Частота букв — это количество раз, когда буквы алфавита встречаются в среднем в письменной речи . Анализ частоты букв восходит к арабскому математику Аль-Кинди ( ок. 801–873 гг. н.э.), который формально разработал метод взлома шифров . Анализ частоты букв приобрел важное значение в Европе с развитием подвижного шрифта в 1450 году нашей эры, где нужно было оценить количество шрифта, необходимое для каждой формы буквы . Лингвисты используют частотный анализ букв в качестве элементарного метода идентификации языка , где он особенно эффективен для определения того, является ли неизвестная система письма алфавитной, слоговой или идеографической .
Использование частот букв и частотный анализ играют фундаментальную роль в криптограммах и нескольких играх-головоломках со словами, включая Hangman , Scrabble , Wordle [2] и телевизионное игровое шоу Wheel of Fortune . Одно из самых ранних описаний в классической литературе применения знания частоты английских букв для решения криптограммы можно найти в знаменитом рассказе Эдгара Аллана По « Золотой жук », где этот метод успешно применяется для расшифровки сообщения с указанием местоположения. о сокровище, спрятанном капитаном Киддом . [3] [ нужна ссылка ]
Герберт С. Зим в своем классическом вводном учебнике по криптографии « Коды и тайное письмо » приводит частотную последовательность английских букв как « ETAON RISHD LFCMU GYPWB VKJXZQ », а наиболее распространенные пары букв — как «TH HE AN RE ER IN ON AT ND ST ES EN». OF TE ED OR TI HI AS TO», а наиболее распространенные двойные буквы — «LL EE SS OO TT FF RR NN PP CC». [4] Различные способы подсчета могут давать несколько разные порядки.
Частота букв также оказывает сильное влияние на дизайн некоторых раскладок клавиатуры . Наиболее часто встречающиеся буквы размещаются на домашнем ряду пишущей машинки Blickensderfer , раскладки клавиатуры Дворжака , Колемака и других оптимизированных раскладок.

Частота букв в тексте изучалась для использования в криптоанализе и, в частности, частотном анализе , начиная с арабского математика аль-Кинди (ок. 801–873 гг. Н.э.), который формально разработал метод (шифры, которые можно взломать с помощью этого метода). вернитесь хотя бы к шифру Цезаря , изобретенному Юлием Цезарем , [ нужна ссылка ] , чтобы этот метод мог быть исследован в классические времена). Анализ частоты букв приобрел дополнительное значение в Европе с развитием подвижного шрифта в 1450 году нашей эры, где необходимо оценить количество шрифта, необходимое для каждой формы буквы, о чем свидетельствуют различия в размере отсеков для букв в шрифтах типографа.
В основе данного языка не лежит точное распределение частот букв, поскольку все писатели пишут немного по-разному. Однако большинство языков имеют характерное распределение, которое ярко проявляется в более длинных текстах. Даже такие радикальные изменения языка, как от древнеанглийского к современному английскому (считающемуся взаимонепонятным), демонстрируют сильные тенденции в частоте связанных букв: на небольшой выборке библейских отрывков, от наиболее частых к наименее частым, enaid sorhm tgþlwu æcfy ðbpxz из древнеанглийского языка сравнивает to eotha sinrd luymw fgcbp kvjqxz современного английского языка, при этом самые крайние различия, касающиеся форм букв, не являются общими. [5]
Линотипные машины для английского языка предполагали порядок букв, от наиболее распространенного к наименее распространенному, следующий: etaoin shrdlu cmfwyp vbgkqj xz, основываясь на опыте и обычаях ручных наборщиков. Эквивалентом для французского языка было elaoin sdrétu cmfhyp vbgwqj xz .
Если разбить алфавит Морзе на группы букв, для передачи которых требуется равное количество времени, а затем отсортировать эти группы в порядке возрастания, получим e it san hurdm wgvlfbk opxcz jyq . [a] Частота букв использовалась в других телеграфных системах, таких как Кодекс Мюррея .
Подобные идеи используются в современных методах сжатия данных, таких как кодирование Хаффмана .
