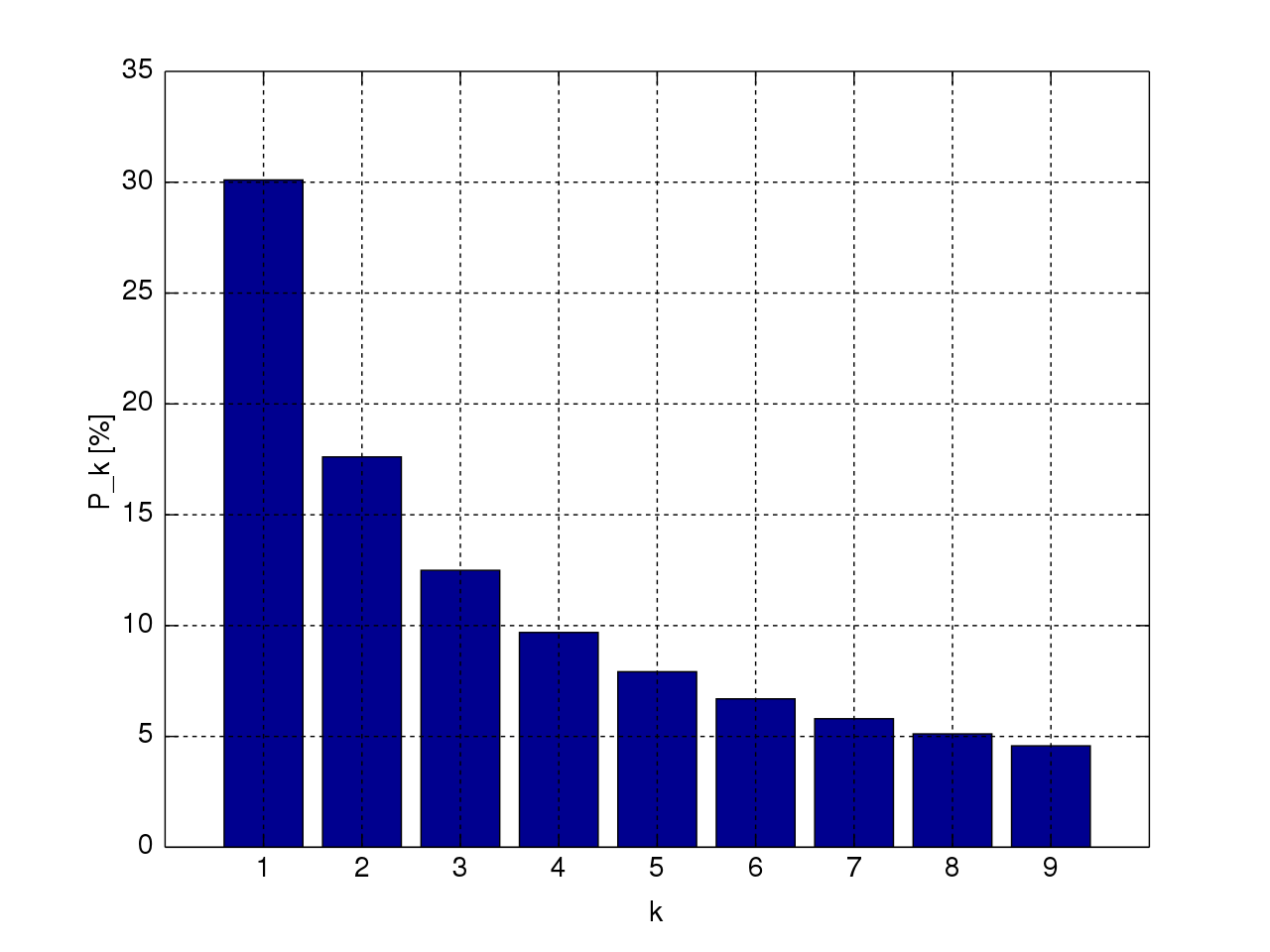

Закон Бенфорда , также известный как закон Ньюкомба-Бенфорда , закон аномальных чисел или закон первой цифры , представляет собой наблюдение о том, что во многих реальных наборах числовых данных первая цифра , вероятно, будет маленькой. [1] В наборах, подчиняющихся закону, цифра 1 появляется в качестве старшей значащей цифры примерно в 30% случаев, а 9 появляется в качестве старшей значащей цифры менее чем в 5% случаев. Если бы цифры были распределены равномерно, каждая из них встречалась бы примерно в 11,1% случаев. [2] Закон Бенфорда также делает прогнозы относительно распределения вторых и третьих цифр, комбинаций цифр и т. д.
На графике справа показан закон Бенфорда для системы счисления с основанием 10 , один из бесконечного множества случаев обобщенного закона относительно чисел, выраженных в произвольных (целых) основаниях, что исключает возможность того, что это явление может быть артефактом системы счисления с основанием 10. . Дальнейшие обобщения, опубликованные в 1995 году [3] , включали аналогичные утверждения как для n- й ведущей цифры, так и для совместного распределения первых n цифр, последнее из которых приводит к следствию, в котором показано, что значащие цифры являются статистически зависимой величиной.
Было показано, что этот результат применим к широкому спектру наборов данных, включая счета за электроэнергию, уличные адреса, цены на акции, цены на жилье, численность населения, уровень смертности, длину рек, а также физические и математические константы . [4] Как и другие общие принципы, касающиеся природных данных (например, тот факт, что многие наборы данных хорошо аппроксимируются нормальным распределением ), существуют наглядные примеры и объяснения, охватывающие многие случаи применения закона Бенфорда, хотя есть и множество других. случаи применения закона Бенфорда, которые не поддаются простому объяснению. [5] [6] Закон Бенфорда имеет тенденцию быть наиболее точным, когда значения распределены по нескольким порядкам величины , особенно если процесс генерации чисел описывается степенным законом (который распространен в природе).
Закон назван в честь физика Фрэнка Бенфорда , который сформулировал его в 1938 году в статье под названием «Закон аномальных чисел» [7] , хотя ранее он был сформулирован Саймоном Ньюкомбом в 1881 году. [8] [9]
Закон аналогичен по своей концепции, хотя и не идентичен по распространению, закону Ципфа .

Говорят, что набор чисел удовлетворяет закону Бенфорда, если старшая цифра d ( d ∈ {1,..., 9} ) встречается с вероятностью [10]
Таким образом, ведущие цифры в таком наборе имеют следующее распределение:
Величина пропорциональна промежутку между d и d + 1 в логарифмическом масштабе . Следовательно, именно такое распределение и ожидается, если логарифмы чисел (но не сами числа) распределены равномерно и случайным образом .
Например, число x , ограниченное диапазоном от 1 до 10, начинается с цифры 1, если 1 ≤ x < 2 , и начинается с цифры 9, если 9 ≤ x < 10 . Следовательно, x начинается с цифры 1, если log 1 ≤ log x < log 2 , или начинается с 9, если log 9 ≤ log x < log 10 . Интервал [log 1, log 2] намного шире интервала [log 9, log 10] (0,30 и 0,05 соответственно); поэтому, если log x распределен равномерно и случайным образом, он с гораздо большей вероятностью попадет в более широкий интервал, чем в более узкий интервал, т. е. с большей вероятностью начнется с 1, чем с 9; вероятности пропорциональны ширине интервалов, что дает приведенное выше уравнение (а также обобщение на другие основы, кроме десятичной).
Закон Бенфорда иногда формулируется в более строгой форме, утверждая, что дробная часть логарифма данных обычно близка к равномерному распределению между 0 и 1; Отсюда можно вывести основное утверждение о распределении первых цифр. [5]

Расширение закона Бенфорда предсказывает распределение первых цифр в других системах счисления , помимо десятичной ; фактически, любая база b ≥ 2 . Общая форма: [12]
Для систем счисления b = 2, 1 ( двоичная и унарная ) закон Бенфорда верен, но тривиален: все двоичные и унарные числа (за исключением 0 или пустого набора) начинаются с цифры 1. (С другой стороны, обобщение преобразования закона Бенфорда во вторую и последующие цифры нетривиальна даже для двоичных чисел. [13] )

Изучение списка высот 58 самых высоких сооружений в мире по категориям показывает, что 1, безусловно, является наиболее распространенной ведущей цифрой, независимо от единицы измерения (см. «Инвариантность масштаба» ниже):
Другой пример — старшая цифра 2 n . Последовательность первых 96 ведущих цифр (1, 2, 4, 8, 1, 3, 6, 1, 2, 5, 1, 2, 4, 8, 1, 3, 6, 1, ... (последовательность A008952 в OEIS )) демонстрирует более близкое соответствие закону Бенфорда, чем можно было бы ожидать для случайных последовательностей одинаковой длины, поскольку он получен из геометрической последовательности. [14]
Открытие закона Бенфорда относится к 1881 году, когда канадско-американский астроном Саймон Ньюкомб заметил, что в таблицах логарифмов более ранние страницы (начинающиеся с 1) изношены гораздо больше, чем остальные. [8] Опубликованный результат Ньюкомба является первым известным примером этого наблюдения и включает также распределение по второй цифре. Ньюкомб предложил закон, согласно которому вероятность того, что одно число N является первой цифрой числа, равна log( N + 1) − log( N ).
Это явление снова было отмечено в 1938 году физиком Фрэнком Бенфордом [7] , который проверил его на данных из 20 различных областей и получил за это признание. Его набор данных включал площади поверхности 335 рек, размеры 3259 популяций США, 104 физические константы , 1800 молекулярных масс , 5000 записей из математического справочника, 308 чисел, содержащихся в выпуске Reader's Digest , уличные адреса первых 342 человек, внесенных в список американских ученых , и 418 показателей смертности. Общее количество наблюдений, использованных в статье, составило 20 229. Это открытие позже было названо в честь Бенфорда (что сделало его примером закона Стиглера ).
В 1995 году Тед Хилл доказал упомянутый ниже результат о смешанных распределениях. [15] [16]
Закон Бенфорда имеет тенденцию наиболее точно применяться к данным, охватывающим несколько порядков величины . Как правило, чем больше порядков величины равномерно охватывают данные, тем точнее применяется закон Бенфорда. Например, можно ожидать, что закон Бенфорда будет применяться к списку чисел, представляющих население поселений Великобритании. Но если «поселение» определяется как деревня с населением от 300 до 999 человек, то закон Бенфорда не будет применяться. [17] [18]
Рассмотрим распределения вероятностей, показанные ниже, в логарифмическом масштабе . В каждом случае общая площадь, выделенная красным, представляет собой относительную вероятность того, что первая цифра равна 1, а общая площадь, выделенная синим, представляет собой относительную вероятность того, что первая цифра равна 8. Для первого распределения размер областей красного и синие примерно пропорциональны ширине каждой красной и синей полос. Следовательно, числа, полученные из этого распределения, будут примерно соответствовать закону Бенфорда. С другой стороны, для второго распределения соотношение площадей красного и синего цвета сильно отличается от соотношения ширин каждого красного и синего столбца. Скорее, относительные площади красного и синего цвета определяются больше высотой столбцов, чем шириной. Соответственно, первые цифры этого распределения совершенно не удовлетворяют закону Бенфорда. [18]
Таким образом, реальные распределения, охватывающие несколько порядков величины довольно равномерно (например, цены на фондовом рынке и численность населения деревень, поселков и городов), вероятно, будут очень точно удовлетворять закону Бенфорда. С другой стороны, распределение большей частью или полностью в пределах одного порядка величины (например, показателей IQ или роста взрослых людей) вряд ли будет очень точно удовлетворять закону Бенфорда, если вообще будет. [17] [18] Однако разница между применимыми и неприменимыми режимами не является резкой границей: по мере сужения распределения отклонения от закона Бенфорда постепенно увеличиваются.
(Это обсуждение не является полным объяснением закона Бенфорда, поскольку оно не объясняет, почему так часто встречаются наборы данных, которые, если их представить в виде вероятностного распределения логарифма переменной, являются относительно однородными на несколько порядков величины. [19 ] ] )
В 1970 году Вольфганг Кригер доказал то, что сейчас называется теоремой о генераторе Кригера. [20] [21] Теорему о генераторе Кригера можно рассматривать как обоснование предположения в модели шара и ящика Кафри о том, что в данной базе с фиксированным количеством цифр 0, 1, ..., n , ..., , цифра n эквивалентна ящику Кафри, содержащему n невзаимодействующих шаров. Другие ученые и статистики предложили объяснения, связанные с энтропией [ какие? ] для закона Бенфорда. [22] [23] [10] [24]
Многие реальные примеры закона Бенфорда возникают в результате мультипликативных флуктуаций. [25] Например, если цена акции начинается со 100 долларов, а затем каждый день она умножается на случайно выбранный коэффициент от 0,99 до 1,01, то в течение длительного периода распределение вероятностей ее цены будет удовлетворять закону Бенфорда со все большей и большей точностью. .
Причина в том, что логарифм цены акции претерпевает случайное блуждание , поэтому со временем его распределение вероятностей будет становиться все более широким и гладким (см. выше). [25] (С технической точки зрения центральная предельная теорема гласит, что умножение все большего и большего количества случайных величин приведет к созданию логарифмически нормального распределения с все большей и большей дисперсией, поэтому в конечном итоге оно почти равномерно покрывает многие порядки величины.) Чтобы быть уверенным в приблизительном согласии согласно закону Бенфорда распределение должно быть приблизительно инвариантным при масштабировании с любым коэффициентом до 10; набор данных с логнормально- распределенным распределением и широкой дисперсией будет обладать этим приблизительным свойством.
В отличие от мультипликативных флуктуаций, аддитивные флуктуации не приводят к закону Бенфорда: вместо этого они приводят к нормальным распределениям вероятностей (опять же по центральной предельной теореме ), которые не удовлетворяют закону Бенфорда. Напротив, описанная выше гипотетическая цена акции может быть записана как произведение многих случайных переменных (т.е. коэффициента изменения цены за каждый день), поэтому она, скорее всего , вполне соответствует закону Бенфорда.
Антон Форман предоставил альтернативное объяснение, обратив внимание на взаимосвязь между распределением значащих цифр и распределением наблюдаемой переменной . В ходе моделирования он показал, что распределения случайной величины с длинным правым хвостом совместимы с законом Ньюкомба – Бенфорда и что для распределений отношения двух случайных величин соответствие обычно улучшается. [26] Для чисел, полученных из определенных распределений ( показатель IQ , человеческий рост), закон Бенфорда не выполняется, поскольку эти переменные подчиняются нормальному распределению, которое, как известно, не удовлетворяет закону Бенфорда, [9] поскольку нормальное распределение не может охватывать несколько порядков величины, и мантиссы их логарифмов не будут (даже приблизительно) распределены равномерно. Однако если «смешать» числа из этих распределений, например, взяв числа из газетных статей, закон Бенфорда проявляется снова. Это также можно доказать математически: если неоднократно «случайно» выбирать распределение вероятностей (из некоррелированного набора), а затем случайным образом выбирать число в соответствии с этим распределением, результирующий список чисел будет подчиняться закону Бенфорда. [15] [27] Аналогичное вероятностное объяснение появления закона Бенфорда в числах повседневной жизни было выдвинуто, показав, что он возникает естественным образом, когда рассматривается смесь равномерных распределений. [28]
В списке длин распределение первых цифр чисел в списке может быть в целом одинаковым независимо от того, выражены ли все длины в метрах, ярдах, футах, дюймах и т. д. То же самое относится и к денежным единицам.
