При поиске информации tf-idf (также TF*IDF , TFIDF , TF-IDF или Tf-idf ), сокращение от термина частота – обратная частота документа , является мерой важности слова для документа в коллекции или корпусе . , с поправкой на то, что некоторые слова в целом встречаются чаще. [1] Его часто использовали в качестве весового коэффициента при поиске информации, интеллектуальном анализе текста и моделировании пользователей . Опрос, проведенный в 2015 году, показал, что 83% текстовых рекомендательных систем в электронных библиотеках используют tf–idf. [2]
Одна из простейших функций ранжирования вычисляется путем суммирования tf–idf для каждого термина запроса; многие более сложные функции ранжирования являются вариантами этой простой модели.
Мотивации
Карен Сперк Джонс (1972) предложила статистическую интерпретацию специфичности термина под названием «Обратная частота документов» (idf), которая стала краеугольным камнем взвешивания терминов: [3]
Специфика термина может быть определена количественно как обратная функция количества документов, в которых он встречается.
Например, df (частота документа) и idf для некоторых слов в 37 пьесах Шекспира таковы: [4]
Мы видим, что « Ромео », « Фальстаф » и «Салат» появляются в очень немногих пьесах, поэтому, увидев эти слова, можно получить хорошее представление о том, какая это может быть пьеса. Напротив, слова «хороший» и «милый» появляются в каждой пьесе и совершенно неинформативны относительно того, какая это пьеса.
Определение
Tf–idf — это произведение двух статистических данных: частоты терминов и обратной частоты документов . Существуют различные способы определения точных значений обеих статистических данных.
Формула, целью которой является определение важности ключевого слова или фразы в документе или веб-странице.
Периодичность термина
Частота термина tf( t , d ) — это относительная частота термина t в документе d ,
,
где f t , d — исходное количество терминов в документе, т. е. количество раз, когда термин t встречается в документе d . Обратите внимание, что знаменатель — это просто общее количество терминов в документе d (с учетом каждого появления одного и того же термина отдельно). Существуют и другие способы определения частоты термина: [5] : 128
сам необработанный подсчет: tf( t , d ) = f t , d
Булевы «частоты»: tf( t , d ) = 1 , если t встречается в d , и 0 в противном случае;
увеличенная частота, чтобы предотвратить смещение в сторону более длинных документов, например, необработанная частота, деленная на необработанную частоту наиболее часто встречающегося термина в документе:
Обратная частота документов
Обратная частота документов — это мера того, сколько информации содержит слово, т. е. является ли оно обычным или редким во всех документах. Это логарифмическая обратная доля документов, содержащих это слово (полученная путем деления общего количества документов на количество документов, содержащих этот термин, а затем логарифмирования этого частного):
с
: общее количество документов в корпусе
: количество документов, в которых встречается этот термин (т. е. ). Если термина нет в корпусе, это приведет к делению на ноль. Поэтому принято приводить числитель и знаменатель к .
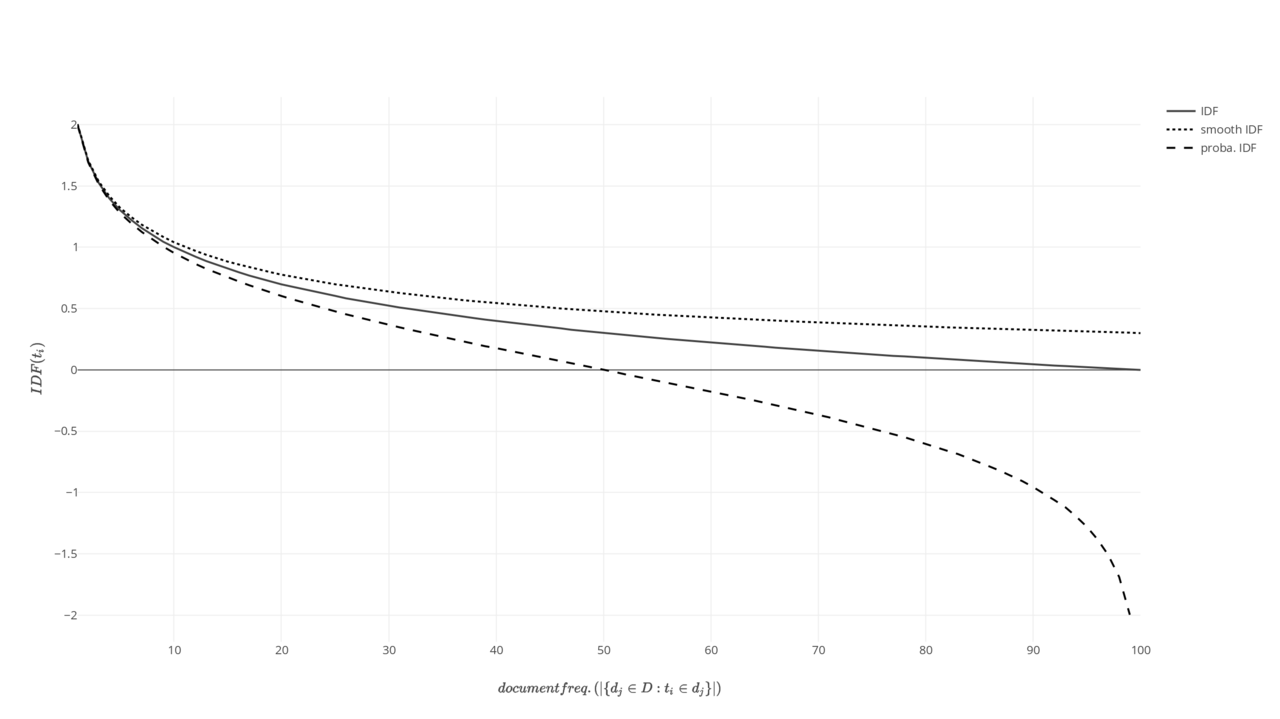
График различных обратных функций частоты документов: стандартный, гладкий, вероятностный.
