Вычислительная модель, используемая в машинном обучении, основанная на связанных иерархических функциях
Искусственная нейронная сеть — это взаимосвязанная группа узлов, вдохновленная упрощением нейронов в мозге . Здесь каждый круглый узел представляет собой искусственный нейрон , а стрелка представляет собой соединение от выхода одного искусственного нейрона ко входу другого.
ANN состоит из связанных единиц или узлов, называемых искусственными нейронами , которые в общих чертах моделируют нейроны в мозге. Они соединены ребрами , которые моделируют синапсы в мозге. Каждый искусственный нейрон получает сигналы от связанных нейронов, затем обрабатывает их и посылает сигнал другим связанным нейронам. «Сигнал» — это действительное число , а выход каждого нейрона вычисляется некоторой нелинейной функцией суммы его входов, называемой функцией активации . Сила сигнала в каждом соединении определяется весом , который корректируется в процессе обучения.
Обычно нейроны объединяются в слои. Различные слои могут выполнять различные преобразования на своих входах. Сигналы перемещаются от первого слоя ( входного слоя ) к последнему слою ( выходному слою ), возможно, проходя через несколько промежуточных слоев ( скрытых слоев ). Сеть обычно называется глубокой нейронной сетью, если она имеет по крайней мере два скрытых слоя. [3]
Нейронные сети обычно обучаются посредством минимизации эмпирического риска . Этот метод основан на идее оптимизации параметров сети для минимизации разницы или эмпирического риска между прогнозируемым выходом и фактическими целевыми значениями в заданном наборе данных. [4] Для оценки параметров сети обычно используются методы на основе градиента, такие как обратное распространение ошибки . [4] На этапе обучения ИНС обучаются на маркированных обучающих данных путем итеративного обновления своих параметров для минимизации определенной функции потерь . [5] Этот метод позволяет сети обобщать невидимые данные.
История
Ранние работы
Современные глубокие нейронные сети основаны на ранних работах в области статистики, выполненных более 200 лет назад. Простейший вид нейронной сети прямого распространения (FNN) — это линейная сеть, состоящая из одного слоя выходных узлов с линейными функциями активации; входные данные подаются непосредственно на выходы через ряд весов. Сумма произведений весов и входных данных вычисляется в каждом узле. Среднеквадратичные ошибки между этими вычисленными выходными данными и заданными целевыми значениями минимизируются путем создания корректировки весов. Этот метод известен уже более двух столетий как метод наименьших квадратов или линейной регрессии . Он использовался как средство нахождения хорошей грубой линейной подгонки к набору точек Лежандром (1805) и Гауссом (1795) для прогнозирования движения планет. [7] [8] [9] [10] [11]
Исторически цифровые компьютеры, такие как модель фон Неймана, работают посредством выполнения явных инструкций с доступом к памяти несколькими процессорами. Некоторые нейронные сети, с другой стороны, возникли из попыток моделирования обработки информации в биологических системах через структуру коннекционизма . В отличие от модели фон Неймана, коннекционистские вычисления не разделяют память и обработку.
Уоррен Маккалок и Уолтер Питтс [12] (1943) рассмотрели необучаемую вычислительную модель для нейронных сетей. [13] Эта модель проложила путь к разделению исследований на два подхода. Один подход был сосредоточен на биологических процессах, а другой — на применении нейронных сетей к искусственному интеллекту .
В конце 1940-х годов DO Hebb [14] предложил гипотезу обучения , основанную на механизме нейронной пластичности , которая стала известна как обучение Hebbian . Она использовалась во многих ранних нейронных сетях, таких как персептрон Розенблатта и сеть Хопфилда . Фарли и Кларк [15] (1954) использовали вычислительные машины для моделирования сети Hebbian. Другие вычислительные машины нейронных сетей были созданы Рочестером , Холландом, Хабитом и Дудой (1956). [16]
В 1958 году психолог Фрэнк Розенблатт описал персептрон, одну из первых реализованных искусственных нейронных сетей, [17] [18] [19] [20] финансируемую Управлением военно-морских исследований США . [21]
RD Joseph (1960) [22] упоминает еще более раннее устройство, похожее на персептрон, созданное Фарли и Кларком: [10] «Фарли и Кларк из лаборатории Линкольна Массачусетского технологического института фактически опередили Розенблатта в разработке устройства, похожего на персептрон». Однако «они отказались от этой темы». Персептрон вызвал общественный ажиотаж в отношении исследований в области искусственных нейронных сетей, заставив правительство США резко увеличить финансирование. Это способствовало «Золотому веку ИИ», подпитываемому оптимистичными заявлениями ученых-компьютерщиков относительно способности персептронов имитировать человеческий интеллект. [23]
Первые персептроны не имели адаптивных скрытых единиц. Однако Джозеф (1960) [22] также обсуждал многослойные персептроны с адаптивным скрытым слоем. Розенблатт (1962) [24] : раздел 16 цитировал и принимал эти идеи, также отдавая должное работе HD Block и BW Knight. К сожалению, эти ранние усилия не привели к рабочему алгоритму обучения для скрытых единиц, т. е. глубокому обучению .