Это не всегда так. Например, рост взрослых людей почти всегда начинается с 1 или 2 при измерении в метрах и почти всегда начинается с 4, 5, 6 или 7 при измерении в футах. Но в списке длин, равномерно распределенном на многие порядки величины (например, в списке из 1000 длин, упомянутом в научных работах и включающем измерения молекул, бактерий, растений и галактик), разумно ожидать распределения первых цифр быть одинаковыми независимо от того, записаны ли длины в метрах или в футах.
Когда распределение первых цифр набора данных масштабно-инвариантно (независимо от единиц, в которых выражены данные), оно всегда определяется законом Бенфорда. [29] [30]
Например, первая (ненулевая) цифра в вышеупомянутом списке длин должна иметь одинаковое распределение независимо от того, является ли единицей измерения фут или ярд. Но в ярде три фута, поэтому вероятность того, что первая цифра длины в ярдах равна 1, должна быть такой же, как вероятность того, что первая цифра длины в футах равна 3, 4 или 5; аналогично вероятность того, что первая цифра длины в ярдах равна 2, должна быть такой же, как вероятность того, что первая цифра длины в футах равна 6, 7 или 8. Применение этого ко всем возможным масштабам измерений дает логарифмическое распределение. закона Бенфорда.
Закон Бенфорда для первых цифр является базовым инвариантом для систем счисления. Существуют условия и доказательства суммарной инвариантности, обратной инвариантности, а также инвариантности сложения и вычитания. [31] [32]
В 1972 году Хэл Вариан предположил, что закон можно использовать для выявления возможного мошенничества в списках социально-экономических данных, представляемых в поддержку решений по государственному планированию. Основываясь на правдоподобном предположении, что люди, которые выдумывают цифры, склонны распределять свои цифры довольно равномерно, простое сравнение распределения частот первых цифр по данным с ожидаемым распределением в соответствии с законом Бенфорда должно выявить любые аномальные результаты. [33]
В Соединенных Штатах доказательства, основанные на законе Бенфорда, допускались в уголовных делах на федеральном уровне, уровне штата и на местном уровне. [34]
Уолтер Мебейн , политолог и статистик из Мичиганского университета, был первым, кто применил второй значный тест закона Бенфорда (2BL-тест) в избирательной экспертизе . [35] Такой анализ считается простым, хотя и не надежным методом выявления нарушений в результатах выборов. [36] В литературе не было достигнуто научного консенсуса в поддержку применимости закона Бенфорда к выборам. В исследовании 2011 года политологов Джозефа Декерта, Михаила Мягкова и Питера К. Ордешука утверждалось, что закон Бенфорда проблематичен и вводит в заблуждение как статистический индикатор фальсификаций на выборах. [37] Их метод подвергся критике со стороны Мебане в ответ, хотя он согласился, что существует множество предостережений относительно применения закона Бенфорда к данным выборов. [38]
Закон Бенфорда был использован в качестве доказательства фальсификаций на иранских выборах 2009 года . [39] Анализ, проведенный Mebane, показал, что вторые цифры подсчета голосов за президента Махмуда Ахмадинежада , победителя выборов, имели тенденцию значительно отличаться от ожиданий закона Бенфорда, и что урны с очень небольшим количеством недействительных бюллетеней имели большую влияние на результаты, что свидетельствует о широкомасштабных вбросах бюллетеней . [40] Другое исследование использовало бутстрап -моделирование и обнаружило, что кандидат Мехди Карруби получил почти в два раза больше голосов, начиная с цифры 7, чем можно было бы ожидать в соответствии с законом Бенфорда, [41] в то время как анализ Колумбийского университета пришел к выводу, что вероятность того, что честные выборы приведут к слишком небольшому количеству несмежных цифр, а подозрительные отклонения в частоте последних цифр, обнаруженные на президентских выборах в Иране в 2009 году, составят менее 0,5 процента. [42] Закон Бенфорда также применялся для судебно-медицинской экспертизы и выявления мошенничества на данных губернаторских выборов в Калифорнии в 2003 году , [43] президентских выборов в США в 2000 и 2004 годах , [44] и федеральных выборов в Германии в 2009 году ; [45] Было обнаружено, что тест закона Бенфорда «стоит серьезно отнестись как статистический тест на мошенничество», хотя «не чувствителен к искажениям, которые, как мы знаем, существенно повлияли на многие голоса». [44] [ необходимо дальнейшее объяснение ]
