В информатике список пропуска (или список пропуска ) — это вероятностная структура данных , обеспечивающая среднюю сложность поиска, а также среднюю сложность вставки в упорядоченную последовательность элементов . Таким образом, он может получить лучшие возможности отсортированного массива (для поиска), сохраняя при этом структуру, подобную связанному списку , которая позволяет вставку, что невозможно для статического массива. Быстрый поиск становится возможным благодаря поддержанию связанной иерархии подпоследовательностей, при которой каждая последующая подпоследовательность пропускает меньше элементов, чем предыдущая (см. рисунок ниже справа). Поиск начинается с самой разреженной подпоследовательности, пока не будут найдены два последовательных элемента: один меньшего размера, а другой больше или равен искомому элементу. Через связанную иерархию эти два элемента связаны с элементами следующей самой разреженной подпоследовательности, где поиск продолжается до тех пор, пока, наконец, не будет выполнен поиск в полной последовательности. Пропущенные элементы могут выбираться вероятностно [2] или детерминированно, [3] причем первый вариант встречается чаще.
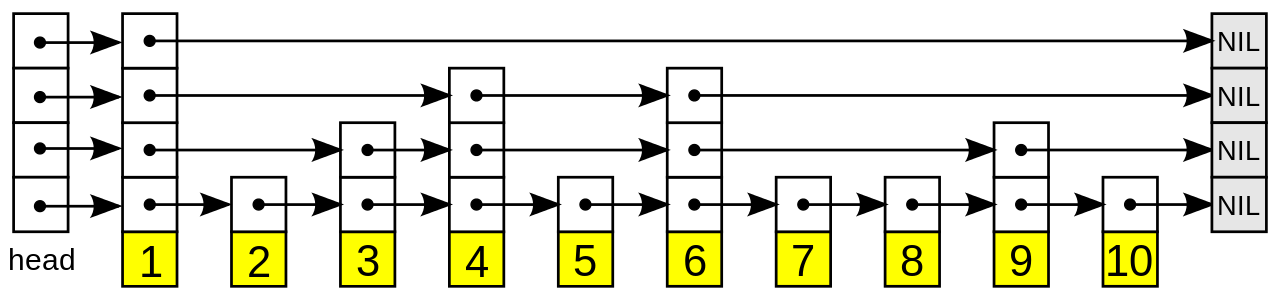
Список пропуска состоит из слоев. Нижний слой представляет собой обычный упорядоченный связанный список . Каждый более высокий уровень действует как «экспресс-полоса» для приведенных ниже списков, где элемент слоя появляется в слое с некоторой фиксированной вероятностью (два часто используемых значения: или ) . В среднем каждый элемент появляется в списках, а самый высокий элемент (обычно специальный элемент заголовка в начале списка пропуска) появляется во всех списках. Список пропуска содержит списки (т.е. по логарифмическому основанию ) .
Поиск целевого элемента начинается с главного элемента в верхнем списке и продолжается по горизонтали до тех пор, пока текущий элемент не станет больше или равен целевому. Если текущий элемент равен целевому, он найден. Если текущий элемент больше целевого или поиск достигает конца связанного списка, процедура повторяется после возврата к предыдущему элементу и перехода по вертикали к следующему нижнему списку. Ожидаемое количество шагов в каждом связанном списке не превышает , что можно увидеть, проследив путь поиска в обратном направлении от цели до достижения элемента, который появляется в следующем более высоком списке, или до достижения начала текущего списка. Следовательно, общая ожидаемая стоимость поиска равна , когда – константа. Выбирая разные значения , можно сбалансировать затраты на поиск и затраты на хранение.

Элементы, используемые для списка пропуска, могут содержать более одного указателя, поскольку они могут участвовать более чем в одном списке.
Вставки и удаления реализованы так же, как соответствующие операции со связанным списком, за исключением того, что «длинные» элементы должны быть вставлены или удалены из более чем одного связанного списка.
операции, которые заставляют нас посещать каждый узел в порядке возрастания (например, печать всего списка), дают возможность выполнить закулисную дерандомизацию структуры уровней списка пропуска оптимальным образом, приводя пропуск список времени поиска. (Выберите уровень i-го конечного узла равным 1 плюс количество раз, которое можно многократно разделить i на 2, прежде чем оно станет нечетным. Кроме того, i = 0 для заголовка отрицательной бесконечности, поскольку это обычный особый случай. выбора максимально возможного уровня для отрицательных и/или положительных бесконечных узлов.) Однако это также позволяет кому-то узнать, где находятся все узлы выше уровня 1, и удалить их.
В качестве альтернативы структуру уровней можно сделать квазислучайной следующим образом:
сделать все узлы уровня 1й ← 1в то время как количество узлов на уровне j > 1 делать для каждого i-го узла на уровне j делать, если я нечетный и я не последний узел на уровне j случайным образом выбрать, повышать ли его до уровня j+1 иначе, если я четный и узел i-1 не был повышен продвинуть его до уровня j+1 конец, если повторить j ← j + 1повторить
Как и дерандомизированная версия, квазирандомизация выполняется только тогда, когда есть какая-то другая причина для запуска операции (которая посещает каждый узел).
Преимущество этой квазислучайности состоит в том, что она не дает состязательному пользователю почти столько же информации, связанной со структурой уровней , как дерандомизированный пользователь. Это желательно, поскольку состязательный пользователь, который может определить, какие узлы не находятся на самом низком уровне, может ухудшить производительность, просто удалив узлы более высокого уровня. (Однако Бетеа и Райтер утверждают, что, тем не менее, злоумышленник может использовать вероятностные и временные методы, чтобы вызвать ухудшение производительности. [4] ). Производительность поиска по-прежнему гарантированно будет логарифмической.
