой группы. После кодирования этих фильтров Блума с помощью, например, кодирования Голомба, каждый фильтр Блума отправляется в виде пакета в PE, ответственный за значения хэша, которые были в него вставлены. PE p отвечает за все хэши между значениями и , где s — общий размер фильтра Блума по всем данным. Поскольку каждый элемент хэшируется только один раз и, следовательно, устанавливается только один бит, для проверки того, был ли элемент вставлен в фильтр Блума, необходимо обработать только PE, ответственный за значение хэша элемента. Операции одиночной вставки также могут выполняться эффективно, поскольку необходимо изменить фильтр Блума только одного PE, по сравнению с репликацией фильтров Блума, где каждому PE пришлось бы обновить свой фильтр Блума. Распределяя глобальный фильтр Блума по всем PE вместо того, чтобы хранить его отдельно на каждом PE, размер фильтров Блума может быть намного больше, что приводит к большей емкости и меньшему уровню ложных срабатываний.
Распределенные фильтры Блума могут использоваться для улучшения алгоритмов обнаружения дубликатов [38] путем фильтрации наиболее «уникальных» элементов. Их можно вычислить, передавая только хэши элементов, а не сами элементы, которые намного больше по объему, и удаляя их из набора, уменьшая нагрузку на алгоритм обнаружения дубликатов, используемый впоследствии.
Во время передачи хэшей PE ищут биты, которые установлены более чем в одном из принимающих пакетов, так как это означало бы, что два элемента имели одинаковый хэш и, следовательно, могли быть дубликатами. Если это происходит, сообщение, содержащее индекс бита, который также является хешем элемента, который может быть дубликатом, отправляется PE, отправившим пакет с установленным битом. Если несколько индексов отправляются одному и тому же PE одним отправителем, может быть выгодно также кодировать индексы. Все элементы, которым не был отправлен их хэш, теперь гарантированно не являются дубликатами и не будут оцениваться далее, для оставшихся элементов может использоваться алгоритм перераспределения [39] . Сначала все элементы, которым было отправлено их хэш-значение, отправляются PE, за который отвечает их хэш. Теперь любой элемент и его дубликат гарантированно находятся на одном PE. На втором этапе каждый PE использует последовательный алгоритм для обнаружения дубликатов на принимающих элементах, которые составляют лишь часть от количества исходных элементов. Допуская частоту ложных срабатываний для дубликатов, можно еще больше сократить объем коммуникации, поскольку PE вообще не нужно отправлять элементы с дублированными хэшами, а вместо этого любой элемент с дублированным хешем можно просто пометить как дубликат. В результате частота ложных срабатываний для обнаружения дубликатов такая же, как частота ложных срабатываний используемого фильтра Блума.
Процесс фильтрации наиболее «уникальных» элементов также может быть повторен несколько раз путем изменения хэш-функции на каждом этапе фильтрации. Если используется только один этап фильтрации, он должен архивировать небольшой уровень ложных срабатываний, однако, если этап фильтрации повторяется один раз, первый этап может допустить более высокий уровень ложных срабатываний, в то время как последний имеет более высокий уровень, но также работает с меньшим количеством элементов, поскольку многие из них уже были удалены на предыдущем этапе фильтрации. Хотя использование более двух повторений может еще больше сократить объем коммуникации, если количество дубликатов в наборе невелико, отдача от дополнительных усложнений невелика.
Репликация фильтров Блума организует свои данные, используя известный алгоритм гиперкуба для сплетен, например [40] Сначала каждый PE вычисляет фильтр Блума по всем локальным элементам и сохраняет его. Повторяя цикл, где на каждом шаге i PE отправляют свой локальный фильтр Блума по измерению i и объединяют фильтр Блума, который они получают по измерению, со своим локальным фильтром Блума, можно удвоить элементы, которые каждый фильтр Блума содержит в каждой итерации. После отправки и получения фильтров Блума по всем измерениям каждый PE содержит глобальный фильтр Блума по всем элементам.
Репликационные фильтры Блума более эффективны, когда количество запросов намного превышает количество элементов, содержащихся в фильтре Блума; точка безубыточности по сравнению с распределенными фильтрами Блума находится примерно после обращений, при этом частота ложных срабатываний фильтра Блума равна частоте ложных срабатываний.
Фильтры Блума могут использоваться для приблизительной синхронизации данных , как в Байерсе и др. (2004). Подсчет фильтров Блума может использоваться для приблизительного подсчета числа различий между двумя наборами, и этот подход описан в Агарвале и Трахтенберге (2006).
Фильтры Блума можно адаптировать к контексту потоковых данных. Например, Дэн и Рафии (2006) предложили фильтры Стабильного Блума, которые состоят из подсчитывающего фильтра Блума, где вставка нового элемента устанавливает связанные счетчики в значение c , а затем только фиксированное количество счетчиков s уменьшается на 1, поэтому память в основном содержит информацию о последних элементах (интуитивно можно предположить, что время жизни элемента внутри SBF из N счетчиков составляет около ). Другое решение — фильтр Старения Блума, который состоит из двух фильтров Блума, каждый из которых занимает половину общей доступной памяти: когда один фильтр заполнен, второй фильтр стирается, и новые элементы затем добавляются к этому новому пустому фильтру. [41]
Однако было показано [42] , что независимо от фильтра, после n вставок сумма ложноположительных и ложноотрицательных вероятностей ограничена снизу величиной , где L — количество всех возможных элементов (размер алфавита), m — размер памяти (в битах), предполагая . Этот результат показывает, что при достаточно большом L и стремлении n к бесконечности нижняя граница сходится к , что является характерным отношением случайного фильтра. Следовательно, после достаточного количества вставок и если алфавит слишком велик для хранения в памяти (что предполагается в контексте вероятностных фильтров), фильтр не может работать лучше случайности. Этот результат можно использовать, ожидая, что фильтр будет работать только со скользящим окном, а не со всем потоком. В этом случае показатель степени n в приведенной выше формуле заменяется на w , что дает формулу, которая может отклоняться от 1, если w не слишком мало.
Шазелл и др. (2004) разработали обобщение фильтров Блума, которое могло бы связывать значение с каждым вставленным элементом, реализуя ассоциативный массив . Как и фильтры Блума, эти структуры достигают небольших накладных расходов пространства, принимая небольшую вероятность ложных срабатываний. В случае «фильтров Блумье» ложное срабатывание определяется как возврат результата, когда ключ отсутствует в карте. Карта никогда не вернет неправильное значение для ключа, который есть в карте.
Boldi & Vigna (2005) предложили обобщение фильтров Блума на основе решетки . Компактный аппроксиматор связывает с каждым ключом элемент решетки (стандартные фильтры Блума являются случаем булевой двухэлементной решетки). Вместо битового массива они имеют массив элементов решетки. При добавлении новой ассоциации между ключом и элементом решетки они вычисляют максимум текущего содержимого k ячеек массива, связанных с ключом, с элементом решетки. При считывании значения, связанного с ключом, они вычисляют минимум значений, найденных в k ячейках, связанных с ключом. Результирующее значение аппроксимирует сверху исходное значение.
Эта реализация использовала отдельный массив для каждой хэш-функции. Этот метод позволяет проводить параллельные вычисления хэша как для вставок, так и для запросов. [43]
Алмейда и др. (2007) предложили вариант фильтров Блума, который может динамически адаптироваться к количеству хранимых элементов, обеспечивая при этом минимальную вероятность ложного срабатывания. Метод основан на последовательностях стандартных фильтров Блума с увеличивающейся емкостью и более жесткими вероятностями ложного срабатывания, чтобы гарантировать, что максимальная вероятность ложного срабатывания может быть установлена заранее, независимо от количества вставляемых элементов.
Пространственные фильтры Блума (SBF) были первоначально предложены Пальмиери, Кальдерони и Майо (2014) как структура данных, предназначенная для хранения информации о местоположении , особенно в контексте криптографических протоколов для обеспечения конфиденциальности местоположения . Однако основной характеристикой SBF является их способность хранить несколько наборов в одной структуре данных, что делает их пригодными для ряда различных сценариев применения. [44] Членство элемента в определенном наборе может быть запрошено, а вероятность ложного срабатывания зависит от набора: первые наборы, которые будут введены в фильтр во время построения, имеют более высокие вероятности ложного срабатывания, чем наборы, введенные в конце. [45] Это свойство позволяет приоритезировать наборы, где наборы, содержащие более «важные» элементы, могут быть сохранены.
Многослойный фильтр Блума состоит из нескольких слоев фильтра Блума. Многослойные фильтры Блума позволяют отслеживать, сколько раз элемент был добавлен в фильтр Блума, проверяя, сколько слоев содержат элемент. С многослойным фильтром Блума операция проверки обычно возвращает номер самого глубокого слоя, в котором был найден элемент. [46]