Закон Бенфорда также неправильно применялся для обвинений в фальсификации выборов. При применении закона к результатам выборов Джо Байдена в Чикаго , Милуоки и других населенных пунктах на президентских выборах в США в 2020 году распределение первой цифры не соответствовало закону Бенфорда. Неправильное применение было результатом рассмотрения данных, которые были тесно связаны по диапазону, что нарушает предположение, заложенное в законе Бенфорда, о том, что диапазон данных должен быть большим. Тест первой цифры был применен к данным на уровне избирательных участков, но поскольку избирательные участки редко получают более нескольких тысяч голосов или менее нескольких десятков, нельзя ожидать, что закон Бенфорда будет применим. По словам Мебане, «широко известно, что первые цифры подсчета голосов на избирательных участках бесполезны для диагностики фальсификаций на выборах». [46] [47]
Аналогичным образом, макроэкономические данные, которые правительство Греции предоставило Европейскому Союзу перед вступлением в еврозону , оказались, вероятно, сфальсифицированными с использованием закона Бенфорда, хотя и спустя годы после вступления страны в еврозону. [48] [49]
Исследователи использовали закон Бенфорда для выявления психологических моделей ценообразования в общеевропейском исследовании цен на потребительские товары до и после введения евро в 2002 году. [50] Идея заключалась в том, что без психологического ценообразования первые две или три цифры цены количества предметов должно подчиняться закону Бенфорда. Следовательно, если распределение цифр отклоняется от закона Бенфорда (например, много девяток), это означает, что торговцы, возможно, использовали психологическое ценообразование.
Когда в 2002 году евро заменил местные валюты , на короткий период времени цены на товары в евро просто конвертировались из цен на товары в местных валютах до замены. Поскольку по существу невозможно одновременно использовать психологическое ценообразование как для цен в евро, так и для цен в местной валюте, в течение переходного периода психологическое ценообразование будет нарушено, даже если оно существовало раньше. Его можно будет восстановить только после того, как потребители снова привыкнут к ценам в единой валюте, на этот раз в евро.
Как и ожидали исследователи, распределение первой цифры цены соответствовало закону Бенфорда, но распределение второй и третьей цифр значительно отклонялось от закона Бенфорда до введения, затем отклонялось меньше во время введения, а затем снова отклонялось после введения.
Количество открытых рамок считывания и их связь с размером генома различаются у эукариот и прокариот : первые демонстрируют лог-линейную зависимость, а вторые - линейную зависимость. Закон Бенфорда использовался для проверки этого наблюдения и прекрасно соответствовал данным в обоих случаях. [51]
Проверка коэффициентов регрессии в опубликованных статьях показала согласие с законом Бенфорда. [52] В качестве группы сравнения испытуемых попросили произвести статистические оценки. Сфабрикованные результаты соответствовали закону Бенфорда о первых цифрах, но не подчинялись закону Бенфорда о вторых цифрах.
Хотя критерий хи-квадрат использовался для проверки соответствия закону Бенфорда, он имеет низкую статистическую мощность при использовании с небольшими выборками.
Критерий Колмогорова-Смирнова и тест Койпера более эффективны при небольшом размере выборки, особенно когда используется поправочный коэффициент Стивенса. [53] Эти тесты могут быть чрезмерно консервативными при применении к дискретным распределениям. Значения для теста Бенфорда были получены Морроу. [54] Критические значения статистики испытаний показаны ниже:
Эти критические значения обеспечивают минимальные значения тестовой статистики, необходимые для отклонения гипотезы о соответствии закону Бенфорда на заданных уровнях значимости .