Частота букв, как и частота слов , обычно варьируется как в зависимости от автора, так и в зависимости от темы. Например, ⟨d⟩ чаще встречается в художественной литературе, поскольку большая часть художественной литературы написана в прошедшем времени, и поэтому большинство глаголов оканчиваются флективным суффиксом -ed / -d . Невозможно написать эссе о рентгеновских лучах, не используя часто ⟨x⟩ . У разных авторов есть привычки, которые могут отразиться на использовании ими букв. Например, стиль письма Хемингуэя заметно отличается от стиля Фолкнера . Буква, биграмма , триграмма , частота слов, длина слова и длина предложения могут рассчитываться для конкретных авторов и использоваться для доказательства или опровержения авторства текстов, даже для авторов, стили которых не так сильно расходятся.
Точные средние частоты букв можно получить только путем анализа большого количества репрезентативного текста. При наличии современных вычислительных средств и коллекций больших текстовых корпусов такие расчеты легко выполнить. Примеры можно взять из различных источников (сообщения в прессе, религиозные тексты, научные тексты и художественная литература), и существуют различия, особенно для художественной литературы в целом, с положением ⟨h⟩ и ⟨i⟩ , причем ⟨h⟩ становится все более распространенным.
Различные диалекты языка также влияют на частоту употребления букв. Например, автор из Соединенных Штатов может создать что-то, в чем ⟨z⟩ встречается чаще, чем автор из Соединенного Королевства, пишущий на ту же тему: такие слова, как «анализировать», «извиниться» и «признать», содержат букву в американском английском, тогда как в британском английском эти же слова пишутся как «анализировать», «извиняться» и «признавать». Это сильно повлияет на частоту употребления буквы ⟨z⟩ , поскольку британские писатели редко используют ее в английском языке. [6]
Буквы «двенадцати лучших» составляют около 80% от общего использования. Буквы «восьмерки лучших» составляют около 65% от общего использования. Частота букв как функция ранга может быть хорошо аппроксимирована несколькими функциями ранга, из которых лучше всего подходит двухпараметрическая функция ранга Кочо/Бета . [7] Другая ранговая функция без регулируемого свободного параметра также достаточно хорошо соответствует распределению частот букв [8] (та же функция использовалась для подбора частоты аминокислот в белковых последовательностях. [9] ) Шпион, использующий шифр VIC или некоторые другие шифры, основанные на шахматной доске, обычно используют мнемонику, такую как «грех ошибиться» (отбрасывая вторую букву «r») [10] [11] или «в один сэр» [12], чтобы запомнить восемь верхних символов.

Есть три способа подсчета частоты букв, которые приводят к совершенно разным диаграммам для распространенных букв. Первый метод, использованный в таблице ниже, заключается в подсчете частоты букв в корневых словах словаря. Во-вторых, при подсчете следует учитывать все варианты слов, такие как «абстрактный», «абстрагируемый» и «абстрагирующий», а не только корневое слово «абстрактный». В результате этой системы буквы типа ⟨s⟩ появляются гораздо чаще, например, при подсчете букв в списках наиболее часто используемых английских слов в Интернете. Последний вариант состоит в подсчете букв на основе частоты их использования в реальных текстах, в результате чего определенные комбинации букв, такие как ⟨th⟩, становятся более распространенными из-за частого использования общих слов, таких как «the», «then», «both», «это» и т. д. Подобные абсолютные показатели частоты использования используются при создании раскладок клавиатуры или частоте букв в старомодных печатных машинах.