Частота термина – обратная частота документов.
Тогда tf–idf рассчитывается как
Высокий вес в tf–idf достигается за счет высокой частотности термина (в данном документе) и низкой документальной частотности термина во всей совокупности документов; следовательно, веса имеют тенденцию отфильтровывать общие термины. Поскольку соотношение внутри функции журнала idf всегда больше или равно 1, значение idf (и tf – idf) больше или равно 0. По мере того, как термин появляется в большем количестве документов, соотношение внутри логарифма приближается к 1. , приближая IDF и tf–idf к 0.
Обоснование ИДФ
Idf был введен Карен Сперк Джонс как «специфичность термина» в статье 1972 года. Хотя она хорошо сработала как эвристика , ее теоретические основы вызывали затруднения в течение как минимум трех десятилетий после этого, и многие исследователи пытались найти для нее теоретические обоснования. [7]
Собственное объяснение Сперка Джонса не содержало особой теории, за исключением связи с законом Ципфа . [7] Были предприняты попытки поставить idf на вероятностную основу, [8] путем оценки вероятности того, что данный документ d содержит термин t , как относительная частота документов,
чтобы мы могли определить IDF как
А именно, обратная частота документов представляет собой логарифм «обратной» относительной частоты документов.
Эта вероятностная интерпретация, в свою очередь, принимает ту же форму, что и самоинформация . Однако применение таких теоретико-информационных понятий к задачам поиска информации приводит к проблемам при попытке определить соответствующие пространства событий для требуемых распределений вероятностей : необходимо учитывать не только документы, но также запросы и термины. [7]
Связь с теорией информации
Как частота терминов, так и обратная частота документов могут быть сформулированы в терминах теории информации ; это помогает понять, почему их продукт имеет значение с точки зрения общего информационного наполнения документа. Характерное предположение о распределении состоит в том, что:
По словам Айзавы, это предположение и его последствия: «представляют собой эвристику, которую использует tf–idf». [9]
Условная энтропия «случайно выбранного» документа в корпусе при условии, что он содержит определенный термин (и при условии, что все документы имеют равную вероятность быть выбранными):
С точки зрения обозначений, и являются «случайными величинами», соответствующими соответственно рисованию документа или термина. Взаимную информацию можно выразить как
Последний шаг — расширить безусловную вероятность нарисовать термин относительно (случайного) выбора документа, чтобы получить:
Это выражение показывает, что суммирование Tf–idf всех возможных терминов и документов восстанавливает взаимную информацию между документами и термином с учетом всех особенностей их совместного распространения. [9] Таким образом, каждый Tf–idf несет «бит информации», прикрепленный к паре термин x документ.
Пример tf–idf
Предположим, что у нас есть таблицы подсчета терминов корпуса, состоящего только из двух документов, как указано справа.
Расчет tf–idf для терма «это» выполняется следующим образом:
В своей необработанной частотной форме tf — это просто частота «это» для каждого документа. В каждом документе слово «это» встречается один раз; но поскольку в документе 2 больше слов, его относительная частота меньше.
IDF является постоянным для каждого корпуса и учитывает долю документов, содержащих слово «это». В данном случае у нас есть корпус из двух документов, и все они содержат слово «это».
Таким образом, tf–idf для слова «this» равен нулю, что означает, что это слово не очень информативно, как оно встречается во всех документах.