Прорывы в области глубокого обучения в 1960-х и 1970-х годах
Фундаментальные исследования ИНС проводились в 1960-х и 1970-х годах. Первым работающим алгоритмом глубокого обучения был групповой метод обработки данных , метод обучения произвольно глубоких нейронных сетей, опубликованный Алексеем Ивахненко и Лапой на Украине (1965). Они рассматривали его как форму полиномиальной регрессии [25] или обобщение персептрона Розенблатта [26] . В статье 1971 года описывалась глубокая сеть с восемью слоями, обученная этим методом [27] , которая основана на послойном обучении посредством регрессионного анализа. Избыточные скрытые единицы отсекаются с использованием отдельного набора проверки. Поскольку функции активации узлов являются полиномами Колмогорова-Габора, они также были первыми глубокими сетями с мультипликативными единицами или «воротами». [10]
Первый многослойный персептрон глубокого обучения , обученный стохастическим градиентным спуском [28], был опубликован в 1967 году Шуничи Амари . [29] В компьютерных экспериментах, проведенных учеником Амари Сайто, пятислойный многослойный персептрон с двумя модифицируемыми слоями обучился внутренним представлениям для классификации нелинейно разделимых классов образов. [10] Последующие разработки в области аппаратных средств и настройки гиперпараметров сделали сквозной стохастический градиентный спуск доминирующей в настоящее время методикой обучения.
В 1969 году Кунихико Фукусима представил функцию активации ReLU (выпрямленная линейная единица) . [10] [30] [31] Выпрямитель стал самой популярной функцией активации для глубокого обучения. [32]
Тем не менее, исследования в Соединенных Штатах застопорились после работы Мински и Паперта (1969), [33], которые подчеркнули, что базовые персептроны неспособны обрабатывать схему «исключающее ИЛИ». Это понимание не имело значения для глубоких сетей Ивахненко (1965) и Амари (1967).
Архитектуры глубокого обучения для сверточных нейронных сетей (CNN) со сверточными слоями, слоями понижения дискретизации и репликацией весов начались с Неокогнитрона, представленного Кунихико Фукусимой в 1979 году, хотя и не обученного методом обратного распространения. [34] [35] [36]
Обратное распространение
Обратное распространение — это эффективное применение цепного правила, выведенного Готфридом Вильгельмом Лейбницем в 1673 году [37] для сетей дифференцируемых узлов. Термин «обратно распространяющиеся ошибки» был фактически введен в 1962 году Розенблаттом, [24] но он не знал, как это реализовать, хотя у Генри Дж. Келли был непрерывный предшественник обратного распространения в 1960 году в контексте теории управления . [38] В 1970 году Сеппо Линнайнмаа опубликовал современную форму обратного распространения в своей магистерской диссертации (1970). [39] [40] [10] GM Ostrovski et al. переиздал его в 1971 году. [41] [42] Пол Вербос применил обратное распространение к нейронным сетям в 1982 году [43] [44] (его докторская диссертация 1974 года, переизданная в книге 1994 года, [45] еще не описывала алгоритм [42] ). В 1986 году Дэвид Э. Рамельхарт и др. популяризировали обратное распространение, но не ссылались на оригинальную работу. [46]
Нейронная сеть с задержкой по времени (TDNN) была представлена в 1987 году Алексом Вайбелем для применения CNN к распознаванию фонем. Она использовала свертки, распределение веса и обратное распространение. [48] [49] В 1988 году Вэй Чжан применил обученную методом обратного распространения CNN к распознаванию алфавита. [50]
В 1989 году Янн Лекун и др. создали CNN под названием LeNet для распознавания рукописных почтовых индексов в почте. Обучение заняло 3 дня. [51] В 1990 году Вэй Чжан реализовал CNN на оптическом вычислительном оборудовании. [52] В 1991 году CNN была применена для сегментации объектов медицинских изображений [53] и обнаружения рака груди на маммограммах. [54] LeNet -5 (1998), 7-уровневая сверточная нейронная сеть Яна Лекуна и др., которая классифицирует цифры, применялась несколькими банками для распознавания рукописных цифр на чеках, оцифрованных в изображения размером 32×32 пикселя. [55]
Начиная с 1988 года [56] [57] использование нейронных сетей преобразовало область предсказания структуры белка , в частности, когда первые каскадные сети обучались на профилях (матрицах), полученных путем множественного выравнивания последовательностей . [58]
