В дополнение к выполнению линейной классификации , SVM могут эффективно выполнять нелинейную классификацию, используя так называемый трюк ядра , представляя данные только через набор попарных сравнений сходства между исходными точками данных с использованием функции ядра, которая преобразует их в координаты в пространстве признаков более высокой размерности . Таким образом, SVM используют трюк ядра для неявного отображения своих входных данных в пространства признаков более высокой размерности, где может быть выполнена линейная классификация. [3] Будучи моделями с максимальным запасом, SVM устойчивы к зашумленным данным (например, неправильно классифицированным примерам). SVM также могут использоваться для задач регрессии , где цель становится -чувствительной.
Алгоритм опорных векторных кластеров [4] , созданный Хавой Зигельманн и Владимиром Вапником , применяет статистику опорных векторов, разработанную в алгоритме опорных векторных машин, для категоризации немаркированных данных. [ необходима ссылка ] Эти наборы данных требуют подходов неконтролируемого обучения , которые пытаются найти естественную кластеризацию данных в группы, а затем сопоставить новые данные в соответствии с этими кластерами.
H 1 не разделяет классы. H 2 разделяет, но с небольшим отрывом. H 3 разделяет их с максимальным отрывом.
Классификация данных является распространенной задачей в машинном обучении . Предположим, что некоторые заданные точки данных принадлежат к одному из двух классов, и цель состоит в том, чтобы решить, к какому классу будет относиться новая точка данных . В случае опорных векторных машин точка данных рассматривается как -мерный вектор (список чисел), и мы хотим знать, можем ли мы разделить такие точки -мерной гиперплоскостью . Это называется линейным классификатором . Существует много гиперплоскостей, которые могут классифицировать данные. Одним из разумных выборов в качестве лучшей гиперплоскости является та, которая представляет наибольшее разделение, или границу , между двумя классами. Поэтому мы выбираем гиперплоскость так, чтобы расстояние от нее до ближайшей точки данных с каждой стороны было максимальным. Если такая гиперплоскость существует, она известна как гиперплоскость с максимальным пределом , а линейный классификатор, который она определяет, известен как классификатор с максимальным пределом ; или, что эквивалентно, персептрон оптимальной устойчивости . [ необходима цитата ]
Более формально, машина опорных векторов строит гиперплоскость или набор гиперплоскостей в пространстве с высокой или бесконечной размерностью, которые могут использоваться для классификации , регрессии или других задач, таких как обнаружение выбросов. [5] Интуитивно, хорошее разделение достигается гиперплоскостью, которая имеет наибольшее расстояние до ближайшей точки обучающих данных любого класса (так называемый функциональный запас), поскольку в целом, чем больше запас, тем ниже ошибка обобщения классификатора. [6] Более низкая ошибка обобщения означает, что реализатор с меньшей вероятностью столкнется с переобучением .
Ядро машины
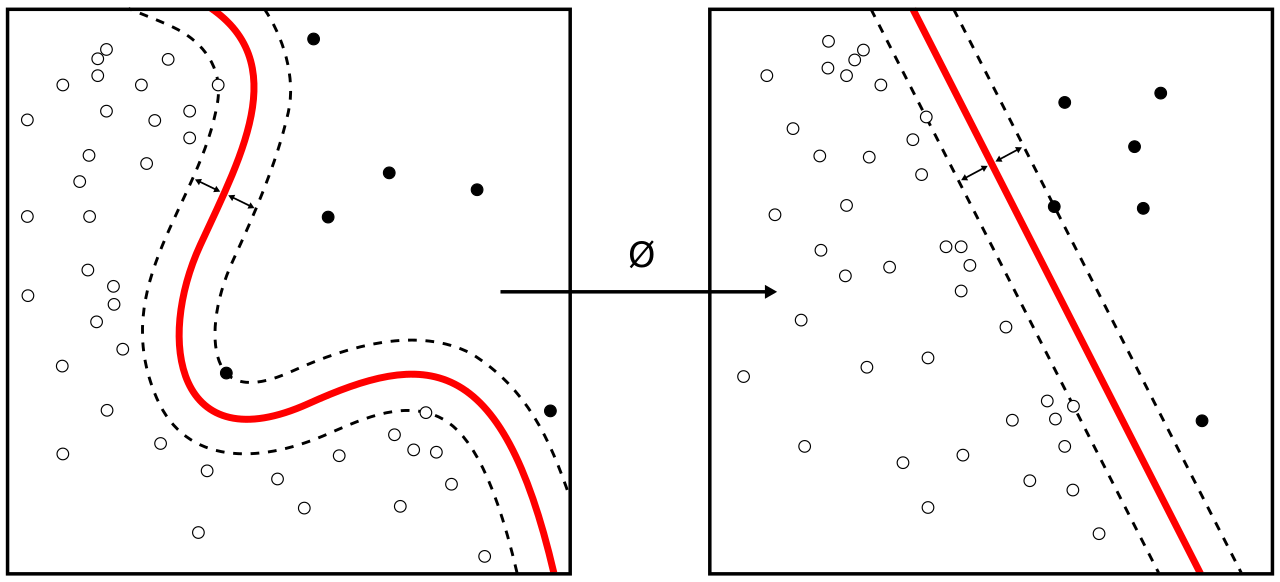
В то время как исходная задача может быть сформулирована в конечномерном пространстве, часто случается, что множества для дискриминации не являются линейно разделимыми в этом пространстве. По этой причине было предложено [7] , чтобы исходное конечномерное пространство было отображено в гораздо более многомерное пространство, предположительно, упрощая разделение в этом пространстве. Чтобы поддерживать разумную вычислительную нагрузку, отображения, используемые схемами SVM, разработаны так, чтобы гарантировать, что скалярные произведения пар векторов входных данных могут быть легко вычислены в терминах переменных в исходном пространстве, путем определения их в терминах функции ядра, выбранной в соответствии с задачей. [8] Гиперплоскости в многомерном пространстве определяются как набор точек, скалярное произведение которых с вектором в этом пространстве является постоянным, где такой набор векторов является ортогональным (и, следовательно, минимальным) набором векторов, который определяет гиперплоскость. Векторы, определяющие гиперплоскости, могут быть выбраны как линейные комбинации с параметрами изображений векторов признаков , которые встречаются в базе данных. При таком выборе гиперплоскости точки в пространстве признаков , отображаемые в гиперплоскость, определяются отношением Обратите внимание, что если становится малым по мере удаления от , каждый член в сумме измеряет степень близости контрольной точки к соответствующей точке базы данных . Таким образом, сумма ядер выше может использоваться для измерения относительной близости каждой контрольной точки к точкам данных, происходящим из одного или другого из наборов, которые должны быть различимы. Обратите внимание на тот факт, что набор точек, отображаемых в любую гиперплоскость, в результате может быть довольно запутанным, что позволяет проводить гораздо более сложную дискриминацию между наборами, которые вообще не являются выпуклыми в исходном пространстве.