Ослабленный фильтр Блума глубиной D можно рассматривать как массив из D обычных фильтров Блума. В контексте обнаружения сервисов в сети каждый узел локально хранит обычные и ослабленные фильтры Блума. Обычный или локальный фильтр Блума указывает, какие сервисы предлагаются самим узлом. Ослабленный фильтр уровня i указывает, какие сервисы могут быть найдены на узлах, которые находятся на расстоянии i переходов от текущего узла. Значение i формируется путем объединения локальных фильтров Блума для узлов, которые находятся на расстоянии i переходов от узла. [47]
Например, рассмотрим небольшую сеть, показанную на графике ниже. Допустим, мы ищем службу A, чей идентификатор хэшируется битами 0, 1 и 3 (шаблон 11010). Пусть узел n1 будет начальной точкой. Сначала мы проверяем, предлагается ли служба A узлом n1, проверяя его локальный фильтр. Поскольку шаблоны не совпадают, мы проверяем ослабленный фильтр Блума, чтобы определить, какой узел должен быть следующим переходом. Мы видим, что n2 не предлагает службу A, но лежит на пути к узлам, которые ее предлагают. Следовательно, мы переходим к n2 и повторяем ту же процедуру. Мы быстро обнаруживаем, что n3 предлагает службу, и, следовательно, пункт назначения находится. [48]
Используя ослабленные фильтры Блума, состоящие из нескольких слоев, можно обнаружить сервисы на расстоянии более одного скачка, избегая при этом насыщения фильтра Блума за счет ослабления (сдвига) битов, установленных источниками, расположенными дальше. [47]
Фильтры Блума часто используются для поиска в больших базах данных химических структур (см. химическое сходство ). В простейшем случае элементы, добавленные в фильтр (называемые отпечатками пальцев в этой области), представляют собой просто атомные номера, присутствующие в молекуле, или хэш, основанный на атомном номере каждого атома и количестве и типе его связей. Этот случай слишком прост, чтобы быть полезным. Более продвинутые фильтры также кодируют количество атомов, более крупные особенности подструктуры, такие как карбоксильные группы, и свойства графа, такие как количество колец. В отпечатках на основе хэшей хэш-функция, основанная на свойствах атома и связи, используется для превращения подграфа в начальное число PRNG , а первые выходные значения используются для установки битов в фильтре Блума.
Молекулярные отпечатки пальцев появились в конце 1940-х годов как способ поиска химических структур, искомых на перфокартах. Однако только около 1990 года Daylight Chemical Information Systems, Inc. представила основанный на хэше метод для генерации битов вместо использования предварительно вычисленной таблицы. В отличие от словарного подхода, метод хэширования может назначать биты для подструктур, которые ранее не встречались. В начале 1990-х годов термин «отпечаток пальца» считался отличным от «структурных ключей», но с тех пор этот термин расширился и охватывает большинство молекулярных характеристик, которые могут использоваться для сравнения сходства, включая структурные ключи, отпечатки пальцев с разреженным счетом и трехмерные отпечатки пальцев. В отличие от фильтров Блума, метод хэширования Daylight позволяет количеству битов, назначенных на признак, быть функцией размера признака, но большинство реализаций отпечатков пальцев, подобных Daylight, используют фиксированное количество бит на признак, что делает их фильтром Блума. Оригинальные отпечатки пальцев Daylight могли использоваться как для целей сходства, так и для целей скрининга. Многие другие типы отпечатков пальцев, такие как популярный ECFP2, могут использоваться для сходства, но не для скрининга, поскольку они включают локальные характеристики окружающей среды, которые вносят ложные отрицательные результаты при использовании в качестве скрининга. Даже если они построены с использованием того же механизма, они не являются фильтрами Блума, поскольку их нельзя использовать для фильтрации.
{{cite book}}: CS1 maint: location missing publisher (link)Cache Digests основаны на технике, впервые опубликованной Пэй Цао, которая называется Summary Cache. Основная идея заключается в использовании фильтра Блума для представления содержимого кэша.






