Статистическая методика
Сглаживание ядра — это статистический метод оценки действительнозначной функции как средневзвешенного значения соседних наблюдаемых данных. Вес определяется ядром , так что более близким точкам присваиваются более высокие веса. Оцениваемая функция является гладкой, а уровень гладкости задается одним параметром. Ядерное сглаживание — это тип взвешенной скользящей средней .
Определения
Пусть – ядро, определенное формулой
где:
- это евклидова норма
- это параметр (радиус ядра)
- D ( t ) обычно является положительной вещественной функцией, значение которой уменьшается (или не увеличивается) с увеличением расстояния между X и X0 .
Популярные ядра, используемые для сглаживания, включают параболическое ядро (Епанечникова), трехкубическое и гауссовское .
Пусть – непрерывная функция от X . Для каждого средневзвешенное по ядру Надарая-Ватсона (гладкая оценка Y ( X )) определяется выражением
где:
- N — количество наблюдаемых точек
- Y ( X i ) — наблюдения в точках X i .
В следующих разделах мы опишем некоторые частные случаи сглаживателей ядра.
Гауссово ядро более гладкое
Ядро Гаусса является одним из наиболее широко используемых ядер и выражается уравнением, приведенным ниже.
Здесь b — масштаб входного пространства.
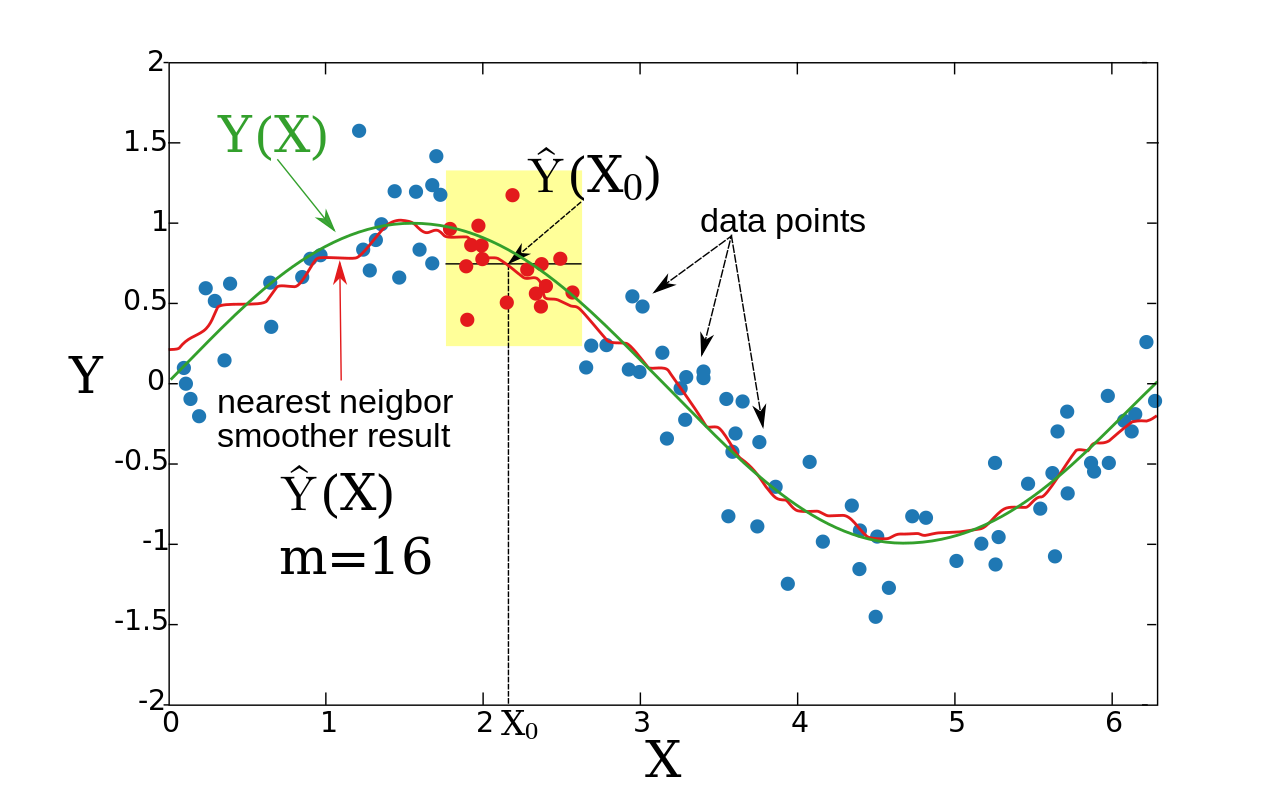
Ближайший сосед более плавный
Идея сглаживания ближайшего соседа заключается в следующем. Для каждой точки X 0 возьмите m ближайших соседей и оцените значение Y ( X 0 ) путем усреднения значений этих соседей.