Приложения
SVM можно использовать для решения различных реальных задач:
Классификация изображений также может быть выполнена с использованием SVM. Экспериментальные результаты показывают, что SVM достигают значительно более высокой точности поиска, чем традиционные схемы уточнения запросов всего после трех-четырех раундов обратной связи по релевантности. Это также верно для систем сегментации изображений , включая те, которые используют модифицированную версию SVM, которая использует привилегированный подход, предложенный Вапником. [11] [12]
Классификация спутниковых данных, таких как данные SAR, с использованием контролируемого SVM. [13]
Рукописные символы можно распознать с помощью SVM. [14] [15]
Алгоритм SVM широко применяется в биологических и других науках. Он использовался для классификации белков, при этом до 90% соединений были классифицированы правильно. Тесты перестановок, основанные на весах SVM, были предложены в качестве механизма интерпретации моделей SVM. [16] [17] Веса опорных векторных машин также использовались для интерпретации моделей SVM в прошлом. [18] Постфактум интерпретация моделей опорных векторных машин с целью выявления признаков, используемых моделью для прогнозирования, является относительно новой областью исследований, имеющей особое значение в биологических науках.
История
Оригинальный алгоритм SVM был изобретен Владимиром Н. Вапником и Алексеем Я. Червоненкисом в 1964 году. [ требуется ссылка ] В 1992 году Бернхард Бозер, Изабель Гийон и Владимир Вапник предложили способ создания нелинейных классификаторов, применяя трюк ядра к гиперплоскостям с максимальным отступом. [7] Воплощение «мягкого отступа», как это обычно используется в программных пакетах, было предложено Коринной Кортес и Вапником в 1993 году и опубликовано в 1995 году . [1]
Линейный SVM
Гиперплоскость максимального запаса и запасы для SVM, обученного на образцах из двух классов. Образцы на запасе называются опорными векторами.
Нам дан обучающий набор данных точек вида
, где либо 1, либо −1, каждый из которых указывает класс, к которому принадлежит точка. Каждый из них является -мерным вещественным вектором. Мы хотим найти «гиперплоскость с максимальным отступом», которая разделяет группу точек, для которых от группы точек, для которых , которая определяется так, что расстояние между гиперплоскостью и ближайшей точкой из любой группы максимизируется.
Любая гиперплоскость может быть записана как множество точек, удовлетворяющих ,
где — (не обязательно нормализованный) вектор нормали к гиперплоскости. Это очень похоже на нормальную форму Гессе , за исключением того, что — не обязательно единичный вектор. Параметр определяет смещение гиперплоскости от начала координат вдоль вектора нормали .
Предупреждение: большая часть литературы по этому вопросу определяет предвзятость так, что
Жесткая маржа
Если данные обучения линейно разделимы , мы можем выбрать две параллельные гиперплоскости, которые разделяют два класса данных, так что расстояние между ними будет как можно больше. Область, ограниченная этими двумя гиперплоскостями, называется «границей», а гиперплоскость с максимальной границей — это гиперплоскость, которая лежит посередине между ними. С нормализованным или стандартизированным набором данных эти гиперплоскости можно описать уравнениями
(все, что находится на этой границе или выше, относится к одному классу с меткой 1)
и
(все, что находится на этой границе или ниже, относится к другому классу с меткой −1).
Геометрически расстояние между этими двумя гиперплоскостями равно , [19] поэтому для максимизации расстояния между плоскостями мы хотим минимизировать . Расстояние вычисляется с использованием уравнения расстояния от точки до плоскости . Мы также должны предотвратить попадание точек данных на границу, мы добавляем следующее ограничение: для каждого или
или
Эти ограничения утверждают, что каждая точка данных должна лежать на правильной стороне границы.
Это можно переписать как
Мы можем объединить это, чтобы получить задачу оптимизации:
Решающие эту задачу операторы и определяют окончательный классификатор, , где — знаковая функция .
Важным следствием этого геометрического описания является то, что гиперплоскость максимального запаса полностью определяется теми, которые лежат ближе всего к ней (объясняется ниже). Они называются опорными векторами .
Мягкая маржа
Для расширения SVM на случаи, в которых данные не являются линейно разделимыми, полезна функция потери шарнира .
Обратите внимание, что — i -я цель (т.е. в данном случае 1 или −1), а — i -й выход.
Эта функция равна нулю, если выполняется ограничение в (1) , другими словами, если лежит на правильной стороне поля. Для данных на неправильной стороне поля значение функции пропорционально расстоянию от поля.
Целью оптимизации является минимизация:
где параметр определяет компромисс между увеличением размера поля и обеспечением того, что лежит на правильной стороне поля (обратите внимание, что мы можем добавить вес к любому члену в уравнении выше). Разложив потерю шарнира, эту задачу оптимизации можно свести к следующему:
Таким образом, при больших значениях он будет вести себя аналогично SVM с жестким запасом, если входные данные линейно классифицируемы, но все равно будет узнавать, является ли правило классификации жизнеспособным или нет.
Нелинейные ядра
Ядро машины
Первоначальный алгоритм гиперплоскости максимального отступа, предложенный Вапником в 1963 году, построил линейный классификатор . Однако в 1992 году Бернхард Бозер, Изабель Гийон и Владимир Вапник предложили способ создания нелинейных классификаторов, применяя трюк ядра (первоначально предложенный Айзерманом и др. [20] ) к гиперплоскостям максимального отступа. [7] Трюк ядра, в котором скалярные произведения заменяются ядрами, легко выводится в двойственном представлении задачи SVM. Это позволяет алгоритму вписывать гиперплоскость максимального отступа в преобразованное пространство признаков . Преобразование может быть нелинейным, а преобразованное пространство — высокоразмерным; хотя классификатор является гиперплоскостью в преобразованном пространстве признаков, он может быть нелинейным в исходном входном пространстве.