![{\displaystyle \varepsilon =\left(1-\left[1-{\frac {1}{m}}\right]^{kn}\right)^{k}\approx \left(1-e^{-kn/m}\right)^{k}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/de73929baec5fd76dde95874189051648c635b1d)



![{\displaystyle E[q]=\left(1-{\frac {1}{m}}\right)^{kn}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c213b5ac119f9c4f695469b512545fc5b49ef8c1)
![{\displaystyle \Pr(\left|qE[q]\right|\geq {\frac {\lambda }{m}})\leq 2\exp(-2\lambda ^{2}/kn)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b63e23e0badb4182e147f75aa18b011421c014dc)
![{\displaystyle \sum _{t}\Pr(q=t)(1-t)^{k}\approx (1-E[q])^{k}=\left(1-\left[1-{\frac {1}{m}}\right]^{kn}\right)^{k}\approx \left(1-e^{-kn/m}\right)^{k}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c6ec47c32d7acc2aef7c673b9f891f26ec425c5f)













![{\displaystyle n^{*}=-{\frac {m}{k}}\ln \left[1-{\frac {X}{m}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/61a0f3398b96f0e26aa0935aba89096dcc22fc5f)

![{\displaystyle n(A^{*})=-{\frac {m}{k}}\ln \left[1-{\frac {|A|}{m}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fd27c870de822d6032469dda4b6eccf4ba4ac9eb)
![{\displaystyle n(B^{*})=-{\frac {m}{k}}\ln \left[1-{\frac {|B|}{m}}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dbcc1699bb04b9dcb909cd136210db798526bbf1)
![{\displaystyle n(A^{*}\cup B^{*})=-{\frac {m}{k}}\ln \left[1-{\frac {|A\cup B|}{m}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/af258dc11fd3f7cc5eda98e4a4d8552c3f418e48)












![{\displaystyle \left[0,n/\varepsilon \right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/08fc8018675c0d5ae415f476b94085ff896d18d4)