Слово «пример» более интересно — оно встречается трижды, но только во втором документе:
Идея tf-idf применима и к сущностям, отличным от терминов. В 1998 году к цитированию была применена концепция IDF. [10] Авторы утверждают, что «если очень необычная цитата является общей для двух документов, ей следует придавать более высокий вес, чем цитате, сделанной в большом количестве документов». Кроме того, tf–idf применялся к «визуальным словам» с целью проведения сопоставления объектов в видео, [11] и целых предложениях. [12] Однако концепция tf–idf не во всех случаях оказалась более эффективной, чем простая схема tf (без idf). Когда tf-idf был применен к цитированию, исследователи не смогли найти никаких улучшений по сравнению с простым весом подсчета цитирований, который не имел компонента idf. [13]
Производные
Ряд схем взвешивания терминов основан на tf–idf. Один из них — TF–PDF (частота термина * пропорциональная частота документов). [14] TF-PDF был представлен в 2001 году в контексте выявления новых тем в средствах массовой информации. Компонент PDF измеряет разницу в том, как часто термин встречается в разных доменах. Другое производное — TF–IDuF. В TF–IDuF [15] idf не рассчитывается на основе корпуса документов, который необходимо найти или рекомендовать. Вместо этого IDF рассчитывается на основе коллекций личных документов пользователей. Авторы сообщают, что TF-IDuF был столь же эффективен, как и tf-idf, но также мог применяться в ситуациях, когда, например, система моделирования пользователей не имеет доступа к глобальному корпусу документов.
^ Раджараман, А.; Ульман, JD (2011). «Интеллектуальный анализ данных» (PDF) . Интеллектуальный анализ массивных наборов данных . стр. 1–17. дои : 10.1017/CBO9781139058452.002. ISBN 978-1-139-05845-2.
^ Брайтингер, Коринна; Гипп, Бела; Лангер, Стефан (26 июля 2015 г.). «Системы рекомендаций научных работ: обзор литературы». Международный журнал цифровых библиотек . 17 (4): 305–338. дои : 10.1007/s00799-015-0156-0. ISSN 1432-5012. S2CID 207035184.
^ Сперк Джонс, К. (1972). «Статистическая интерпретация специфичности термина и ее применение в поиске». Журнал документации . 28 (1): 11–21. CiteSeerX 10.1.1.115.8343 . дои : 10.1108/eb026526. S2CID 2996187.
^ Обработка речи и языка (3-е изд. Черновик), Дэн Джурафски и Джеймс Х. Мартин, глава 14. https://web.stanford.edu/~jurafsky/slp3/14.pdf
^ Мэннинг, CD; Рагхаван, П.; Шутце, Х. (2008). «Оценка, взвешивание терминов и модель векторного пространства» (PDF) . Введение в поиск информации . п. 100. дои : 10.1017/CBO9780511809071.007. ISBN978-0-511-80907-1.
^ «Статистика TFIDF | SAX-VSM» .
^ abc Робертсон, С. (2004). «Понимание обратной частоты документов: теоретические аргументы в пользу IDF». Журнал документации . 60 (5): 503–520. дои : 10.1108/00220410410560582.
^ См. также «Оценки вероятности на практике» в разделе «Введение в поиск информации» .
^ Аб Айзава, Акико (2003). «Теоретико-информационный взгляд на меры TF – IDF». Обработка информации и управление . 39 (1): 45–65. дои : 10.1016/S0306-4573(02)00021-3. S2CID 45793141.
^ Боллакер, Курт Д.; Лоуренс, Стив; Джайлз, К. Ли (1 января 1998 г.). «ЦитеСир». Материалы второй международной конференции по автономным агентам-АГЕНТЫ'98 . стр. 116–123. дои : 10.1145/280765.280786. ISBN978-0-89791-983-8. S2CID 3526393.
^ Сивич, Йозеф; Зиссерман, Эндрю (1 января 2003 г.). «Видео Google: подход к поиску текста для сопоставления объектов в видео». Материалы девятой международной конференции IEEE по компьютерному зрению. ICCV '03. стр. 1470–. дои : 10.1109/ICCV.2003.1238663. ISBN978-0-7695-1950-0. S2CID 14457153.
^ Секи, Йохей. «Извлечение предложений с помощью tf/idf и взвешивание позиций из газетных статей» (PDF) . Национальный институт информатики.
^ Бил, Джоран; Брайтингер, Коринна (2017). «Оценка схемы взвешивания цитирования CC-IDF – насколько эффективно можно применять «обратную частоту документов» (IDF) к ссылкам?» (PDF) . Материалы 12-й конференции . Архивировано из оригинала (PDF) 22 сентября 2020 г. Проверено 29 января 2017 г.
^ Ху Кхё Бун; Бун, Кху Хё; Исидзука, М. (2001). «Новая система отслеживания тем». Материалы третьего международного семинара по перспективным проблемам электронной коммерции и информационных веб-систем. ВЕКВИС 2001 . стр. 2–11. CiteSeerX 10.1.1.16.7986 . doi : 10.1109/wecwis.2001.933900. ISBN978-0-7695-1224-2. S2CID 1049263.
^ Лангер, Стефан; Гипп, Бела (2017). «TF-IDuF: новая схема взвешивания терминов для моделирования пользователей на основе коллекций личных документов пользователей» (PDF) . IКонференция .
Генератор текста в матрицу (TMG) Набор инструментов MATLAB, который можно использовать для различных задач интеллектуального анализа текста (TM), в частности i) индексации, ii) поиска, iii) уменьшения размерности, iv) кластеризации, v) классификации. Шаг индексирования предлагает пользователю возможность применять локальные и глобальные методы взвешивания, включая tf-idf.