Примечательно, что работа в пространстве признаков более высокой размерности увеличивает ошибку обобщения опорных векторных машин, хотя при достаточном количестве образцов алгоритм все еще работает хорошо. [21]
Ядро связано с преобразованием уравнением . Значение w также находится в преобразованном пространстве, с . Скалярные произведения с w для классификации снова могут быть вычислены с помощью трюка с ядром, т.е. .
Вычисление классификатора SVM
Вычисление классификатора SVM (с мягким запасом) сводится к минимизации выражения вида
Мы сосредоточимся на классификаторе с мягкими границами, поскольку, как отмечено выше, выбор достаточно малого значения для дает классификатор с жесткими границами для линейно классифицируемых входных данных. Классический подход, который включает сведение (2) к задаче квадратичного программирования , подробно описан ниже. Затем будут рассмотрены более современные подходы, такие как субградиентный спуск и координатный спуск.
Первобытный
Минимизацию (2) можно переписать как задачу ограниченной оптимизации с дифференцируемой целевой функцией следующим образом.
Для каждого мы вводим переменную . Обратите внимание, что это наименьшее неотрицательное число, удовлетворяющее
Таким образом, мы можем переписать задачу оптимизации следующим образом:
Это называется первичной проблемой.
Двойной
Решая лагранжеву двойственную задачу выше, получаем упрощенную задачу
Это называется двойственной задачей. Поскольку двойственная задача максимизации является квадратичной функцией от с учетом линейных ограничений, она эффективно решается с помощью алгоритмов квадратичного программирования .
Здесь переменные определены таким образом, что
Более того, именно тогда, когда лежит на правильной стороне поля, и когда лежит на границе поля. Из этого следует, что можно записать в виде линейной комбинации опорных векторов.
Смещение, , можно восстановить, найдя на границе поля и решив
(Обратите внимание, что с .)
Трюк с ядром
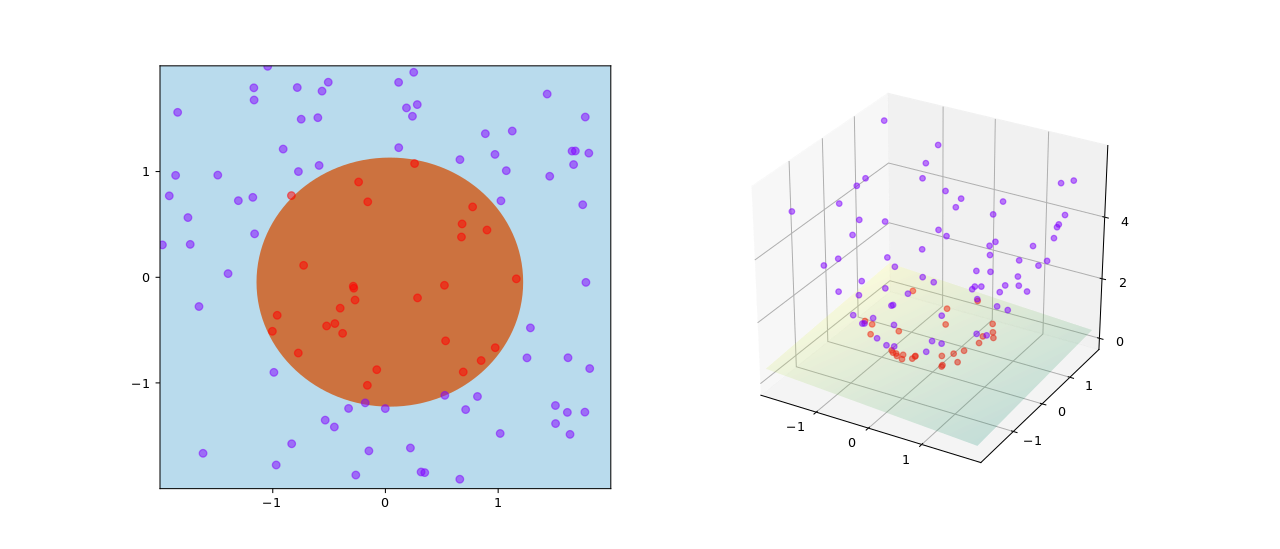
Пример обучения SVM с ядром, заданным как φ(( a , b )) = ( a , b , a 2 + b 2 )
Предположим теперь, что мы хотели бы изучить нелинейное правило классификации, которое соответствует линейному правилу классификации для преобразованных точек данных. Более того, нам дана функция ядра , которая удовлетворяет .
Мы знаем, что вектор классификации в преобразованном пространстве удовлетворяет условию
где, получены путем решения задачи оптимизации
Коэффициенты можно решить с помощью квадратичного программирования, как и раньше. Опять же, мы можем найти некоторый индекс такой, что , так что лежит на границе поля в преобразованном пространстве, а затем решить
Окончательно,
Современные методы
Последние алгоритмы для поиска классификатора SVM включают субградиентный спуск и координатный спуск. Оба метода доказали, что предлагают значительные преимущества по сравнению с традиционным подходом при работе с большими, разреженными наборами данных — субградиентные методы особенно эффективны, когда имеется много обучающих примеров, а координатный спуск — когда размерность пространства признаков высока.
Обратите внимание, что является выпуклой функцией и . Таким образом, традиционные методы градиентного спуска (или SGD ) могут быть адаптированы, где вместо того, чтобы делать шаг в направлении градиента функции, делается шаг в направлении вектора, выбранного из субградиента функции . Этот подход имеет то преимущество, что для некоторых реализаций количество итераций не масштабируется с , количеством точек данных. [22]
Для каждого , итеративно, коэффициент корректируется в направлении . Затем полученный вектор коэффициентов проецируется на ближайший вектор коэффициентов, который удовлетворяет заданным ограничениям. (Обычно используются евклидовы расстояния.) Затем процесс повторяется до тех пор, пока не будет получен почти оптимальный вектор коэффициентов. Полученный алгоритм чрезвычайно быстр на практике, хотя было доказано мало гарантий производительности. [23]
Эмпирическая минимизация риска
Описанная выше машина опорных векторов с мягким запасом является примером алгоритма минимизации эмпирического риска (ERM) для потери шарнира . С этой точки зрения машины опорных векторов относятся к естественному классу алгоритмов статистического вывода, и многие из их уникальных особенностей обусловлены поведением потери шарнира. Эта перспектива может дать дальнейшее понимание того, как и почему работают SVM, и позволит нам лучше проанализировать их статистические свойства.