Было бы заманчиво провести следующую «оптимизацию»: в части, где говорится «Далее, для каждого i -го...», забудьте о подбрасывании монеты для каждой четно-нечетной пары. Просто подбросьте монетку один раз, чтобы решить, продвигать ли только четные или только нечетные. Вместо подбрасывания монеты будут только они. К сожалению, это дает состязательному пользователю вероятность 50/50 оказаться правым, если он догадается, что все узлы с четными номерами (среди узлов уровня 1 или выше) выше первого уровня. И это несмотря на то, что существует очень низкая вероятность угадать, что конкретный узел находится на уровне N для некоторого целого числа N.
Список пропуска не обеспечивает таких же абсолютных гарантий производительности в наихудшем случае, как более традиционные сбалансированные древовидные структуры данных, поскольку всегда возможно (хотя и с очень низкой вероятностью [5] ), что подбрасывание монеты, использованное для построения списка пропуска, приведет к плохо сбалансированная структура. Однако на практике они хорошо работают, и утверждается, что схему рандомизированной балансировки легче реализовать, чем детерминированные схемы балансировки, используемые в сбалансированных двоичных деревьях поиска. Списки пропуска также полезны при параллельных вычислениях , где вставки могут выполняться в разных частях списка пропуска параллельно без какой-либо глобальной перебалансировки структуры данных. Такой параллелизм может быть особенно выгоден для обнаружения ресурсов в специальной беспроводной сети, поскольку рандомизированный список пропуска можно сделать устойчивым к потере любого отдельного узла. [6]
Как описано выше, список пропуска позволяет быстро вставлять и удалять значения из отсортированной последовательности, но он обеспечивает только медленный поиск значений в заданной позиции в последовательности (т. е. возвращает 500-е значение); однако с незначительной модификацией скорость индексированного поиска с произвольным доступом можно повысить до .
Для каждой ссылки также сохраните ширину ссылки. Ширина определяется как количество звеньев нижнего уровня, через которые проходит каждое из звеньев «экспресс-полосы» более высокого уровня.
Например, вот ширина ссылок в примере вверху страницы:
1 10 о---> о-------------------------------------------- -------------> o Верхний уровень 1 3 2 5 о---> о---------------> о---------> о---------------- -----------> o Уровень 3 1 2 1 2 3 2 о---> о---------> о---> о---------> о---------------> о ---------> o Уровень 2 1 1 1 1 1 1 1 1 1 1 1 о---> о---> о---> о---> о---> о---> о---> о---> о---> о---> o---> o Нижний уровеньРуководитель 1-й 2-й 3-й 4-й 5-й 6-й 7-й 8-й 9-й 10-й НОЛЬ Узел Узел Узел Узел Узел Узел Узел Узел Узел
Обратите внимание, что ширина ссылки более высокого уровня представляет собой сумму компонентных ссылок ниже нее (т. е. ссылка шириной 10 охватывает ссылки шириной 3, 2 и 5 непосредственно под ней). Следовательно, сумма всех ширин одинакова на каждом уровне (10 + 1 = 1 + 3 + 2 + 5 = 1 + 2 + 1 + 2 + 3 + 2).
Чтобы проиндексировать список пропуска и найти i-е значение, пройдите по списку пропуска, отсчитывая ширину каждой пройденной ссылки. Спускайтесь на уровень всякий раз, когда предстоящая ширина будет слишком большой.
Например, чтобы найти узел в пятой позиции (Узел 5), пройдите по ссылке шириной 1 на верхнем уровне. Теперь нужно еще четыре шага, но следующая ширина на этом уровне равна десяти, что слишком велико, поэтому опустите один уровень. Пройдите одно звено шириной 3. Поскольку еще одна ступень шириной 2 будет слишком далеко, спуститесь на нижний уровень. Теперь пройдите последнее звено шириной 1, чтобы достичь целевой промежуточной суммы 5 (1+3+1).
функция поискаByPositionIndex(i) узел ← голова i ← i + 1 # не считать голову шагом для уровня сверху вниз do while i ≥ node.width[level] do # если следующий шаг не слишком далеко i ← i - node.width[level] # вычитаем текущую ширину узла ← node.next[level] # переход вперед на текущий уровень
Этот метод реализации индексирования подробно описан в «Кулинарной книге списка пропуска» Уильяма Пью [7].
Списки пропуска были впервые описаны в 1989 году Уильямом Пью . [8]
Цитирую автора:
Списки пропуска представляют собой вероятностную структуру данных, которая, похоже, заменит сбалансированные деревья в качестве предпочтительного метода реализации для многих приложений. Алгоритмы списков пропуска имеют те же асимптотические границы ожидаемого времени, что и сбалансированные деревья, и они проще, быстрее и занимают меньше места.
- Уильям Пью, Одновременное ведение списков пропуска (1989)
Список приложений и фреймворков, использующих списки пропуска:
Списки пропуска также используются в распределенных приложениях (где узлы представляют собой физические компьютеры, а указатели представляют собой сетевые соединения) и для реализации высокомасштабируемых параллельных очередей с приоритетами с меньшим количеством конфликтов за блокировки, [17] или даже без блокировки , [18] [19] [ 20] , а также параллельные словари без блокировки . [21] Существует также несколько патентов США на использование списков пропуска для реализации (безблокировочных) приоритетных очередей и параллельных словарей. [22]