Были опубликованы два альтернативных теста, специфичных для этого закона: во-первых, статистика max ( m ) [55] определяется выражением
В исходной формуле Леемиса ведущий фактор не фигурирует; [55] оно было добавлено Морроу в более поздней статье. [54]
Во-вторых, статистика расстояния ( d ) [56] определяется выражением
где FSD — первая значащая цифра, а N — размер выборки. Морроу определил критические значения для обеих этих статистик, которые показаны ниже: [54]
Морроу также показал, что для любой случайной величины X (с непрерывной PDF ), разделенной на ее стандартное отклонение ( σ ), можно найти некоторое значение A так, что вероятность распределения первой значащей цифры случайной величины будет отличаться от Закон Бенфорда меньше, чем ε > 0. [54] Значение A зависит от значения ε и распределения случайной величины.
Предложен метод выявления мошенничества в бухгалтерском учете, основанный на бутстрэппинге и регрессии. [57]
Если цель состоит в том, чтобы прийти к согласию с законом Бенфорда, а не к несогласию, то упомянутые выше критерии согласия не подходят. В этом случае следует применять специальные тесты на эквивалентность . Эмпирическое распределение называется эквивалентным закону Бенфорда, если расстояние (например, полное вариационное расстояние или обычное евклидово расстояние) между функциями массы вероятности достаточно мало. Этот метод проверки с применением закона Бенфорда описан у Островского. [58]
Некоторые хорошо известные бесконечные целочисленные последовательности доказуемо точно удовлетворяют закону Бенфорда (в асимптотическом пределе , когда в последовательность входит все больше и больше членов). Среди них числа Фибоначчи , [59] [60] факториалы , [ 61] степени 2, [62] [14] и степени почти любого другого числа. [62]
Аналогично, некоторые непрерывные процессы точно удовлетворяют закону Бенфорда (в асимптотическом пределе, поскольку процесс продолжается во времени). Одним из них является процесс экспоненциального роста или убывания : если величина экспоненциально увеличивается или уменьшается во времени, то процент времени, в течение которого она имеет каждую первую цифру, асимптотически удовлетворяет закону Бенфорда (т.е. точность увеличивается по мере продолжения процесса во времени).
Квадратные корни и обратные величины последовательных натуральных чисел не подчиняются этому закону. [63] Простые числа в конечном диапазоне подчиняются обобщенному закону Бенфорда, который приближается к единообразию по мере того, как размер диапазона приближается к бесконечности. [64] Списки местных телефонных номеров нарушают закон Бенфорда. [65] Закон Бенфорда нарушается населением всех населенных пунктов с численностью не менее 2500 особей из пяти штатов США по переписям 1960 и 1970 годов, где только 19 % начиналось с цифры 1, а 20 % начиналось с цифры 2, поскольку усечение на уровне 2500 вносит статистическую погрешность. [63] Конечные цифры в отчетах о патологии нарушают закон Бенфорда из-за округления. [66]
Распределения, не охватывающие несколько порядков, не подчиняются закону Бенфорда. Примеры включают рост, вес и показатели IQ. [9] [67]
Был предложен ряд критериев, применимых, в частности, к данным бухгалтерского учета, в которых можно ожидать применения закона Бенфорда. [68]
С математической точки зрения закон Бенфорда применяется, если проверяемое распределение соответствует «теореме о соответствии закону Бенфорда». [17] Вывод говорит, что закон Бенфорда соблюдается, если преобразование Фурье логарифма функции плотности вероятности равно нулю для всех целых значений. В частности, это выполняется, если преобразование Фурье равно нулю (или незначительно) при n ≥ 1. Это выполняется, если распределение широкое (поскольку широкое распределение подразумевает узкое преобразование Фурье). Смит резюмирует так (стр. 716):
Закону Бенфорда соответствуют распределения, широкие по сравнению с единичным расстоянием в логарифмическом масштабе. Точно так же закону не подчиняются распределения, узкие по сравнению с единичным расстоянием… Если распределение широкое по сравнению с единичным расстоянием на логарифмической оси, это означает, что разброс в наборе рассматриваемых чисел намного больше десяти.
Короче говоря, закон Бенфорда требует, чтобы числа в измеряемом распределении имели разброс по крайней мере на порядок величины.