Анализ статей в Кратком Оксфордском словаре без учета частоты использования слов дает порядок «EARIOTNSLCUDPMHGBFYWKVXZJQ». [13]
Приведенная ниже таблица частотности букв взята с веб-сайта Павла Мички, на котором цитируется «Криптологическая математика» Роберта Леванда . [14]
По словам Леванда, буквы расположены в порядке убывания от наиболее распространенного к наименее распространенному: etaoinshrdlcumwfgypbvkjxqz . Порядок Леванда немного отличается от других, таких как проект Корнелльского университета Math Explorer, который создал таблицу после измерения 40 000 слов. [15]
В английском языке пробел встречается почти в два раза чаще, чем верхняя буква ( ⟨e⟩ ) [16] , а неалфавитные символы (цифры, знаки препинания и т. д.) в совокупности занимают четвертую позицию (уже включая пробел) между ⟨t⟩ и ⟨a⟩ . [17]
Частота первых букв слов или имен полезна при предварительном назначении места в физических файлах и индексах. [18] При наличии 26 ящиков картотечного шкафа вместо распределения одного ящика на одну букву алфавита в соотношении 1:1 часто бывает полезно использовать более равночастотный буквенный код, назначая одному и тому же несколько низкочастотных букв. ящик (часто один ящик обозначается VWXYZ) и разделить наиболее часто встречающиеся начальные буквы ( ⟨s, a, c⟩ ) на несколько ящиков (часто 6 ящиков Aa-An, Ao-Az, Ca-Cj, Ck- Ч, Са-Си, Сж-Сз). Эта же система используется в некоторых многотомных произведениях, например в некоторых энциклопедиях . Числа резцов — еще одно сопоставление имен с более равночастотным кодом — используются в некоторых библиотеках.
Как общее распределение букв, так и распределение букв в начале слова примерно соответствуют распределению Ципфа и еще более точно соответствуют распределению Юла . [19]
Часто распределение частот первой цифры в каждом элементе данных значительно отличается от общей частоты всех цифр в наборе числовых данных — это наблюдение известно как закон Бенфорда .
Анализ Питером Норвигом слов, которые встречаются 100 000 или более раз в данных Google Книги , расшифрованных с помощью оптического распознавания символов (OCR), среди прочего, определил частоту первых букв английских слов. [20]
*См. İ и I без точки .
На рисунке ниже показано распределение частот 26 наиболее распространенных латинских букв в некоторых языках. Во всех этих языках используется одинаковый алфавит, состоящий из более чем 25 символов.
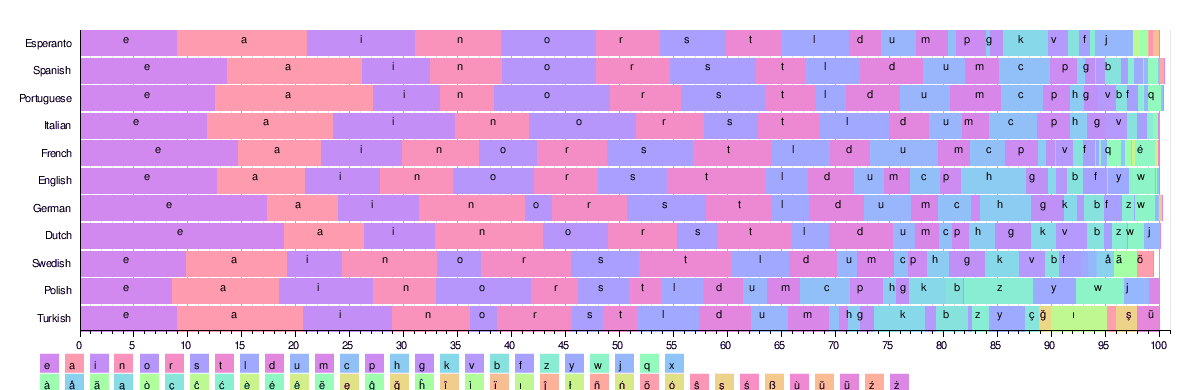
На основании этих таблиц эквивалент ' etaoin shrdlu ' для каждого языка выглядит следующим образом:
Источник — Леланд, Роберт. Криптологическая математика. [sl]: Математическая ассоциация Америки, 2000. 199 стр. ISBN 0-88385-719-7
Полезные таблицы частотности отдельных букв, диграмм, триграмм, тетраграмм и пентаграмм на основе 20 000 слов, которые учитывают комбинации длины слова и положения букв для слов длиной от 3 до 7 букв: