
В вычислительной технике хэш -таблица — это структура данных , реализующая ассоциативный массив , также называемый словарем или просто картой; ассоциативный массив — это абстрактный тип данных , который сопоставляет ключи со значениями . [2] Хэш-таблица использует хэш-функцию для вычисления индекса , также называемого хэш-кодом , в массиве контейнеров или слотов , из которого можно найти нужное значение. Во время поиска ключ хэшируется, и полученный хэш указывает, где хранится соответствующее значение. Карта, реализованная хэш-таблицей, называется хэш-картой .
Большинство конструкций хэш-таблиц используют несовершенную хэш-функцию . Коллизии хэш-функций , когда хэш-функция генерирует один и тот же индекс для более чем одного ключа, как правило, должны быть каким-то образом учтены.
В хорошо размерной хэш-таблице средняя временная сложность для каждого поиска не зависит от количества элементов, хранящихся в таблице. Многие конструкции хэш-таблиц также допускают произвольные вставки и удаления пар ключ-значение , при амортизированной постоянной средней стоимости за операцию. [3] [4] [5]
Хеширование является примером компромисса между пространством и временем . Если память бесконечна, весь ключ может быть использован непосредственно в качестве индекса для поиска его значения с помощью одного доступа к памяти. С другой стороны, если доступно бесконечное время, значения могут храниться независимо от их ключей, и для извлечения элемента может использоваться двоичный поиск или линейный поиск . [6] : 458
Во многих ситуациях хэш-таблицы оказываются в среднем более эффективными, чем деревья поиска или любая другая структура поиска в таблице . По этой причине они широко используются во многих видах компьютерного программного обеспечения , особенно для ассоциативных массивов , индексации баз данных , кэшей и наборов .
Идея хеширования возникла независимо в разных местах. В январе 1953 года Ганс Петер Лун написал внутренний меморандум IBM , в котором использовалось хеширование с цепочкой. Первый пример открытой адресации был предложен AD Linh, основанный на меморандуме Луна. [4] : 547 Примерно в то же время Gene Amdahl , Elaine M. McGraw , Nathaniel Rochester и Arthur Samuel из IBM Research реализовали хеширование для ассемблера IBM 701. [7] : 124 Открытая адресация с линейным зондированием приписывается Amdahl, хотя та же идея независимо возникла у Андрея Ершова . [7] : 124–125 Термин «открытая адресация» был придуман W. Wesley Peterson в его статье, в которой обсуждается проблема поиска в больших файлах. [8] : 15
Первая опубликованная работа по хешированию с цепочкой приписывается Арнольду Дюмею , который обсуждал идею использования остатка по модулю простого числа в качестве хеш-функции. [8] : 15 Слово «хеширование» впервые было опубликовано в статье Роберта Морриса. [7] : 126 Теоретический анализ линейного зондирования был первоначально представлен Конхеймом и Вайсом. [8] : 15
Ассоциативный массив хранит набор пар (ключ, значение) и позволяет выполнять вставку, удаление и поиск (search) с ограничением уникальных ключей . В реализации ассоциативных массивов в виде хэш-таблицы массив длины частично заполнен элементами, где . Значение сохраняется в индексном месте , где — хэш-функция, а . [8] : 2 При разумных предположениях хэш-таблицы имеют лучшие временные границы сложности для операций поиска, удаления и вставки по сравнению с самобалансирующимися бинарными деревьями поиска . [8] : 1
Хэш-таблицы также часто используются для реализации наборов, при этом опускается сохраненное значение для каждого ключа и просто отслеживается наличие ключа. [8] : 1
Коэффициент загрузки является критической статистикой хэш-таблицы и определяется следующим образом: [1] где
Производительность хэш-таблицы ухудшается в зависимости от коэффициента загрузки . [8] : 2
Программное обеспечение обычно обеспечивает, чтобы коэффициент загрузки оставался ниже определенной константы, . Это помогает поддерживать хорошую производительность. Поэтому распространенный подход заключается в изменении размера или «перехешировании» хэш-таблицы всякий раз, когда коэффициент загрузки достигает . Аналогичным образом таблица также может быть изменена в размере, если коэффициент загрузки падает ниже . [9]
При использовании отдельных цепочек хэш-таблиц каждый слот массива блоков хранит указатель на список или массив данных. [10]
Отдельные цепочки хэш-таблиц постепенно снижают производительность по мере роста коэффициента загрузки, и не существует фиксированной точки, после которой изменение размера становится абсолютно необходимым. [9]
При раздельном объединении в цепочку значение, дающее наилучшую производительность, обычно находится в диапазоне от 1 до 3. [9]
При открытой адресации каждый слот массива bucket содержит ровно один элемент. Поэтому хэш-таблица с открытой адресацией не может иметь коэффициент загрузки больше 1. [10]
Эффективность открытой адресации становится очень низкой, когда коэффициент загрузки приближается к 1. [9]
Поэтому хэш-таблица, использующая открытую адресацию, должна быть изменена в размере или перехеширована, если коэффициент загрузки приближается к 1. [9]
При открытой адресации приемлемые значения максимального коэффициента загрузки должны находиться в диапазоне от 0,6 до 0,75. [11] [12] : 110
Функция хэширования отображает вселенную ключей в индексы или слоты в таблице, то есть для . Традиционные реализации функций хэширования основаны на предположении целочисленной вселенной , что все элементы таблицы происходят из вселенной , где длина бита ограничена размером слова компьютерной архитектуры . [8] : 2
Говорят, что хеш-функция идеальна для заданного множества, если она инъективна на , то есть если каждый элемент отображается на различное значение в . [13] [14] Идеальную хеш-функцию можно создать, если все ключи известны заранее. [13]
Схемы хеширования, используемые в предположении целочисленной вселенной, включают хеширование делением, хеширование умножением, универсальное хеширование , динамическое совершенное хеширование и статическое совершенное хеширование . [8] : 2 Однако хеширование делением является наиболее часто используемой схемой. [15] : 264 [12] : 110
Схема хеширования делением выглядит следующим образом: [8] : 2 где — значение хеш-функции , а — размер таблицы.
Схема хеширования умножением выглядит следующим образом: [8] : 2–3 Где — нецелая вещественная константа , а — размер таблицы. Преимущество хеширования умножением в том, что не является критическим. [8] : 2–3 Хотя любое значение создает хеш-функцию, Дональд Кнут предлагает использовать золотое сечение . [8] : 3
Равномерное распределение значений хэша является фундаментальным требованием хэш-функции. Неравномерное распределение увеличивает количество коллизий и стоимость их разрешения. Равномерность иногда трудно обеспечить с помощью дизайна, но ее можно оценить эмпирически с помощью статистических тестов, например, критерия хи-квадрат Пирсона для дискретных равномерных распределений. [16] [17]
Распределение должно быть равномерным только для размеров таблиц, которые встречаются в приложении. В частности, если используется динамическое изменение размера с точным удвоением и делением пополам размера таблицы, то хэш-функция должна быть равномерна только тогда, когда размер является степенью двойки . Здесь индекс может быть вычислен как некоторый диапазон битов хэш-функции. С другой стороны, некоторые алгоритмы хэширования предпочитают, чтобы размер был простым числом . [18]
Для схем открытой адресации хэш-функция также должна избегать кластеризации , сопоставления двух или более ключей с последовательными слотами. Такая кластеризация может привести к резкому росту стоимости поиска, даже если коэффициент загрузки низок, а коллизии редки. Утверждается, что популярный мультипликативный хэш имеет особенно плохое поведение кластеризации. [18] [4]
K-независимое хеширование предлагает способ доказать, что определенная хеш-функция не имеет плохих наборов ключей для заданного типа хеш-таблицы. Ряд результатов K-независимости известны для схем разрешения коллизий, таких как линейное зондирование и хеширование кукушки. Поскольку K-независимость может доказать, что хеш-функция работает, можно сосредоточиться на поиске максимально быстрой такой хеш-функции. [19]
Алгоритм поиска, использующий хеширование, состоит из двух частей. Первая часть вычисляет хеш-функцию , которая преобразует ключ поиска в индекс массива . Идеальный случай — это когда никакие два ключа поиска не хешируются в один и тот же индекс массива. Однако это не всегда так и невозможно гарантировать для невидимых данных. [20] : 515 Следовательно, вторая часть алгоритма — разрешение коллизий. Два распространенных метода разрешения коллизий — это раздельное связывание и открытая адресация. [6] : 458

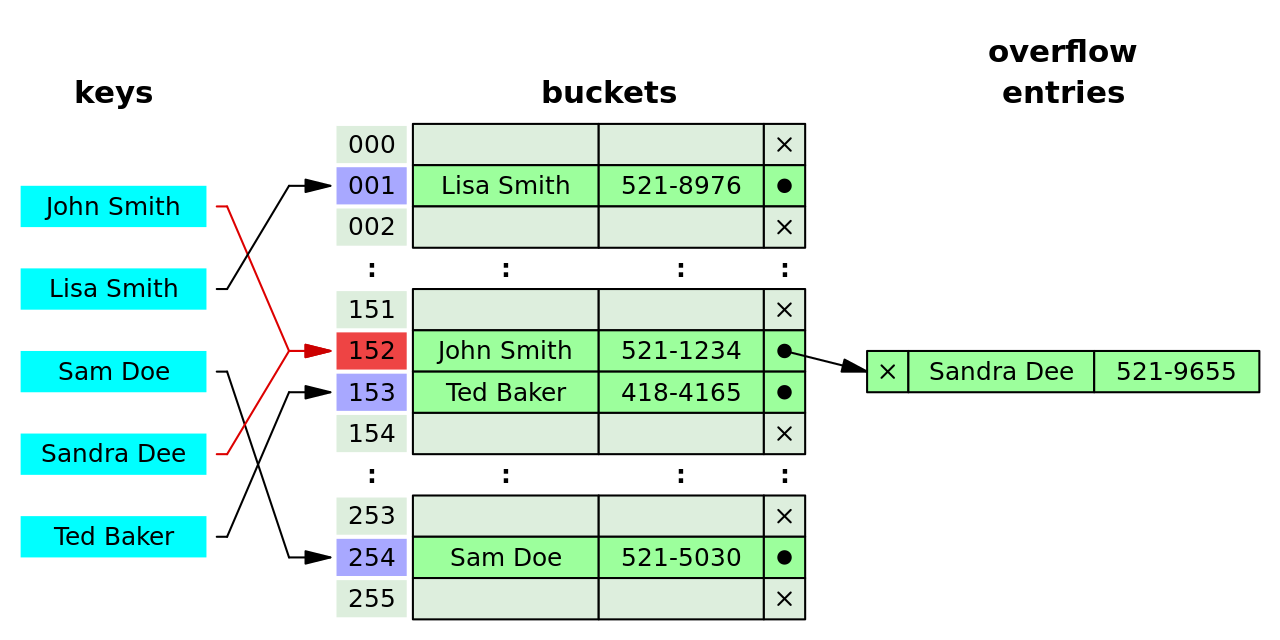
В раздельной цепочке процесс включает построение связанного списка с парой ключ-значение для каждого индекса массива поиска. Сталкивающиеся элементы связываются вместе через один связанный список, который можно просмотреть для доступа к элементу с уникальным ключом поиска. [6] : 464 Разрешение коллизий посредством связывания со связанным списком является распространенным методом реализации хэш-таблиц. Пусть и будут хэш-таблицей и узлом соответственно, операция включает следующее: [15] : 258
Chained-Hash-Insert( T , k ) вставляет x в начало связанного списка T [ h ( k )]Chained-Hash-Search( T , k ) ищет элемент с ключом k в связанном списке T [ h ( k )]Chained-Hash-Delete( T , k ) удалить x из связанного списка T [ h ( k )]
Если элемент сопоставим либо численно , либо лексически и вставлен в список с сохранением общего порядка , это приводит к более быстрому завершению безуспешных поисков. [20] : 520–521
Если ключи упорядочены , может быть эффективным использование « самоорганизующихся » концепций, таких как использование самобалансирующегося бинарного дерева поиска , с помощью которого теоретически наихудший случай может быть сведен к , хотя это вносит дополнительные сложности. [20] : 521
В динамическом идеальном хешировании двухуровневые хеш-таблицы используются для снижения сложности поиска, чтобы гарантировать ее в худшем случае. В этой технике блоки записей организованы как идеальные хеш-таблицы со слотами, обеспечивающими постоянное время поиска в худшем случае и низкое амортизированное время для вставки. [21] Исследование показывает, что раздельное цепочечное связывание на основе массива на 97% более производительно по сравнению со стандартным методом связанного списка при большой нагрузке. [22] : 99
Такие методы, как использование дерева слияния для каждого сегмента, также приводят к постоянному времени для всех операций с высокой вероятностью. [23]
Связанный список отдельной реализации цепочки может не учитывать кэш из- за пространственной локальности — локальности ссылок — когда узлы связанного списка разбросаны по памяти, поэтому обход списка во время вставки и поиска может повлечь за собой неэффективность кэша ЦП . [22] : 91
В вариантах разрешения коллизий с учетом кэширования посредством раздельного связывания динамический массив, который, как оказалось, более дружелюбен к кэшированию, используется в том месте, где обычно развертываются связанный список или самобалансирующиеся двоичные деревья поиска, поскольку непрерывный шаблон распределения массива может быть использован предварительными выборками аппаратного кэша , такими как буфер поиска трансляции , что приводит к сокращению времени доступа и потребления памяти. [24] [25] [26]


Открытая адресация — это еще один метод разрешения коллизий, в котором каждая запись записи хранится в самом массиве ведер, а разрешение хеша выполняется посредством зондирования . Когда необходимо вставить новую запись, ведра проверяются, начиная со слота hashed-to и продолжая в некоторой последовательности зондирования , пока не будет найден свободный слот. При поиске записи ведра сканируются в той же последовательности, пока не будет найдена целевая запись или неиспользуемый слот массива, что указывает на неудачный поиск. [27]
Известные последовательности зондов включают в себя:
Производительность открытой адресации может быть ниже по сравнению с раздельной цепочкой, поскольку последовательность зондирования увеличивается, когда коэффициент загрузки приближается к 1. [9] [22] : 93 Зондирование приводит к бесконечному циклу , если коэффициент загрузки достигает 1 в случае полностью заполненной таблицы. [6] : 471 Средняя стоимость линейного зондирования зависит от способности хэш-функции равномерно распределять элементы по всей таблице, чтобы избежать кластеризации , поскольку образование кластеров приведет к увеличению времени поиска. [6] : 472
Поскольку слоты расположены в последовательных местах, линейное зондирование может привести к лучшему использованию кэша ЦП из-за локальности ссылок, что приводит к снижению задержки памяти . [28]
Объединенное хеширование представляет собой гибрид как отдельной цепочки, так и открытой адресации, в которой блоки или узлы связаны внутри таблицы. [30] : 6–8 Алгоритм идеально подходит для фиксированного выделения памяти . [30] : 4 Коллизия в объединенном хешировании разрешается путем идентификации пустого слота с наибольшим индексом в хеш-таблице, затем в этот слот вставляется коллизионное значение. Блок также связан со слотом вставленного узла, который содержит его коллизионный хеш-адрес. [30] : 8
Кукушечное хеширование — это форма метода разрешения коллизий с открытой адресацией, которая гарантирует сложность поиска в худшем случае и постоянное амортизированное время для вставок. Коллизия разрешается путем поддержания двух хеш-таблиц, каждая из которых имеет свою собственную хеш-функцию, и конфликтующий слот заменяется заданным элементом, а занятый элемент слота перемещается в другую хеш-таблицу. Процесс продолжается до тех пор, пока каждый ключ не займет свое место в пустых ячейках таблиц; если процедура входит в бесконечный цикл — что идентифицируется путем поддержания порогового счетчика циклов — обе хеш-таблицы перехешируются с новыми хеш-функциями, и процедура продолжается. [31] : 124–125
Классическое хеширование — это алгоритм с открытой адресацией, который объединяет элементы кукушкиного хеширования , линейного зондирования и цепочек через понятие соседства ведер — последовательных ведер вокруг любого данного занятого ведра, также называемого «виртуальным» ведерком. [32] : 351–352 Алгоритм разработан для обеспечения лучшей производительности, когда коэффициент загрузки хеш-таблицы превышает 90%; он также обеспечивает высокую пропускную способность в параллельных настройках , поэтому хорошо подходит для реализации изменяемого размера параллельной хеш-таблицы . [32] : 350 Характеристика соседства классического хеширования гарантирует свойство, заключающееся в том, что стоимость поиска нужного элемента из любых заданных ведер в пределах соседства очень близка к стоимости его поиска в самом ведерке; алгоритм пытается быть элементом в его соседстве — с возможными затратами, связанными с перемещением других элементов. [32] : 352
Каждый контейнер в хэш-таблице включает в себя дополнительную «информацию о прыжке» — битовый массив размером H для указания относительного расстояния элемента, который был изначально хэширован в текущий виртуальный контейнер в пределах H -1 записей. [32] : 352 Пусть и будут ключом для вставки и контейнером, в который хэшируется ключ, соответственно; в процедуру вставки вовлечено несколько случаев, так что свойство соседства алгоритма является обязательным: [32] : 352–353 если пуст, элемент вставляется, а самый левый бит битовой карты устанавливается в 1; если не пуст, используется линейное зондирование для поиска пустой ячейки в таблице, битовая карта контейнера обновляется с последующей вставкой; если пустой слот не находится в пределах диапазона соседства , т. е . H -1, последующая своп-обработка и манипуляция битовым массивом информации о прыжке для каждого контейнера выполняется в соответствии с его инвариантными свойствами соседства . [32] : 353
