ASCII ( / ˈ æ s k iː / ⓘ ASS -kee),[3]:6 , сокращенно отAmerican Standard Code for Information Interchange, представляет собойкодирования символовдля электронной связи. Коды ASCII представляют текст в компьютерах,телекоммуникационном оборудованиии других устройствах. Из-за технических ограничений компьютерных систем на момент его изобретения ASCII имеет всего 128кодовых точек, из которых только 95 являются печатными символами, что серьезно ограничивает его возможности. Современные компьютерные системы эволюционировали, чтобы использоватьUnicode, который имеет миллионы кодовых точек, но первые 128 из них совпадают с набором ASCII.
Управление по присвоению номеров в Интернете (IANA) предпочитает для этой кодировки символов имя US-ASCII . [2]
ASCII — одна из вех IEEE.
ASCII частично был разработан на основе телеграфного кода . Его первое коммерческое использование было в Teletype Model 33 и Teletype Model 35 в качестве семибитного кода телетайпа , продвигаемого службами передачи данных Bell. [ когда? ] Работа над стандартом ASCII началась в мае 1961 года с первого заседания подкомитета X3.2 Американской ассоциации стандартов (ASA) (ныне Американский национальный институт стандартов или ANSI). Первое издание стандарта было опубликовано в 1963 году, [4] [5] подверглось серьезному пересмотру в 1967 году, [6] [7] и последнее обновление произошло в 1986 году . [8] По сравнению с более ранними телеграфными кодами, предложенный Код Bell и ASCII были заказаны для более удобной сортировки (т. е. упорядочения по алфавиту) списков и дополнительных функций для устройств, отличных от телетайпов. [8]
Использование формата ASCII для сетевого обмена было описано в 1969 году. [9] Этот документ был официально повышен до Интернет-стандарта в 2015 году. [10]
Первоначально основанный на (современном) английском алфавите , ASCII кодирует 128 указанных символов в семибитные целые числа, как показано в таблице ASCII в этой статье. [11] Девяносто пять закодированных символов можно распечатать: к ним относятся цифры от 0 до 9 , строчные буквы от a до z , прописные буквы от A до Z и символы пунктуации . Кроме того, исходная спецификация ASCII включала 33 непечатаемых управляющих кода , которые возникли в моделях телетайпов ; большинство из них уже устарели, [12] хотя некоторые из них все еще широко используются, например, возврат каретки , перевод строки и коды табуляции .
Например, строчная буква i будет представлена в кодировке ASCII двоичным числом 1101001 = шестнадцатеричное 69 ( i — девятая буква) = десятичное 105.
Несмотря на то, что ASCII является американским стандартом, он не имеет кодовой точки для цента (¢). Он также не поддерживает английские термины с диакритическими знаками, такие как резюме и халапеньо , или имена собственные с диакритическими знаками, такие как Бейонсе .

Американский стандартный код обмена информацией (ASCII) был разработан под эгидой комитета Американской ассоциации стандартов (ASA), называемого комитетом X3, ее подкомитетом X3.2 (позже X3L2), а затем X3 этого подкомитета. 2.4 рабочая группа (ныне INCITS ). Позже ASA стал Институтом стандартов США (USASI) [3] : 211 и в конечном итоге стал Американским национальным институтом стандартов (ANSI).
С заполненными другими специальными символами и управляющими кодами ASCII был опубликован как ASA X3.4-1963, [5] [13] , оставив 28 позиций кода без какого-либо присвоенного значения, зарезервированных для будущей стандартизации, и один неназначенный контрольный код. [3] : 66, 245 В то время шли споры о том, следует ли использовать больше управляющих символов вместо строчных букв. [3] : 435 Нерешительность длилась недолго: в мае 1963 года Рабочая группа CCITT по новому телеграфному алфавиту предложила назначить строчные буквы палочкам [ a] [14] 6 и 7, [15] и Международной организации по стандартизации TC. 97 SC 2 проголосовали в октябре за включение изменения в свой проект стандарта. [16] Рабочая группа X3.2.4 проголосовала за одобрение перехода на ASCII на своем заседании в мае 1963 года. [17] Расположение строчных букв в палочках [a] [14] 6 и 7 приводило к тому, что символы отличались по битовому шаблону от верхнего регистра на один бит, что упрощало сопоставление символов без учета регистра и конструкцию клавиатур и принтеров.
Комитет X3 внес и другие изменения, включая новые новые символы ( символы фигурных скобок и вертикальной черты ), [18] переименование некоторых управляющих символов (SOM стал началом заголовка (SOH)) и перемещение или удаление других (RU был удален). [3] : 247–248 ASCII был впоследствии обновлен как USAS X3.4-1967, [6] [19] затем USAS X3.4-1968, [20] ANSI X3.4-1977 и, наконец, ANSI X3.4. -1986. [8] [21]
Редакции стандарта ASCII:
В стандарте X3.15 комитет X3 также рассмотрел вопрос о том, как следует передавать ASCII ( сначала младший бит ) [3] : 249–253 [27] и записывать на перфорированную ленту. Они предложили 9-дорожечный стандарт для магнитной ленты и попытались разобраться с некоторыми форматами перфокарт .