Закон Бенфорда был эмпирически проверен на числах (до 10-го знака), порождаемых рядом важных распределений, включая равномерное распределение , экспоненциальное распределение , нормальное распределение и другие. [9]
Равномерное распределение, как и следовало ожидать, не подчиняется закону Бенфорда. Напротив, распределение отношений двух равномерных распределений хорошо описывается законом Бенфорда.
Ни нормальное распределение, ни распределение отношений двух нормальных распределений ( распределение Коши ) не подчиняются закону Бенфорда. Хотя полунормальное распределение не подчиняется закону Бенфорда, соотношение отношений двух полунормальных распределений подчиняется. Ни усеченное вправо нормальное распределение, ни распределение отношений двух усеченных вправо нормальных распределений не могут быть хорошо описаны законом Бенфорда. Это неудивительно, поскольку это распределение ориентировано на большие числа.
Закон Бенфорда также хорошо описывает экспоненциальное распределение и распределение отношений двух экспоненциальных распределений. Подбор распределения хи-квадрат зависит от степеней свободы (df) с хорошим согласием при df = 1 и уменьшением согласия по мере увеличения df. F - распределение хорошо подходит для низких степеней свободы. С увеличением dfs соответствие уменьшается, но гораздо медленнее, чем распределение хи-квадрат. Подбор логарифмически нормального распределения зависит от среднего значения и дисперсии распределения. Дисперсия оказывает гораздо большее влияние на соответствие, чем среднее значение. Большие значения обоих параметров приводят к лучшему согласию с законом. Отношение двух логнормальных распределений является логарифмически нормальным, поэтому это распределение не исследовалось.
Другие распределения, которые были исследованы, включают распределение Мута, распределение Гомпертца , распределение Вейбулла , гамма-распределение , логарифмическое логистическое распределение и экспоненциальное степенное распределение , все из которых демонстрируют разумное согласие с законом. [55] [69] Распределение Гамбеля – плотность увеличивается с увеличением значения случайной величины – не согласуется с этим законом. [69]
Можно распространить закон на цифры, выходящие за пределы первой. [70] В частности, для любого заданного количества цифр вероятность встретить число, начинающееся со строки цифр n такой длины – без учета ведущих нулей – определяется выражением
Таким образом, вероятность того, что число начинается с цифр 3, 1, 4 (некоторые примеры: 3,14, 3,142, π , 314280,7 и 0,00314005), равна log 10 (1 + 1/314) ≈ 0,00138 , как в блоке с лог-логарифм справа.
Этот результат можно использовать для определения вероятности того, что определенная цифра встречается в заданной позиции числа. Например, вероятность того, что в качестве второй цифры встретится цифра «2», равна [70]
А вероятность того, что d ( d = 0, 1, ..., 9) встретится в качестве n -й ( n > 1) цифры, равна
Распределение n -й цифры по мере увеличения n быстро приближается к равномерному распределению с 10% для каждой из десяти цифр, как показано ниже. [70] Четырех цифр часто достаточно, чтобы предположить равномерное распределение 10%, поскольку «0» появляется в 10,0176% случаев в четвертой цифре, а «9» появляется в 9,9824% случаев.
По этому закону были рассчитаны средние значения и моменты случайных величин для цифр от 1 до 9: [71]
Для двузначного распределения по закону Бенфорда также известны эти значения: [72]
Доступна таблица точных вероятностей совместного появления первых двух цифр в соответствии с законом Бенфорда [72] , а также популяционная корреляция между первой и второй цифрами: [72] ρ = 0,0561 .
Закон Бенфорда появился как сюжетный ход в некоторых популярных развлечениях двадцать первого века.
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка )






![{\displaystyle d={\sqrt {N\cdot \sum _{l=1}^{9}\left[\Pr \left(X{\text{имеет FSD}}=l\right)-\log _ {10}\left(1+{\frac {1}{l}}\right)\right]^{2}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f058284420d7cfcc8672bb7945f2c17a77c15f1)