Хеширование Робин Гуда — это алгоритм разрешения коллизий на основе открытой адресации; коллизии разрешаются путем предпочтения смещения элемента, который находится дальше всего — или имеет самую большую длину последовательности зонда (PSL) — от его «домашнего местоположения», т. е. контейнера, в который был хэширован элемент. [33] : 12 Хотя хеширование Робин Гуда не изменяет теоретическую стоимость поиска , оно существенно влияет на дисперсию распределения элементов в контейнерах, [34] : 2, т. е. имеет дело с формированием кластера в хэш-таблице. [35] Каждый узел в хэш-таблице, использующий хэширование Робин Гуда, должен быть расширен для хранения дополнительного значения PSL. [36] Пусть будет ключом для вставки, будет (инкрементной) длиной PSL , будет хэш-таблицей и будет индексом, процедура вставки выглядит следующим образом: [33] : 12–13 [37] : 5
Повторные вставки приводят к росту числа записей в хэш-таблице, что, соответственно, увеличивает коэффициент загрузки; для поддержания амортизированной производительности операций поиска и вставки хэш-таблица динамически изменяет размер, а элементы таблиц повторно хэшируются в сегменты новой хэш-таблицы, [9] поскольку элементы не могут быть скопированы, поскольку изменение размеров таблиц приводит к разному значению хэша из-за операции по модулю . [38] Если хэш-таблица становится «слишком пустой» после удаления некоторых элементов, можно выполнить изменение размера, чтобы избежать чрезмерного использования памяти . [39]
Обычно новая хэш-таблица с размером, вдвое превышающим размер исходной хэш-таблицы, выделяется в частном порядке, и каждый элемент исходной хэш-таблицы перемещается в новую выделенную путем вычисления значений хэша элементов с последующей операцией вставки. Перехэширование просто, но требует больших вычислительных затрат. [40] : 478–479
Некоторые реализации хэш-таблиц, особенно в системах реального времени , не могут окупить цену увеличения хэш-таблицы сразу, поскольку это может прервать критические по времени операции. Если невозможно избежать динамического изменения размера, решением является постепенное изменение размера, чтобы избежать скачка хранилища — обычно на 50% от размера новой таблицы — во время повторного хэширования и избежать фрагментации памяти , которая запускает уплотнение кучи из-за освобождения больших блоков памяти, вызванного старой хэш-таблицей. [41] : 2–3 В таком случае операция повторного хэширования выполняется постепенно путем расширения предыдущего блока памяти, выделенного для старой хэш-таблицы, таким образом, чтобы сегменты хэш-таблицы оставались неизменными. Обычный подход к амортизированному повторному хэшированию включает поддержание двух хэш-функций и . Процесс перехеширования элементов корзины в соответствии с новой хеш-функцией называется очисткой , которая реализуется с помощью шаблона команды путем инкапсуляции таких операций, как , и с помощью оболочки, так что каждый элемент в корзине перехешируется, а его процедура включает следующее: [41] : 3
Линейное хеширование — это реализация хеш-таблицы, которая позволяет динамически увеличивать или уменьшать таблицу по одному блоку за раз. [42]