Подкомитет X3.2 разработал ASCII на основе более ранних систем кодирования телетайпов. Как и другие кодировки символов , ASCII определяет соответствие между цифровыми битовыми шаблонами и символами символов (т. е. графемами и управляющими символами ). Это позволяет цифровым устройствам взаимодействовать друг с другом, а также обрабатывать, хранить и передавать символьную информацию, например письменную речь. До разработки ASCII используемые кодировки включали 26 буквенных символов, 10 числовых цифр и от 11 до 25 специальных графических символов. Чтобы включить все это, а также управляющие символы, совместимые со стандартом Международного телеграфного алфавита № 2 (ITA2 ) Международного консультативного комитета по телефонии и телеграфике (CCITT ) 1924 года, [28] [29] FIELDATA (1956 [ нужна ссылка ] ) и ранними EBCDIC (1963), для ASCII требовалось более 64 кодов.
ITA2, в свою очередь, был основан на коде Бодо , 5-битном телеграфном коде, изобретенном Эмилем Бодо в 1870 году и запатентованном в 1874 году .
Комитет обсудил возможность функции сдвига (как в ITA2 ), которая позволила бы представить более 64 кодов шестибитным кодом . В сдвинутом коде некоторые коды символов определяют выбор между вариантами следующих кодов символов. Он обеспечивает компактное кодирование, но менее надежен при передаче данных , поскольку ошибка при передаче кода сдвига обычно делает большую часть передачи нечитаемой. Комитет по стандартам отказался от перехода, и поэтому для ASCII требовался как минимум семибитный код. [3] : 215 §13.6, 236 §4.
Комитет рассмотрел восьмибитный код, поскольку восемь битов ( октетов ) позволят двум четырехбитным шаблонам эффективно кодировать две цифры с помощью двоично-десятичного числа . Однако для всей передачи данных потребуется восемь битов, хотя семи может быть достаточно. Комитет проголосовал за использование семибитного кода, чтобы минимизировать затраты, связанные с передачей данных. Поскольку в то время перфорированная лента могла записывать восемь битов в одной позиции, при желании она также позволяла использовать бит четности для проверки ошибок . [3] : 217 §c, 236 §5 Восьмибитные машины (с октетами в качестве собственного типа данных), которые не использовали проверку четности, обычно устанавливают восьмой бит в 0. [30]
Сам код был составлен таким образом, чтобы большинство управляющих кодов и все графические коды были вместе, для простоты идентификации. Первые две так называемые палочки ASCII [a] [14] (32 позиции) были зарезервированы для управляющих символов. [3] : 220, 236 8, 9) Символ «пробел» должен был идти перед графикой, чтобы облегчить сортировку , поэтому он стал позицией 20 hex ; [3] : 237 §10 по той же причине многие специальные знаки, обычно используемые в качестве разделителей, ставились перед цифрами. Комитет решил, что важно поддерживать 64-символьные алфавиты в верхнем регистре , и решил создать шаблон ASCII, чтобы его можно было легко сократить до удобного 64-символьного набора графических кодов, [3] : 228, 237 §14 , как это было сделано в Декабрьский шестибитный код (1963). Поэтому строчные буквы не чередовались с прописными . Чтобы сохранить доступность вариантов для строчных букв и другой графики, специальные и числовые коды располагались перед буквами, а буква A помещалась в шестнадцатеричную позицию 41 , чтобы соответствовать проекту соответствующего британского стандарта. [3] : 238 §18 Цифры 0–9 имеют префикс 011, но оставшиеся 4 бита соответствуют соответствующим значениям в двоичном формате, что упрощает преобразование в двоично-десятичное число (например, 5 в кодировке 011 0101 , где 5 — это 0101 в двоичном формате).
Многие небуквенно-цифровые символы были расположены так, чтобы соответствовать их смещенному положению на пишущих машинках; важная тонкость заключается в том, что они были основаны на механических пишущих машинках, а не на электрических . [31] Механические пишущие машинки следовали стандарту де-факто , установленному Remington No. 2 (1878 г.), первой пишущей машинкой с клавишей Shift, и смещенные значения 23456789-были "#$%_&'() - ранние пишущие машинки опускали 0 и 1 , используя O (заглавную букву o ). и l (строчная буква L ), но 1!пары 0)стали стандартными, как только 0 и 1 стали обычными. Таким образом, в ASCII !"#$%во второй палочке были помещены [a] [14] позиции 1–5, соответствующие цифрам 1–5 в соседней палочке. [a] [14] Однако круглые скобки не могли соответствовать 9 и 0 , поскольку место, соответствующее 0 , было занято пробелом. Это было решено путем удаления _(подчеркивания) из 6 и смещения оставшихся символов, что соответствовало многим европейским пишущим машинкам, в которых круглые скобки помещались с 8 и 9 . Это несоответствие от пишущих машинок привело к появлению клавиатур с битовыми парами , в частности, к Teletype Model 33 , в которой использовалась сдвинутая влево раскладка, соответствующая ASCII, в отличие от традиционных механических пишущих машинок.