Формально , где – m -й ближайший к X 0 сосед, а
Пример:
В этом примере X является одномерным. Для каждого X 0 это среднее значение, равное 16 ближайшим к X 0 точкам (обозначено красным).
Ядро в среднем более плавное
Идея сглаживания среднего ядра заключается в следующем. Для каждой точки данных X 0 выберите постоянный размер расстояния λ (радиус ядра или ширину окна для измерения p = 1) и вычислите средневзвешенное значение для всех точек данных, которые ближе, чем к X 0 (чем ближе к X 0 точки получить больший вес).
Формально и D ( t ) — одно из популярных ядер.
Пример:
Для каждого X 0 ширина окна постоянна, а вес каждой точки окна схематически обозначен желтой цифрой на графике. Видно, что оценка гладкая, но граничные точки смещены. Причиной тому является неодинаковое количество точек (справа и слева от X 0 ) в окне, когда X 0 находится достаточно близко к границе.
Локальная линейная регрессия
В двух предыдущих разделах мы предполагали, что базовая функция Y(X) является локально постоянной, поэтому мы смогли использовать для оценки средневзвешенное значение. Идея локальной линейной регрессии состоит в том, чтобы локально соответствовать прямой линии (или гиперплоскости для более высоких измерений), а не константе (горизонтальной линии). После подгонки линии оценка осуществляется по значению этой линии в точке X 0 . Повторив эту процедуру для каждого X0 , можно получить оценочную функцию . Как и в предыдущем разделе, ширина окна постоянна.
Формально локальная линейная регрессия вычисляется путем решения взвешенной задачи наименьших квадратов.
Для одного измерения ( p = 1):
Решение в закрытой форме определяется следующим образом:
где:
Пример:
Полученная функция является гладкой, и проблема со смещенными граничными точками уменьшается.
Локальную линейную регрессию можно применять к любому размерному пространству, хотя вопрос о том, что такое локальная окрестность, становится более сложным. Обычно используется k ближайших точек обучения к контрольной точке, чтобы соответствовать локальной линейной регрессии. Это может привести к высокой дисперсии подобранной функции. Чтобы ограничить дисперсию, набор обучающих точек должен содержать тестовую точку в своей выпуклой оболочке (см. ссылку Гупта и др.).
Локальная полиномиальная регрессия
Вместо подгонки локально линейных функций можно подогнать полиномиальные функции.
При p=1 следует минимизировать:
с
В общем случае (p>1) следует минимизировать:
Смотрите также
Рекомендации
- Ли, К. и Дж. С. Расин. Непараметрическая эконометрика: теория и практика . Издательство Принстонского университета, 2007, ISBN 0-691-12161-3 .
- Т. Хасти, Р. Тибширани и Дж. Фридман, «Элементы статистического обучения» , глава 6, Springer, 2001. ISBN 0-387-95284-5 (сайт сопутствующей книги).
- М. Гупта, Э. Гарсия и Э. Чин, «Адаптивная локальная линейная регрессия с применением к управлению цветом принтера», IEEE Trans. Обработка изображений 2008.












![{\displaystyle h_{m}(X_{0})=\left\|X_{0}-X_{[m]}\right\|}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e649a2d186d0ff66a1aa6c00792a3f263293049d)
![{\displaystyle X_{[м]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c375afa1c3ce963071818546bfa67b2b846585ee)