Производительность хэш-таблицы зависит от способности хэш-функции генерировать квазислучайные числа ( ) для записей в хэш-таблице, где , а обозначает ключ, количество блоков и хэш-функцию, такую что . Если хэш-функция генерирует то же самое для различных ключей ( ), это приводит к коллизии , которая решается различными способами. Постоянная временная сложность ( ) операции в хэш-таблице предполагается при условии, что хэш-функция не генерирует конфликтующие индексы; таким образом, производительность хэш-таблицы прямо пропорциональна способности выбранной хэш-функции рассеивать индексы. [43] : 1 Однако построение такой хэш-функции практически неосуществимо , поэтому реализации зависят от методов разрешения коллизий , специфичных для конкретного случая, для достижения более высокой производительности. [43] : 2
Хэш-таблицы обычно используются для реализации многих типов таблиц в памяти. Они используются для реализации ассоциативных массивов . [29]
Хэш-таблицы также могут использоваться в качестве дисковых структур данных и индексов баз данных (например, в dbm ), хотя в этих приложениях более популярны B-деревья . [44]
Хэш-таблицы могут использоваться для реализации кэшей , вспомогательных таблиц данных, которые используются для ускорения доступа к данным, которые в основном хранятся на более медленных носителях. В этом приложении хэш-коллизии могут быть обработаны путем отбрасывания одной из двух конфликтующих записей — обычно путем стирания старого элемента, который в данный момент хранится в таблице, и перезаписи его новым элементом, так что каждый элемент в таблице имеет уникальное хэш-значение. [45] [46]
Хеш-таблицы могут использоваться при реализации структуры данных множеств , которая может хранить уникальные значения без какого-либо определенного порядка; множество обычно используется для проверки принадлежности значения к коллекции, а не для извлечения элемента. [47]
Таблица транспозиции в сложную хэш-таблицу, в которой хранится информация о каждом разделе, в котором производился поиск. [48]
Многие языки программирования предоставляют функциональность хеш-таблиц либо в виде встроенных ассоциативных массивов, либо в виде стандартных библиотечных модулей.
В JavaScript «объект» — это изменяемая коллекция пар ключ-значение (называемых «свойствами»), где каждый ключ — это либо строка, либо гарантированно уникальный «символ»; любое другое значение, используемое в качестве ключа, сначала приводится к строке. Помимо семи «примитивных» типов данных, каждое значение в JavaScript является объектом. [49] ECMAScript 2015 также добавил Mapструктуру данных, которая принимает произвольные значения в качестве ключей. [50]
C++11 включает unordered_mapв свою стандартную библиотеку для хранения ключей и значений произвольных типов . [51]
Встроенная функция Gomap реализует хеш-таблицу в форме типа . [ 52]
Язык программирования JavaHashSet включает в себя коллекции , HashMap, LinkedHashSet, и LinkedHashMap generic . [53]
Встроенная функция Pythondict реализует хеш-таблицу в виде типа . [ 54]
Встроенная функция RubyHash использует модель открытой адресации, начиная с версии Ruby 2.4. [55]
Язык программирования RustHashMap включает в себя , HashSetкак часть стандартной библиотеки Rust. [56]
Стандартная библиотека .NETHashSet включает в себя и Dictionary, [57] [58] поэтому ее можно использовать из таких языков, как C# и VB.NET . [59]
{{cite web}}: CS1 maint: бот: исходный статус URL неизвестен ( ссылка )




![{\displaystyle A[h(x)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ac75d530b12267b829df7cff8b2ff01a24e61ab0)


























![{\displaystyle x.psl\ \leq \ T[j].psl}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0813eb6a21c2c8a817aa86085d3cf9417f01e8fb)
![{\displaystyle x.psl\ >\ T[j].psl}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d06f4753fda641edd5afb066239100a667124f39)
![{\displaystyle T[j]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb1f9ca1ed801caf88d5004aa3685644667099b6)








![{\displaystyle \mathrm {Таблица} [h_{\text{old}}(\mathrm {key} )]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/afcb195bb40a51be98c16b6d9b930061f3c11682)
![{\displaystyle \mathrm {Таблица} [h_{\text{новый}}(\mathrm {ключ} )]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d8097baf3c9220a1be057b3c86395debce381845)