Электрические пишущие машинки, особенно IBM Selectric (1961 г.), использовали несколько иную раскладку, которая стала де-факто стандартом для компьютеров – после IBM PC (1981 г.), особенно модели M (1984 г.), – и, таким образом, значения смещения символов на современных клавиатурах не так точно соответствуют таблице ASCII, как предыдущие клавиатуры. Эта /?пара также относится к номеру 2, и эти ,< .>пары использовались на некоторых клавиатурах (в других, включая номер 2, не было смещения ,(запятая) или .(точка), поэтому их можно было использовать в верхнем регистре без отмены сдвига). Однако ASCII разделил ;:пару (начиная с № 2) и переставил математические символы (обычно различные соглашения -* =+) на :* ;+ -=.
Некоторые распространенные в то время символы пишущих машинок не были включены, в частности ½ ¼ ¢, хотя ^ ` ~ были включены в качестве диакритических знаков для международного использования и < >для математического использования вместе с простыми линейными символами \ |(в дополнение к обычным /). Символ @ не использовался в континентальной Европе, и комитет ожидал, что во французском варианте он будет заменен акцентированной À , поэтому @ был помещен в позицию 40 hex , прямо перед буквой A. [3] : 243
Контрольными кодами, которые считались важными для передачи данных, были начало сообщения (SOM), конец адреса (EOA), конец сообщения (EOM), конец передачи (EOT), «кто вы?» (WRU), "ты?" (RU), управление зарезервированным устройством (DC0), синхронное ожидание (SYNC) и подтверждение (ACK). Они были расположены так, чтобы максимизировать расстояние Хэмминга между их битовыми комбинациями. [3] : 243–245.
Порядок ASCII-кода также называют ASCII-бетическим порядком. [32] Сопоставление данных иногда выполняется в этом порядке, а не в «стандартном» алфавитном порядке ( последовательность сопоставления ). Основные отклонения в порядке ASCII:
Промежуточный порядок преобразует прописные буквы в строчные перед сравнением значений ASCII.
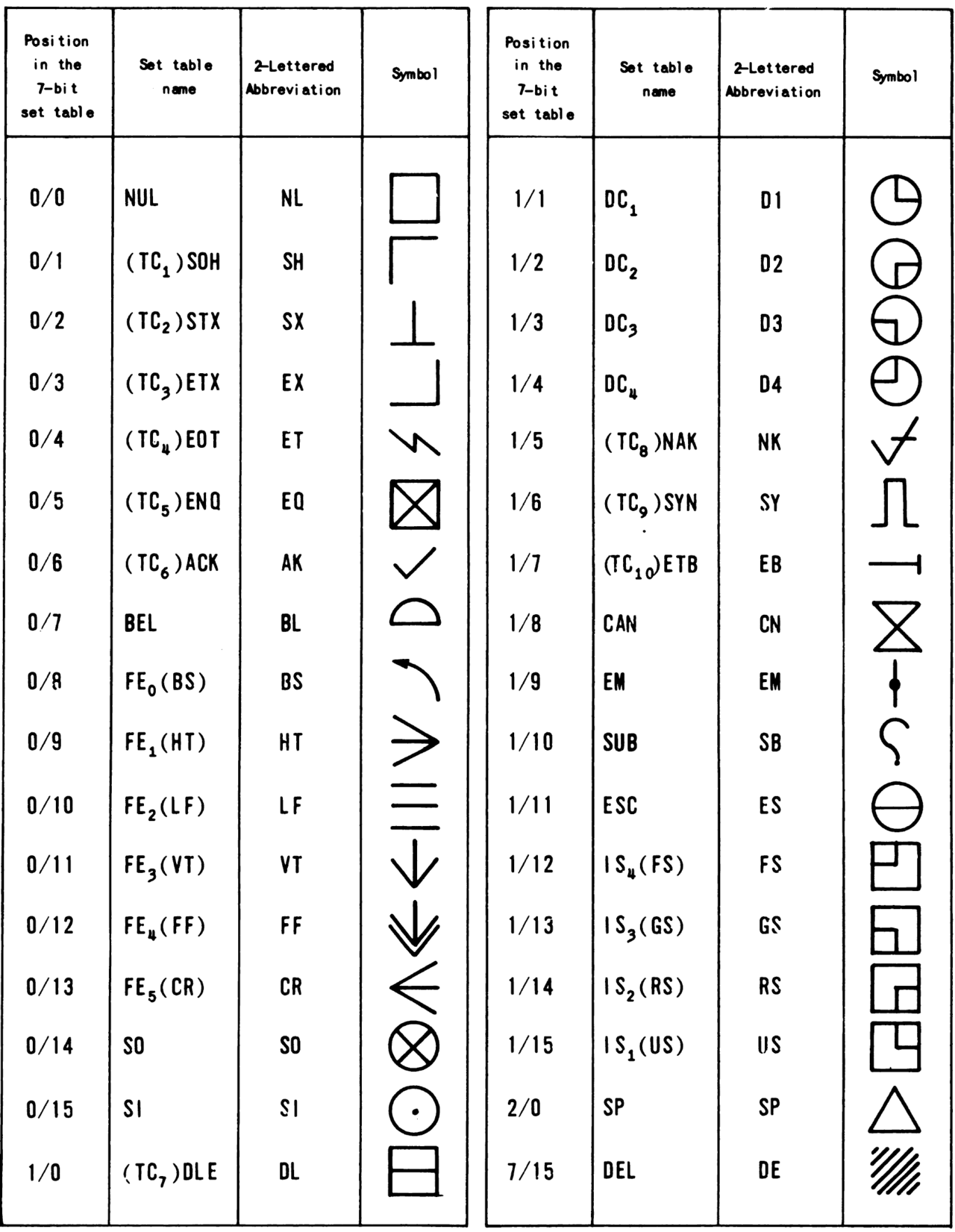
ASCII резервирует первые 32 кодовых символа (десятичные числа 0–31) и последний (десятичный номер 127) для управляющих символов . Это коды, предназначенные для управления периферийными устройствами (например, принтерами ) или для предоставления метаинформации о потоках данных, например, хранящихся на магнитной ленте. Несмотря на свое название, эти кодовые точки не представляют собой печатные символы (т.е. они вообще не символы, а сигналы). В целях отладки им назначаются символы-заполнители (например, приведенные в ISO 2047 и его предшественниках).
Например, символ 0x0A представляет функцию «перевода строки» (которая заставляет принтер продвигать бумагу вперед), а символ 8 представляет собой « возврат ». RFC 2822 называет управляющие символы, которые не включают возврат каретки, перевод строки или пробелы , управляющими символами без пробелов. [33] За исключением управляющих символов, которые предписывают элементарное строковое форматирование, ASCII не определяет какой-либо механизм описания структуры или внешнего вида текста в документе. Другие схемы, такие как языки разметки , адресная страница, макет и форматирование документа.
Исходный стандарт ASCII использовал только короткие описательные фразы для каждого управляющего символа. Вызванная этим двусмысленность иногда была преднамеренной, например, когда символ в терминальной ссылке использовался несколько иначе, чем в потоке данных , а иногда и случайной, например, в стандарте неясно значение слова «удалить».
Вероятно, самым влиятельным устройством, повлиявшим на интерпретацию этих символов, был телетайп модели 33 ASR, который представлял собой печатный терминал с доступной опцией считывания бумажной ленты / перфорации. Бумажная лента была очень популярным носителем для долговременного хранения программ до 1980-х годов, она была менее дорогой и в некотором смысле менее хрупкой, чем магнитная лента. В частности, назначения машин Teletype Model 33 для кодов 17 (control-Q, DC1, также известный как XON), 19 (control-S, DC3, также известный как XOFF) и 127 ( delete ) стали стандартами де-факто . Модель 33 также отличалась тем, что описание Control-G (код 7, BEL, что означает звуковое предупреждение оператора) воспринималось буквально, поскольку устройство содержало настоящий звонок, который звонил, когда получал символ BEL. Поскольку на клавиатуре клавиши O также был изображен символ стрелки влево (из ASCII-1963, в котором этот символ был вместо подчеркивания ), несовместимое использование кода 15 (control-O, сдвиг) интерпретировалось как «удалить предыдущий символ». также был принят во многих ранних системах разделения времени, но в конечном итоге им пренебрегали.
Когда Teletype 33 ASR, оснащенный автоматическим устройством чтения бумажной ленты, получил команду Control-S (XOFF, аббревиатура от выключения передачи), это привело к остановке устройства чтения ленты; прием control-Q (XON, передача включена) привел к возобновлению работы устройства чтения ленты. Этот так называемый метод управления потоком был принят несколькими ранними компьютерными операционными системами в качестве сигнала «квитирования связи», предупреждающего отправителя о прекращении передачи из-за надвигающегося переполнения буфера ; он сохраняется и по сей день во многих системах как метод ручного управления выходом. В некоторых системах Control-S сохраняет свое значение, но Control-Q заменяется вторым Control-S для возобновления вывода.
33 ASR также можно настроить на использование клавиш Control-R (DC2) и Control-T (DC4) для запуска и остановки перфорации ленты; на некоторых устройствах, оснащенных этой функцией, соответствующие буквы управляющего символа на колпачке клавиатуры над буквой были TAPE и TAPE соответственно. [34]
Телетайп не мог переместить печатную головку назад, поэтому на его клавиатуре не было клавиши для отправки BS (возврата). Вместо этого был отмечен ключ RUB OUT, который отправлял код 127 (DEL). Целью этого ключа было стирание ошибок на бумажной ленте, введенной вручную: оператору приходилось нажимать кнопку на перфораторе для резервного копирования, затем набирать рубаут, который пробивал все дырки и заменял ошибку символом, который предполагалось игнорировать. [35] Телетайпы обычно использовались с менее дорогими компьютерами от Digital Equipment Corporation (DEC); этим системам приходилось использовать те клавиши, которые были доступны, и поэтому символ DEL был назначен для стирания предыдущего символа. [36] [37] Из-за этого видеотерминалы DEC (по умолчанию) отправляли символ DEL для клавиши с пометкой «Backspace», в то время как отдельная клавиша с пометкой «Delete» отправляла escape- последовательность ; многие другие конкурирующие терминалы отправляли символ BS в качестве клавиши возврата.