Минимизация риска
В контролируемом обучении дается набор обучающих примеров с метками , и требуется предсказать заданное . Для этого формируется гипотеза , , такая, что является «хорошим» приближением . «Хорошее» приближение обычно определяется с помощью функции потерь , , которая характеризует, насколько плохим является предсказание . Затем мы хотели бы выбрать гипотезу, которая минимизирует ожидаемый риск :
В большинстве случаев мы не знаем совместное распределение прямого. В этих случаях общая стратегия заключается в выборе гипотезы, которая минимизирует эмпирический риск:
При определенных предположениях о последовательности случайных величин (например, что они генерируются конечным марковским процессом), если набор рассматриваемых гипотез достаточно мал, минимизатор эмпирического риска будет близко приближаться к минимизатору ожидаемого риска по мере увеличения. Этот подход называется минимизацией эмпирического риска, или ERM.
Регуляризация и стабильность
Для того чтобы задача минимизации имела четко определенное решение, мы должны наложить ограничения на набор рассматриваемых гипотез. Если — нормированное пространство (как в случае SVM), особенно эффективным методом является рассмотрение только тех гипотез, для которых . Это эквивалентно наложению штрафа за регуляризацию и решению новой задачи оптимизации
В более общем смысле это может быть некоторой мерой сложности гипотезы , поэтому предпочтение отдается более простым гипотезам.
SVM и потеря шарнира
Напомним, что классификатор SVM (с мягким запасом) выбран для минимизации следующего выражения:
В свете вышеизложенного обсуждения мы видим, что метод SVM эквивалентен минимизации эмпирического риска с регуляризацией Тихонова, где в этом случае функция потерь представляет собой шарнирную потерю
Разницу между потерей шарнира и этими другими функциями потерь лучше всего выразить в терминах целевых функций — функций, которые минимизируют ожидаемый риск для данной пары случайных величин .
В частности, пусть обозначает условие на событии, что . В настройке классификации имеем:
Таким образом, оптимальный классификатор:
Для квадратичных потерь целевая функция — это условная функция ожидания, ; Для логистических потерь — это логит-функция, . Хотя обе эти целевые функции дают правильный классификатор, как , они дают нам больше информации, чем нам нужно. Фактически, они дают нам достаточно информации, чтобы полностью описать распределение .
С другой стороны, можно проверить, что целевая функция для потери шарнира равна точно . Таким образом, в достаточно богатом пространстве гипотез — или, что эквивалентно, для соответствующим образом выбранного ядра — классификатор SVM будет сходиться к простейшей функции (в терминах ), которая правильно классифицирует данные. Это расширяет геометрическую интерпретацию SVM — для линейной классификации эмпирический риск минимизируется любой функцией, границы которой лежат между опорными векторами, и простейшим из них является классификатор с максимальным запасом. [24]
Характеристики
SVM принадлежат к семейству обобщенных линейных классификаторов и могут быть интерпретированы как расширение персептрона . [ 25] Их также можно считать частным случаем регуляризации Тихонова . Особое свойство заключается в том, что они одновременно минимизируют эмпирическую ошибку классификации и максимизируют геометрический запас ; поэтому их также называют классификаторами с максимальным запасом .
Сравнение SVM с другими классификаторами было проведено Мейером, Лейшем и Хорником. [26]
Выбор параметров
Эффективность SVM зависит от выбора ядра, параметров ядра и параметра мягкого поля . Обычным выбором является гауссовское ядро, которое имеет один параметр . Лучшая комбинация и часто выбирается с помощью поиска по сетке с экспоненциально растущими последовательностями и , например, ; . Обычно каждая комбинация выбора параметров проверяется с помощью перекрестной проверки , и выбираются параметры с наилучшей точностью перекрестной проверки. В качестве альтернативы недавняя работа по байесовской оптимизации может быть использована для выбора и , часто требуя оценки гораздо меньшего количества комбинаций параметров, чем поиск по сетке. Окончательная модель, которая используется для тестирования и классификации новых данных, затем обучается на всем обучающем наборе с использованием выбранных параметров. [27]
Проблемы
Потенциальные недостатки SVM включают в себя следующие аспекты:
Требуется полная маркировка входных данных
Некалиброванные вероятности принадлежности к классу — SVM вытекает из теории Вапника, которая избегает оценки вероятностей на основе конечных данных.
SVM применим только для двухклассовых задач. Поэтому необходимо применять алгоритмы, которые сводят многоклассовую задачу к нескольким бинарным задачам; см. раздел многоклассовый SVM.
Параметры решенной модели трудно интерпретировать.
Расширения
Мультиклассовый SVM
Целью многоклассового SVM является назначение меток экземплярам с помощью машин опорных векторов, где метки извлекаются из конечного набора из нескольких элементов.
Доминирующий подход для этого заключается в сведении одной многоклассовой проблемы к нескольким задачам бинарной классификации . [28] Распространенные методы такого сведения включают: [28] [29]
Создание бинарных классификаторов, различающих одну из меток и остальные ( один против всех ) или каждую пару классов ( один против одного ). Классификация новых экземпляров для случая один против всех выполняется с помощью стратегии «победитель получает все», в которой классификатор с наивысшей выходной функцией назначает класс (важно, чтобы выходные функции были откалиброваны для получения сопоставимых оценок). Для подхода один против одного классификация выполняется с помощью стратегии голосования с максимальным выигрышем, в которой каждый классификатор назначает экземпляр одному из двух классов, затем голос за назначенный класс увеличивается на один голос, и, наконец, класс с наибольшим количеством голосов определяет классификацию экземпляра.
Краммер и Сингер предложили многоклассовый метод SVM, который превращает многоклассовую задачу классификации в одну задачу оптимизации, а не разлагает ее на несколько задач бинарной классификации. [32] См. также Ли, Лин и Вахба [33] [34] и Ван ден Бург и Гроенен. [35]
Трансдуктивные опорные векторные машины
Трансдуктивные машины опорных векторов расширяют SVM в том, что они также могут обрабатывать частично помеченные данные в полуконтролируемом обучении , следуя принципам трансдукции . Здесь, в дополнение к обучающему набору , обучающемуся также дается набор
тестовых примеров для классификации. Формально, трансдуктивная машина опорных векторов определяется следующей первичной задачей оптимизации: [36]
Свернуть (в )
при условии (для любого и любого )
и
Трансдуктивные машины опорных векторов были введены Владимиром Н. Вапником в 1998 году.
Структурированный SVM
Структурированная машина опорных векторов является расширением традиционной модели SVM. В то время как модель SVM в первую очередь предназначена для бинарной классификации, многоклассовой классификации и задач регрессии, структурированная SVM расширяет свое применение для обработки общих структурированных выходных меток, например, деревьев синтаксического анализа, классификации с таксономиями, выравнивания последовательностей и многого другого. [37]
Регрессия
Регрессия опорных векторов (прогноз) с различными порогами ε . По мере увеличения ε прогноз становится менее чувствительным к ошибкам.
Версия SVM для регрессии была предложена в 1996 году Владимиром Н. Вапником , Харрисом Друкером, Кристофером Дж. К. Берджесом, Линдой Кауфманом и Александром Дж. Смолой. [38] Этот метод называется регрессией опорных векторов (SVR). Модель, созданная с помощью классификации опорных векторов (как описано выше), зависит только от подмножества обучающих данных, поскольку функция стоимости для построения модели не заботится о обучающих точках, которые лежат за пределами поля. Аналогично, модель, созданная с помощью SVR, зависит только от подмножества обучающих данных, поскольку функция стоимости для построения модели игнорирует любые обучающие данные, близкие к прогнозу модели. Другая версия SVM, известная как машина опорных векторов наименьших квадратов (LS-SVM), была предложена Сайкенсом и Вандевалле. [39]
Обучение оригинального SVR означает решение [40]
минимизировать
при условии
где — обучающая выборка с целевым значением . Внутренний продукт плюс свободный член — это прогноз для этой выборки, и это свободный параметр, который служит порогом: все прогнозы должны находиться в диапазоне истинных прогнозов. Слабые переменные обычно добавляются в вышеприведенное, чтобы учесть ошибки и разрешить аппроксимацию в случае, если вышеуказанная проблема невыполнима.
Байесовский SVM
В 2011 году Полсон и Скотт показали, что SVM допускает байесовскую интерпретацию посредством техники аугментации данных . [41] В этом подходе SVM рассматривается как графическая модель (где параметры связаны через распределения вероятностей). Этот расширенный вид позволяет применять байесовские методы к SVM, такие как гибкое моделирование признаков, автоматическая настройка гиперпараметров и предиктивная количественная оценка неопределенности . Недавно Флориан Венцель разработал масштабируемую версию байесовского SVM, что позволило применять байесовские SVM к большим данным . [42] Флориан Венцель разработал две разные версии: схему вариационного вывода (VI) для машины опорных векторов байесовского ядра (SVM) и стохастическую версию (SVI) для линейного байесовского SVM. [43]
Выполнение
Параметры гиперплоскости максимального запаса выводятся путем решения оптимизации. Существует несколько специализированных алгоритмов для быстрого решения задачи квадратичного программирования (QP), которая возникает из SVM, в основном полагаясь на эвристику для разбиения задачи на более мелкие, более управляемые части.
Другой подход заключается в использовании метода внутренней точки , который использует итерации типа Ньютона для поиска решения условий Каруша–Куна–Таккера основной и двойственной задач. [44]
Вместо решения последовательности разбитых задач этот подход напрямую решает задачу в целом. Чтобы избежать решения линейной системы, включающей большую матрицу ядра, в трюке ядра часто используется приближение матрицы низкого ранга.
Другим распространенным методом является алгоритм последовательной минимальной оптимизации (SMO) Платта , который разбивает задачу на 2-мерные подзадачи, которые решаются аналитически, устраняя необходимость в алгоритме численной оптимизации и матричном хранилище. Этот алгоритм концептуально прост, прост в реализации, в целом быстрее и имеет лучшие свойства масштабирования для сложных задач SVM. [45]
Частный случай линейных опорных векторных машин может быть решен более эффективно с помощью того же типа алгоритмов, которые используются для оптимизации его близкого родственника, логистической регрессии ; этот класс алгоритмов включает в себя субградиентный спуск (например, PEGASOS [46] ) и координатный спуск (например, LIBLINEAR [47] ). LIBLINEAR имеет некоторые привлекательные свойства времени обучения. Каждая итерация сходимости занимает время, линейное по времени, необходимому для чтения данных обучения, и итерации также имеют свойство Q-линейной сходимости , что делает алгоритм чрезвычайно быстрым.
Общие ядерные SVM также можно решать более эффективно с использованием субградиентного спуска (например, P-packSVM [48] ), особенно когда допускается распараллеливание .
Ядерные SVM доступны во многих наборах инструментов машинного обучения, включая LIBSVM , MATLAB , SAS, SVMlight, kernlab, scikit-learn , Shogun , Weka , Shark, JKernelMachines, OpenCV и другие.
Предварительная обработка данных (стандартизация) настоятельно рекомендуется для повышения точности классификации. [49] Существует несколько методов стандартизации, таких как min-max, нормализация по десятичному масштабированию, Z-оценка. [50] Вычитание среднего значения и деление на дисперсию каждого признака обычно используется для SVM. [51]
^ Вапник, Владимир Н. (1997). «Метод опорных векторов». В Gerstner, Wulfram; Germond, Alain; Hasler, Martin; Nicoud, Jean-Daniel (ред.). Искусственные нейронные сети — ICANN'97 . Конспект лекций по информатике. Том 1327. Берлин, Гейдельберг: Springer. стр. 261–271. doi :10.1007/BFb0020166. ISBN978-3-540-69620-9.
^ Авад, Мариетт; Ханна, Рахул (2015). «Опорные векторные машины для классификации». Эффективные обучающие машины . Apress. стр. 39–66. doi : 10.1007/978-1-4302-5990-9_3 . ISBN978-1-4302-5990-9.
^ Бен-Гур, Аса; Хорн, Дэвид; Зигельманн, Хава; Вапник Владимир Николаевич».«Кластеризация опорных векторов» (2001);». Журнал исследований машинного обучения . 2 : 125–137.
^ "1.4. Метод опорных векторов — документация scikit-learn 0.20.2". Архивировано из оригинала 2017-11-08 . Получено 2017-11-08 .
^ Хасти, Тревор ; Тибширани, Роберт ; Фридман, Джером (2008). Элементы статистического обучения: добыча данных, вывод и прогнозирование (PDF) (Второе изд.). Нью-Йорк: Springer. С. 134.
^ abc Boser, Bernhard E.; Guyon, Isabelle M.; Vapnik, Vladimir N. (1992). "A training algorithm for optimize margin classifiers". Труды пятого ежегодного семинара по теории вычислительного обучения – COLT '92 . стр. 144. CiteSeerX 10.1.1.21.3818 . doi :10.1145/130385.130401. ISBN978-0897914970. S2CID 207165665.
^ Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (2007). "Раздел 16.5. Опорные векторные машины". Numerical Recipes: The Art of Scientific Computing (3-е изд.). Нью-Йорк: Cambridge University Press. ISBN978-0-521-88068-8. Архивировано из оригинала 2011-08-11.
^ Йоахимс, Торстен (1998). «Текстовая категоризация с помощью опорных векторных машин: обучение с использованием множества релевантных признаков». Машинное обучение: ECML-98 . Конспект лекций по информатике. Том 1398. Springer. С. 137–142. doi : 10.1007/BFb0026683 . ISBN978-3-540-64417-0.
^ Прадхан, Самир С. и др. (2 мая 2004 г.). Неглубокий семантический анализ с использованием опорных векторных машин. Труды конференции по технологиям естественного языка североамериканского отделения Ассоциации компьютерной лингвистики: HLT-NAACL 2004. Ассоциация компьютерной лингвистики. стр. 233–240.
^ Вапник, Владимир Н.: Приглашенный докладчик. IPMU Обработка информации и управление 2014).
^ Barghout, Lauren (2015). "Пространственно-таксонные информационные гранулы, используемые в итеративном нечетком принятии решений для сегментации изображений" (PDF) . Гранулярные вычисления и принятие решений . Исследования в области больших данных. Том 10. С. 285–318. doi :10.1007/978-3-319-16829-6_12. ISBN978-3-319-16828-9. S2CID 4154772. Архивировано из оригинала (PDF) 2018-01-08 . Получено 2018-01-08 .
^ А. Майти (2016). «Контролируемая классификация поляриметрических данных RADARSAT-2 для различных особенностей суши». arXiv : 1608.00501 [cs.CV].
^ Maitra, DS; Bhattacharya, U.; Parui, SK (август 2015 г.). «Общий подход к распознаванию рукописных символов нескольких шрифтов на основе CNN». 2015 13-я Международная конференция по анализу и распознаванию документов (ICDAR) . стр. 1021–1025. doi :10.1109/ICDAR.2015.7333916. ISBN978-1-4799-1805-8. S2CID 25739012.
^ Гаонкар, Б.; Даватцикос, К. (2013). «Аналитическая оценка карт статистической значимости для многомерного анализа и классификации изображений на основе машины опорных векторов». NeuroImage . 78 : 270–283. doi :10.1016/j.neuroimage.2013.03.066. PMC 3767485 . PMID 23583748.
^ Cuingnet, Rémi; Rosso, Charlotte; Chupin, Marie; Lehéricy, Stéphane; Dormont, Didier; Benali, Habib; Samson, Yves; Colliot, Olivier (2011). "Пространственная регуляризация SVM для обнаружения изменений диффузии, связанных с исходом инсульта" (PDF) . Medical Image Analysis . 15 (5): 729–737. doi :10.1016/j.media.2011.05.007. PMID 21752695. Архивировано из оригинала (PDF) 22.12.2018 . Получено 08.01.2018 .
^ Статников, Александр; Хардин, Дуглас; и Алиферис, Константин; (2006); «Использование методов на основе весов SVM для определения причинно-следственных и не причинно-следственных переменных», Sign , 1, 4.
^ "Почему маржа SVM равна 2 ‖ w ‖ {\displaystyle {\frac {2}{\|\mathbf {w} \|}}} ". Mathematics Stack Exchange . 30 мая 2015 г.
^ Айзерман, Марк А.; Браверман, Эммануэль М. и Розоноэр, Лев И. (1964). «Теоретические основы метода потенциальной функции в обучении распознаванию образов». Автоматизация и дистанционное управление . 25 : 821–837.
^ Jin, Chi; Wang, Liwei (2012). Зависящая от размерности граница PAC-Bayes. Достижения в области нейронных систем обработки информации. CiteSeerX 10.1.1.420.3487 . Архивировано из оригинала 2015-04-02.
^ Шалев-Шварц, Шай; Сингер, Йорам; Сребро, Натан; Коттер, Эндрю (16 октября 2010 г.). «Pegasos: primal estimate sub-gradient resolver for SVM». Математическое программирование . 127 (1): 3–30. CiteSeerX 10.1.1.161.9629 . doi :10.1007/s10107-010-0420-4. ISSN 0025-5610. S2CID 53306004.
^ Hsieh, Cho-Jui; Chang, Kai-Wei; Lin, Chih-Jen; Keerthi, S. Sathiya; Sundararajan, S. (2008-01-01). "Метод спуска по двойной координате для крупномасштабного линейного SVM". Труды 25-й международной конференции по машинному обучению - ICML '08 . Нью-Йорк, Нью-Йорк, США: ACM. стр. 408–415. CiteSeerX 10.1.1.149.5594 . doi :10.1145/1390156.1390208. ISBN978-1-60558-205-4. S2CID 7880266.
^ Росаско, Лоренцо; Де Вито, Эрнесто; Капоннетто, Андреа; Пиана, Мишель; Верри, Алессандро (1 мая 2004 г.). «Все ли функции потерь одинаковы?». Нейронные вычисления . 16 (5): 1063–1076. CiteSeerX 10.1.1.109.6786 . дои : 10.1162/089976604773135104. ISSN 0899-7667. PMID 15070510. S2CID 11845688.
^ Р. Коллобер и С. Бенжио (2004). Связи между персептронами, многослойными перцептронами и опорными векторами. Труды Международной конференции по машинному обучению (ICML).
^ Мейер, Дэвид; Лейш, Фридрих; Хорник, Курт (сентябрь 2003 г.). «Машина опорных векторов в процессе тестирования». Neurocomputing . 55 (1–2): 169–186. doi :10.1016/S0925-2312(03)00431-4.
^ Hsu, Chih-Wei; Chang, Chih-Chung & Lin, Chih-Jen (2003). Практическое руководство по классификации опорных векторов (PDF) (технический отчет). Кафедра компьютерных наук и информационной инженерии, Национальный университет Тайваня. Архивировано (PDF) из оригинала 25.06.2013.
^ ab Duan, Kai-Bo; Keerthi, S. Sathiya (2005). "Какой метод SVM для нескольких классов является лучшим? Эмпирическое исследование" (PDF) . Системы множественных классификаторов . LNCS . Том 3541. стр. 278–285. CiteSeerX 10.1.1.110.6789 . doi :10.1007/11494683_28. ISBN978-3-540-26306-7. Архивировано из оригинала (PDF) 2013-05-03 . Получено 2019-07-18 .
^ Hsu, Chih-Wei & Lin, Chih-Jen (2002). "Сравнение методов для многоклассовых опорных векторных машин" (PDF) . IEEE Transactions on Neural Networks . 13 (2): 415–25. doi :10.1109/72.991427. PMID 18244442. Архивировано из оригинала (PDF) 2013-05-03 . Получено 2018-01-08 .
^ Платт, Джон; Кристианини, Нелло ; Шоу-Тейлор, Джон (2000). "DAG с большими полями для многоклассовой классификации" (PDF) . В Солла, Сара А .; Лин, Тодд К.; Мюллер, Клаус-Роберт (ред.). Достижения в области нейронных систем обработки информации . MIT Press. стр. 547–553. Архивировано (PDF) из оригинала 2012-06-16.
^ Дитерих, Томас Г.; Бакири, Гулум (1995). «Решение задач многоклассового обучения с помощью выходных кодов с исправлением ошибок» (PDF) . Журнал исследований искусственного интеллекта . 2 : 263–286. arXiv : cs/9501101 . Bibcode :1995cs........1101D. doi :10.1613/jair.105. S2CID 47109072. Архивировано (PDF) из оригинала 2013-05-09.
^ Краммер, Коби и Сингер, Йорам (2001). «Об алгоритмической реализации векторных машин на основе многоклассового ядра» (PDF) . Журнал исследований машинного обучения . 2 : 265–292. Архивировано (PDF) из оригинала 29-08-2015.
^ Ли, Юнгён; Лин, Йи и Вахба, Грейс (2001). «Многокатегорийные опорные векторные машины» (PDF) . Вычислительная наука и статистика . 33. Архивировано (PDF) из оригинала 2013-06-17.
^ Ли, Юнгён; Лин, Йи; Вахба, Грейс (2004). «Многокатегорийные опорные векторные машины». Журнал Американской статистической ассоциации . 99 (465): 67–81. CiteSeerX 10.1.1.22.1879 . doi :10.1198/016214504000000098. S2CID 7066611.
^ Ван ден Бург, Геррит Дж. Дж. и Гроенен, Патрик Дж. Ф. (2016). «GenSVM: обобщенная многоклассовая машина опорных векторов» (PDF) . Журнал исследований машинного обучения . 17 (224): 1–42.
^ Йоахимс, Торстен. Трансдуктивный вывод для классификации текста с использованием опорных векторных машин (PDF) . Труды Международной конференции по машинному обучению 1999 года (ICML 1999). стр. 200–209.
^ https://www.cs.cornell.edu/people/tj/publications/tsochantaridis_etal_04a.pdf [ пустой URL-адрес PDF ]
^ Друкер, Харрис; Берджес, Крайст. К.; Кауфман, Линда; Смола, Александр Дж.; и Вапник, Владимир Н. (1997); «Машины регрессии опорных векторов», в Advances in Neural Information Processing Systems 9, NIPS 1996 , 155–161, MIT Press.
^ Suykens, Johan AK; Vandewalle, Joos PL; «Классификаторы на основе опорных векторных машин наименьших квадратов», Neural Processing Letters , т. 9, № 3, июнь 1999 г., стр. 293–300.
^ Smola, Alex J.; Schölkopf, Bernhard (2004). "Учебник по регрессии опорных векторов" (PDF) . Статистика и вычисления . 14 (3): 199–222. CiteSeerX 10.1.1.41.1452 . doi :10.1023/B:STCO.0000035301.49549.88. S2CID 15475. Архивировано (PDF) из оригинала 2012-01-31.
^ Полсон, Николас Г.; Скотт, Стивен Л. (2011). «Увеличение данных для опорных векторных машин». Байесовский анализ . 6 (1): 1–23. doi : 10.1214/11-BA601 .
^ Венцель, Флориан; Гали-Фажу, Тео; Дойч, Маттеус; Клофт, Мариус (2017). «Байесовские нелинейные машины опорных векторов для больших данных». Машинное обучение и обнаружение знаний в базах данных . Конспект лекций по информатике. Том 10534. С. 307–322. arXiv : 1707.05532 . Bibcode :2017arXiv170705532W. doi :10.1007/978-3-319-71249-9_19. ISBN978-3-319-71248-2. S2CID 4018290.
^ Флориан Венцель; Маттеус Дойч; Тео Гали-Фажу; Мариус Клофт; «Масштабируемый приближенный вывод для байесовской нелинейной машины опорных векторов»
^ Ferris, Michael C.; Munson, Todd S. (2002). "Методы внутренних точек для массивных опорных векторных машин" (PDF) . SIAM Journal on Optimization . 13 (3): 783–804. CiteSeerX 10.1.1.216.6893 . doi :10.1137/S1052623400374379. S2CID 13563302. Архивировано (PDF) из оригинала 2008-12-04.
^ Платт, Джон К. (1998). Последовательная минимальная оптимизация: быстрый алгоритм для обучения опорных векторных машин (PDF) . NIPS. Архивировано (PDF) из оригинала 2015-07-02.
^ Фань, Ронг-Эн; Чанг, Кай-Вэй; Хси, Чо-Жуй; Ван, Сян-Руй; Линь, Чи-Джен (2008). "LIBLINEAR: Библиотека для большой линейной классификации" (PDF) . Журнал исследований машинного обучения . 9 : 1871–1874.
^ Фань, Ронг-Эн; Чанг, Кай-Вэй; Сье, Чо-Жуй; Ван, Сян-Руй; Линь, Чи-Джен (2008). «LIBLINEAR: Библиотека для большой линейной классификации». Журнал исследований машинного обучения . 9 (авг): 1871–1874.