Ранние драйверы tty Unix, в отличие от некоторых современных реализаций, позволяли устанавливать только один символ для стирания предыдущего символа при канонической обработке ввода (где доступен очень простой редактор строк); для этого параметра может быть установлено значение BS или DEL, но не то и другое, что приводит к повторяющимся ситуациям двусмысленности, когда пользователям приходится решать в зависимости от того, какой терминал они используют ( оболочки , которые позволяют редактировать строки, такие как ksh , bash и zsh , понимают оба) . Предположение о том, что ни одна клавиша не отправляла символ BS, позволяло использовать Ctrl+H для других целей, таких как команда префикса «help» в GNU Emacs . [38]
Многим управляющим символам были присвоены значения, совершенно отличные от их первоначальных. Например, символ «esc» (ESC, код 27) изначально предназначался для того, чтобы разрешить отправку других управляющих символов в виде литералов вместо вызова их значения, «escape-последовательности». Это то же значение слова «escape», которое встречается в кодировках URL, строках языка C и других системах, где определенные символы имеют зарезервированное значение. Со временем эта интерпретация была принята и в конечном итоге изменена.
В современном использовании ESC, отправленный на терминал, обычно указывает на начало последовательности команд, которую можно использовать для обращения к курсору, прокрутки региона, установки/запроса различных свойств терминала и многого другого. Обычно они имеют форму так называемого « ESC-кода ANSI » (часто начинающегося с « Introducer Control Sequence Introducer », «CSI», « ESC [ ») из ECMA-48 (1972) и его преемников. Некоторые escape-последовательности не имеют вводящих элементов, например, команда полного сброса VT100 « ESC c ». [39]
Напротив, ESC, считываемый с терминала, чаще всего используется как внеполосный символ, используемый для завершения операции или специального режима, как в текстовых редакторах TECO и vi . В графическом интерфейсе пользователя (GUI) и оконных системах ESC обычно заставляет приложение прерывать текущую операцию или полностью завершать работу.
Присущая многим управляющим символам неоднозначность в сочетании с их историческим использованием создавала проблемы при передаче «обычных текстовых» файлов между системами. Лучшим примером этого является проблема новой строки в различных операционных системах . Телетайпы требовали, чтобы строка текста заканчивалась как «возвратом каретки» (который перемещает печатающую головку в начало строки), так и «переводом строки» (который продвигает бумагу на одну строку без перемещения печатающей головки). Название «возврат каретки» происходит от того факта, что на ручной пишущей машинке каретка, удерживающая бумагу, движется, в то время как печатные линейки, ударяющие по ленте, остаются неподвижными. Всю каретку нужно было сдвинуть (вернуть) вправо, чтобы расположить бумагу для следующей строки.
Операционные системы DEC ( OS/8 , RT-11 , RSX-11 , RSTS , TOPS-10 и т. д.) использовали оба символа для обозначения конца строки, чтобы консольное устройство (первоначально телетайпы) работало. К тому времени, когда появились так называемые «стеклянные телетайпы» (позже названные ЭЛТ или «тупые терминалы»), соглашение настолько укоренилось, что обратная совместимость потребовала продолжать ему следовать. Когда Гэри Килдалл создал CP/M , его вдохновили некоторые соглашения об интерфейсе командной строки, используемые в операционной системе DEC RT-11.
До появления PC DOS в 1981 году IBM не имела на это никакого влияния, поскольку в их операционных системах 1970-х годов использовалась кодировка EBCDIC вместо ASCII, и они были ориентированы на ввод перфокарт и вывод на построчный принтер, на котором использовалась концепция «возврата каретки». бессмысленно. PC DOS от IBM (также продаваемая Microsoft как MS-DOS ) унаследовала это соглашение, поскольку во многом основана на CP/M, [40] а Windows , в свою очередь, унаследовала его от MS-DOS.
Требование двух символов для обозначения конца строки вносит ненужную сложность и двусмысленность в интерпретацию каждого символа, когда он встречается сам по себе. Чтобы упростить ситуацию, потоки простых текстовых данных, включая файлы, в Multics использовали только перевод строки (LF) в качестве признака конца строки. [41] : 357 Драйвер tty будет обрабатывать преобразование LF в CRLF на выходе, чтобы файлы можно было напрямую распечатать на терминале, и NL (новая строка), если он часто используется для ссылки на CRLF в документах UNIX . Unix и Unix-подобные системы, а также системы Amiga переняли это соглашение от Multics. С другой стороны, исходные ОС Macintosh , Apple DOS и ProDOS использовали возврат каретки (CR) только в качестве признака завершения строки; однако, поскольку Apple позже заменила эти устаревшие операционные системы своей Unix-подобной операционной системой macOS (ранее называвшейся OS X), они теперь также используют перевод строки (LF). Radio Shack TRS-80 также использовал одиночный CR для завершения линий.
Среди компьютеров, подключенных к ARPANET, были машины под управлением таких операционных систем, как TOPS-10 и TENEX , использующие окончания строк CR-LF; машины под управлением операционных систем, таких как Multics, использующие окончания строк LF; и машины под управлением операционных систем, таких как OS/360 , которые представляли строки в виде количества символов, за которыми следовали символы строки, и которые использовали кодировку EBCDIC, а не ASCII. Протокол Telnet определил ASCII «Виртуальный сетевой терминал» (NVT), так что соединения между хостами с различными соглашениями о завершении строк и наборами символов могли поддерживаться путем передачи стандартного текстового формата по сети. Telnet использовал ASCII вместе с окончаниями строк CR-LF, а программное обеспечение, использующее другие соглашения, могло преобразовывать между местными соглашениями и NVT. [42] Протокол передачи файлов использует протокол Telnet, включая использование сетевого виртуального терминала, для использования при передаче команд и данных в режиме ASCII по умолчанию. [43] [44] Это усложняет реализацию этих протоколов, а также других сетевых протоколов, например тех, которые используются для электронной почты и Всемирной паутины, в системах, не использующих соглашение NVT об окончании строк CR-LF. [45] [46]
Монитор PDP-6, [36] и его преемник PDP-10, TOPS-10, [37] использовали control-Z (SUB) в качестве индикации конца файла для ввода с терминала. Некоторые операционные системы, такие как CP/M, отслеживали длину файла только в дисковых блоках и использовали Control-Z для обозначения конца фактического текста в файле. [47] По этим причинам EOF, или конец файла , использовался в разговорной речи и традиционно как трехбуквенная аббревиатура для Control-Z вместо SUBstitute. Символ конца текста ( ETX ), также известный как control-C , был неуместен по ряду причин, тогда как использование control-Z в качестве управляющего символа для завершения файла аналогично положению буквы Z в конце файла. алфавита и служит очень удобным мнемоническим пособием . Исторически распространенное и до сих пор распространенное соглашение использует соглашение о символах ETX для прерывания и остановки программы через поток входных данных, обычно с клавиатуры.
Драйвер терминала Unix использует символ конца передачи ( EOT ), также известный как control-D, для обозначения конца потока данных.
В языке программирования C и в соглашениях Unix нулевой символ используется для завершения текстовых строк ; такие строки с нулевым завершением могут быть сокращены как ASCIZ или ASCIIZ, где Z означает «ноль».
Другие представления могут использоваться специальным оборудованием, например графика ISO 2047 или шестнадцатеричные числа.
Коды от 20 hex до 7E hex , известные как печатные символы, представляют собой буквы, цифры, знаки препинания и несколько разных символов. Всего имеется 95 печатных символов. [н]
Шестнадцатеричный код 20 , символ «пробел», обозначает пробел между словами, создаваемый клавишей пробела на клавиатуре. Поскольку символ пробела считается невидимым изображением (а не управляющим символом) [3] : 223 [9] , он указан в таблице ниже, а не в предыдущем разделе.
Шестнадцатеричный код 7F соответствует непечатаемому управляющему символу «удалить» (DEL) и поэтому опущен в этой таблице; это описано в таблице предыдущего раздела. В более ранних версиях ASCII вместо символа курсора использовалась стрелка вверх ( шестнадцатеричный 5E ) и стрелка влево вместо подчеркивания ( шестнадцатеричный 5F ). [5] [48]
ASCII был впервые использован в коммерческих целях в 1963 году как семибитный код телетайпа для сети TWX (TeletypeWriter eXchange) компании American Telephone & Telegraph . Первоначально TWX использовал более ранний пятибитный ITA2 , который также использовался конкурирующей системой телетайпа Telex . Боб Бемер представил такие функции, как escape-последовательность . [4] Его британский коллега Хью МакГрегор Росс помог популяризировать эту работу – по словам Бемера, «настолько, что код, который должен был стать ASCII, сначала назывался в Европе кодом Бемера-Росса ». [49] Из-за его обширной работы над ASCII Бемера называли «отцом ASCII». [50]
11 марта 1968 года президент США Линдон Б. Джонсон распорядился, чтобы все компьютеры, приобретенные федеральным правительством США, поддерживали ASCII, заявив: [51] [52] [53]
Я также одобрил рекомендации министра торговли [ Лютера Х. Ходжеса ] относительно стандартов записи Стандартного кода обмена информацией на магнитных и бумажных лентах, когда они используются в компьютерных операциях. Все конфигурации компьютеров и сопутствующего оборудования, внесенные в реестр федерального правительства с 1 июля 1969 года и после этой даты, должны иметь возможность использовать Стандартный код для обмена информацией и форматы, предписанные стандартами на магнитную и бумажную ленты при использовании этих носителей.
ASCII была самой распространенной кодировкой символов во Всемирной паутине до декабря 2007 года, когда ее превзошла кодировка UTF-8 ; UTF-8 обратно совместим с ASCII. [54] [55] [56]
По мере распространения компьютерных технологий по всему миру различные органы по стандартизации и корпорации разработали множество вариантов ASCII, чтобы облегчить выражение неанглийских языков, в которых использовались латинские алфавиты. Некоторые из этих вариантов можно было бы классифицировать как « расширения ASCII », хотя некоторые неправильно используют этот термин для обозначения всех вариантов, включая те, которые не сохраняют карту символов ASCII в 7-битном диапазоне. Более того, расширения ASCII также ошибочно обозначаются как ASCII.
С самого начала своего развития [57] ASCII задумывался как один из нескольких национальных вариантов международного стандарта кодирования символов.
Другие международные организации по стандартизации ратифицировали кодировки символов, такие как ISO 646 (1967), которые идентичны или почти идентичны ASCII, с расширениями для символов за пределами английского алфавита и символов, используемых за пределами Соединенных Штатов, таких как символ фунта стерлингов Соединенного Королевства . (фунтов стерлингов); например, с кодовой страницей 1104 . Почти каждая страна нуждалась в адаптированной версии ASCII, поскольку ASCII удовлетворял потребностям только США и нескольких других стран. Например, в Канаде была своя версия, поддерживающая французские символы.
Многие другие страны разработали варианты ASCII, включающие неанглийские буквы (например , é , ñ , ß , Ł ), символы валюты (например, £ , ¥ ) и т. д. См. также YUSCII (Югославия).
Он будет использовать большинство общих символов, но другим кодовым точкам, зарезервированным для «национального использования», будут назначены другие локально полезные символы. Однако четыре года, прошедшие между публикацией ASCII-1963 и первым принятием международной рекомендации ISO в 1967 году [58], привели к тому, что выбор символов ASCII для национального использования стал фактическим стандартом для всего мира, что вызвало путаницу и несовместимость. как только другие страны начали присваивать этим кодовым точкам свои собственные значения.
ISO/IEC 646, как и ASCII, представляет собой 7-битный набор символов. Он не предоставляет никаких дополнительных кодов, поэтому одни и те же кодовые точки кодируют разные символы в разных странах. Escape-коды были определены для указания того, какой национальный вариант применяется к фрагменту текста, но они использовались редко, поэтому часто было невозможно узнать, с каким вариантом работать и, следовательно, какой символ представляет код, и вообще, текст- В любом случае системы обработки могли справиться только с одним вариантом.
Поскольку символы скобок и фигурных скобок ASCII были присвоены кодовым точкам «национального использования», которые использовались для акцентированных букв в других национальных вариантах ISO / IEC 646, немецкий, французский, шведский и т. Д. Программист использовал свой национальный вариант ISO. /IEC 646, а не ASCII, должен был писать и, следовательно, читать что-то вроде
ä aÄiÜ = 'Ön'; üвместо
{ a[i] = '\n'; }Для решения этой проблемы для ANSI C были созданы триграфы C , хотя их позднее внедрение и непоследовательная реализация в компиляторах ограничивали их использование. Многие программисты использовали на своих компьютерах US-ASCII, поэтому простой текст на шведском, немецком и т. д. (например, в электронной почте или Usenet ) содержал «{, }» и подобные варианты в середине слов, что и получили эти программисты. привыкший. Например, шведский программист, отправляя другому программисту письмо с вопросом, стоит ли ему пойти на обед, может получить в качестве ответа «N{ jag har sm|rg}sar», который должен выглядеть так: «Nä jag har smörgåsar», что означает «Нет, у меня есть бутерброды».
В Японии и Корее, по состоянию на 2020-е годы, по-прежнему [обновлять]используется вариант ASCII, в котором обратная косая черта (шестнадцатеричный 5C) отображается как ¥ ( знак иены в Японии) или ₩ ( знак воны в Корее). Это означает, что, например, путь к файлу C:\Users\Smith отображается как C:¥Users¥Smith (в Японии) или C:₩Users₩Smith (в Корее).
В Европе наборы символов телетекста , являющиеся вариантами ASCII, используются для субтитров телевещания, определенных World System Teletext , и вещания с использованием стандарта DVB-TXT для встраивания телетекста в передачи DVB. [59] В случае, если субтитры изначально были созданы для телетекста и преобразованы, полученные форматы субтитров ограничиваются одними и теми же наборами символов.
В конце концов, когда 8-, 16- и 32-битные (а позже и 64-битные ) компьютеры стали заменять 12- , 18- и 36-битные компьютеры как норму, стало обычным использовать 8-битный байт для хранить каждый символ в памяти, предоставляя возможность использовать расширенные 8-битные родственники ASCII. В большинстве случаев они развивались как настоящие расширения ASCII, оставляя исходное отображение символов нетронутым, но добавляя дополнительные определения символов после первых 128 (т. е. 7-битных) символов.