^ Мохамад, Исмаил; Усман, Дауда (2013-09-01). «Стандартизация и ее влияние на алгоритм кластеризации K-средних». Research Journal of Applied Sciences, Engineering and Technology . 6 (17): 3299–3303. doi : 10.19026/rjaset.6.3638 .
^ Феннелл, Питер; Цзо, Жия; Лерман, Кристина (2019-12-01). «Прогнозирование и объяснение поведенческих данных с помощью структурированной декомпозиции пространства признаков». EPJ Data Science . 8 . arXiv : 1810.09841 . doi : 10.1140/epjds/s13688-019-0201-0 .
Дальнейшее чтение
Беннетт, Кристин П.; Кэмпбелл, Колин (2000). «Машины опорных векторов: шумиха или аллилуйя?» (PDF) . Исследования SIGKDD . 2 (2): 1–13. doi :10.1145/380995.380999. S2CID 207753020.
Кристианини, Нелло; Шоу-Тейлор, Джон (2000). Введение в опорные векторные машины и другие методы обучения на основе ядра . Cambridge University Press. ISBN 0-521-78019-5.
Фрадкин, Дмитрий; Мучник, Илья (2006). "Машины опорных векторов для классификации" (PDF) . В Abello, J.; Carmode, G. (ред.). Дискретные методы в эпидемиологии . Серия DIMACS в дискретной математике и теоретической информатике. Том 70. С. 13–20.[ цитата не найдена ]
Йоахимс, Торстен (1998). "Текстовая категоризация с помощью опорных векторных машин: обучение с использованием множества релевантных признаков". В Nédellec, Claire; Rouveirol, Céline (ред.). "Машинное обучение: ECML-98 . Конспект лекций по информатике. Том 1398. Берлин, Гейдельберг: Springer. стр. 137-142. doi :10.1007/BFb0026683. ISBN 978-3-540-64417-0. S2CID 2427083.
Ivanciuc, Ovidiu (2007). "Применение опорных векторных машин в химии" (PDF) . Обзоры в Computational Chemistry . 23 : 291–400. doi :10.1002/9780470116449.ch6. ISBN 9780470116449.
Джеймс, Гарет; Виттен, Даниэла; Хасти, Тревор; Тибширани, Роберт (2013). «Машины опорных векторов» (PDF) . Введение в статистическое обучение: с приложениями в R. Нью-Йорк: Springer. С. 337–372. ISBN 978-1-4614-7137-0.
Шёлкопф, Бернхард; Смола, Александр Дж. (2002). Обучение с помощью ядер . Кембридж, Массачусетс: MIT Press. ISBN 0-262-19475-9.
Стейнварт, Инго; Кристманн, Андреас (2008). Машины опорных векторов . Нью-Йорк: Спрингер. ISBN 978-0-387-77241-7.
libsvm, LIBSVM — популярная библиотека SVM-обучающихся
liblinear — библиотека для большой линейной классификации, включающая некоторые SVM
SVM light — это набор программных инструментов для обучения и классификации с использованием SVM.
Демонстрация SVMJS в реальном времени Архивировано 05.05.2013 на Wayback Machine. Демонстрация графического интерфейса для реализации SVM на JavaScript.
.svg/1280px-Svm_separating_hyperplanes_(SVG).svg.png)



































![{\displaystyle \lВерт \mathbf {w} \rВерт ^{2}+C\left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(\mathbf {w} ^{\mathsf {T}}\mathbf {x} _{i}-b)\right)\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b5dc624654eef8f3a8994da013e19dd98774e28f)





















![{\displaystyle {\begin{align}&{\text{minimize }}{\frac {1}{n}}\sum _{i=1}^{n}\zeta _{i}+\lambda \|\mathbf {w} \|^{2}\\[0.5ex]&{\text{subject to }}y_{i}\left(\mathbf {w} ^{\mathsf {T}}\mathbf {x} _{i}-b\right)\geq 1-\zeta _{i}\,{\text{ and }}\,\zeta _{i}\geq 0,\,{\text{for all }}i.\end{align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/55f31fe5bcd9363b51ab5a4c4387202f32f047ee)













![{\displaystyle {\begin{aligned}b=\mathbf {w} ^{\mathsf {T}}\varphi (\mathbf {x} _{i})-y_{i}&=\left[\sum _ {j=1}^{n}c_{j}y_{j}\varphi (\mathbf {x} _{j})\cdot \varphi (\mathbf {x} _{i})\right]-y_ {i}\\&=\left[\sum _{j=1}^{n}c_{j}y_{j}k(\mathbf {x} _{j},\mathbf {x} _{i })\right]-y_{i}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/84f72e9d29c896b17db3c3640ed94a2395ef5ce8)
![{\displaystyle \mathbf {z} \mapsto \operatorname {sgn}(\mathbf {w} ^{\mathsf {T}}\varphi (\mathbf {z} )-b)=\operatorname {sgn} \left(\left[\sum _{i=1}^{n}c_{i}y_{i}k(\mathbf {x} _{i},\mathbf {z} )\right]-b\right).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5ad3c52254fc4372047bc849648b0b8554e47ab4)
![{\displaystyle f(\mathbf {w} ,b)=\left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(\mathbf {w} ^{\mathsf {T}}\mathbf {x} _{i}-b)\right)\right]+\lambda \|\mathbf {w} \|^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/458eaac43a20c151eb9c977c96b6df2d6066bae9)











![{\displaystyle \varepsilon (f)=\mathbb {E} \left[\ell (y_{n+1},f(X_{n+1}))\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4b39a0005cd33d8ba9a9c9b18998577b32b6f519)









![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}(\mathbf {w} ^{\mathsf {T}}\mathbf {x} -b)\right)\right]+\lambda \|\mathbf {w} \|^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/85d62a82b5412759d590dea809a53f63b41bb697)








![{\displaystyle f_{sq}(x)=\mathbb {E} \left[y_{x}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/db61f0b198879db710784726430ff7acf542d724)


