Для некоторых стран были разработаны 8-битные расширения ASCII, которые включали поддержку символов, используемых на местных языках; например, ISCII для Индии и VISCII для Вьетнама. Компьютеры Kaypro CP/M использовали «верхние» 128 символов греческого алфавита. [ нужна цитата ]
Даже для рынков, где не было необходимости добавлять много символов для поддержки дополнительных языков, производители первых домашних компьютерных систем часто разрабатывали свои собственные 8-битные расширения ASCII для включения дополнительных символов, таких как символы для рисования коробок , полуграфика и видеоигры. спрайты . Часто эти дополнения также заменяли управляющие символы (индекс от 0 до 31, а также индекс 127) еще более специфичными для платформы расширениями. В других случаях дополнительный бит использовался для каких-то других целей, например, для переключения инверсного видео ; этот подход использовался ATASCII , расширением ASCII, разработанным Atari .
Большинство расширений ASCII основаны на ASCII-1967 (текущий стандарт), но некоторые расширения основаны на более раннем ASCII-1963. Например, PETSCII , разработанный Commodore International для своих 8-битных систем, основан на ASCII-1963. Аналогично, многие наборы символов Sharp MZ основаны на ASCII-1963.
IBM определила кодовую страницу 437 для IBM PC , заменив управляющие символы графическими символами, такими как смайлики , и сопоставив дополнительные графические символы с верхними 128 позициями. [60] Корпорация Digital Equipment разработала многонациональный набор символов (DEC-MCS) для использования в популярном терминале VT220 как одно из первых расширений, предназначенных больше для международных языков, чем для блочной графики. Apple определила Mac OS Roman для Macintosh, а Adobe определила стандартную кодировку PostScript для PostScript ; оба набора содержали «международные» буквы, типографские символы и знаки препинания вместо графики, больше похожие на современные наборы символов.
Стандарт ISO/IEC 8859 (полученный на основе DEC-MCS) представляет собой стандарт, который копируется большинством систем (или, по крайней мере, основывается на нем, если не копируется точно). Популярное дополнительное расширение, разработанное Microsoft, Windows-1252 (часто ошибочно обозначаемое как ISO-8859-1 ), добавляло типографские знаки препинания, необходимые для традиционной печати текста. ISO-8859-1, Windows-1252 и исходный 7-битный ASCII были наиболее распространенными кодировками символов во Всемирной паутине до 2008 года, когда их обогнала UTF-8 . [55]
В стандарте ISO/IEC 4873 представлены 32 дополнительных управляющих кода, определенных в шестнадцатеричном диапазоне 80–9F , как часть расширения 7-битной кодировки ASCII до 8-битной системы. [61]
Unicode и универсальный набор символов (UCS) ISO/IEC 10646 имеют гораздо более широкий набор символов, и их различные формы кодирования начали быстро вытеснять ISO/IEC 8859 и ASCII во многих средах. В то время как ASCII ограничен 128 символами, Unicode и UCS поддерживают больше символов, разделяя концепции уникальной идентификации (с использованием натуральных чисел , называемых кодовыми точками ) и кодирования (в 8-, 16- или 32-битные двоичные форматы, называемые UTF- ). 8 , UTF-16 и UTF-32 соответственно).
ASCII был включен в набор символов Unicode (1991) как первые 128 символов, поэтому 7-битные символы ASCII имеют одинаковые числовые коды в обоих наборах. Это обеспечивает обратную совместимость UTF-8 с 7-битным ASCII, поскольку файл UTF-8, содержащий только символы ASCII, идентичен файлу ASCII, содержащему ту же последовательность символов. Что еще более важно, обеспечивается прямая совместимость , поскольку программное обеспечение распознает только 7-битные символы ASCII как специальные и не изменяет байты с установленным старшим битом (как это часто делается для поддержки 8-битных расширений ASCII, таких как ISO-8859-1). сохранит данные UTF-8 без изменений. [62]
^@ !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_``abcdefghijklmnopqrstuvwxyz{|}~Кроме того, он определяет коды для 33 непечатаемых, в основном устаревших управляющих символов, влияющих на обработку текста.
В передаваемом коде используется Международный телеграфный алфавит № 2 (ITA-2), который был введен CCITT в 1924 году.
Использование функции «новой строки» (комбинированного возврата каретки и перевода строки) проще как для человека, так и для машины, чем использование обеих функций для начала новой строки; Американский национальный стандарт X3.4-1968 позволяет коду перевода строки иметь значение новой строки.
Произошло изменение с ASCII 1961 года на ASCII 1968 года. В некоторых компьютерных языках использовались символы ASCII 1961 года, такие как стрелка вверх и стрелка влево. Эти символы исчезли из ASCII 1968 года. Мы работали с Фредом Мокингом, который к тому времени работал в отделе продаж
Teletype
, над печатным цилиндром, который бы скомпрометировал меняющиеся символы, чтобы значения ASCII 1961 года не были полностью потеряны. Символ подчеркивания был сделан скорее клиновидным, чтобы он мог также служить стрелкой влево.