Рекуррентные нейронные сети
Одним из источников RNN была статистическая механика . В 1972 году Шуничи Амари предложил модифицировать веса модели Изинга с помощью правила обучения Хебба в качестве модели ассоциативной памяти, добавив компонент обучения. [59] Это было популяризировано как сеть Хопфилда Джоном Хопфилдом (1982). [60] Другим источником RNN была нейронаука. Слово «рекуррентный» используется для описания петлеобразных структур в анатомии. В 1901 году Кахаль наблюдал «рекуррентные полукруги» в коре мозжечка . [61] Хебб рассматривал «реверберирующий контур» как объяснение кратковременной памяти. [62] В статье Маккалока и Питтса (1943) рассматривались нейронные сети, содержащие циклы, и отмечалось, что текущая активность таких сетей может зависеть от активности, которая происходила неопределенно далеко в прошлом. [12]
В 1980-х годах обратное распространение не работало хорошо для глубоких RNN. Чтобы преодолеть эту проблему, в 1991 году Юрген Шмидхубер предложил «нейронный секвенсор» или «компрессор нейронной истории» [63] [64] , который ввел важные концепции самоконтролируемого предварительного обучения («P» в ChatGPT ) и дистилляции нейронных знаний . [10] В 1993 году система компрессора нейронной истории решила задачу «Очень глубокого обучения», которая требовала более 1000 последовательных слоев в RNN, развернутых во времени. [65]
В 1991 году в дипломной работе Зеппа Хохрайтера [66] была выявлена и проанализирована проблема исчезающего градиента [66] [67] и предложены рекуррентные остаточные связи для ее решения. Он и Шмидхубер представили долговременную краткосрочную память (LSTM), которая установила рекорды точности в нескольких прикладных областях. [68] [69] Это была еще не современная версия LSTM, которая требовала шлюза забывания, введенного в 1999 году. [70] Она стала выбором по умолчанию для архитектуры RNN.
В период с 2009 по 2012 год ИНС начали выигрывать призы в конкурсах по распознаванию изображений, приближаясь к человеческому уровню производительности в различных задачах, изначально в распознавании образов и распознавании рукописного текста . [75] [76] В 2011 году CNN под названием DanNet [77] [78] Дэна Чиресана, Ули Мейера, Джонатана Маски, Луки Марии Гамбарделлы и Юргена Шмидхубера впервые достигла сверхчеловеческой производительности в конкурсе визуального распознавания образов, превзойдя традиционные методы в 3 раза. [36] Затем она выиграла еще несколько конкурсов. [79] [80] Они также показали, как CNN с максимальным пулом на графическом процессоре значительно улучшили производительность. [81]
В 2012 году Нг и Дин создали сеть, которая научилась распознавать концепции более высокого уровня, такие как кошки, только наблюдая за немаркированными изображениями. [85] Неконтролируемое предварительное обучение и возросшая вычислительная мощность графических процессоров и распределенных вычислений позволили использовать более крупные сети, особенно в задачах распознавания изображений и визуальных образов, что стало известно как «глубокое обучение». [5]
Радиальная базисная функция и вейвлет-сети были введены в 2013 году. Можно показать, что они обеспечивают наилучшие свойства аппроксимации и применяются в приложениях нелинейной идентификации и классификации систем. [86]
Генеративно-состязательная сеть (GAN) ( Ian Goodfellow et al., 2014) [87] стала передовым достижением в генеративном моделировании в период 2014–2018 годов. Принцип GAN был первоначально опубликован в 1991 году Юргеном Шмидхубером , который назвал его «искусственным любопытством»: две нейронные сети соревнуются друг с другом в форме игры с нулевой суммой , где выигрыш одной сети является проигрышем другой сети. [88] [89] Первая сеть представляет собой генеративную модель , которая моделирует распределение вероятностей по выходным шаблонам. Вторая сеть обучается методом градиентного спуска , чтобы предсказывать реакции окружающей среды на эти шаблоны. Превосходное качество изображения достигается с помощью StyleGAN от Nvidia (2018) [90] на основе Progressive GAN Теро Карраса и др. [91] Здесь генератор GAN растет от малого до большого масштаба в пирамидальной форме. Генерация изображений с помощью GAN достигла всеобщего успеха и спровоцировала дискуссии относительно дипфейков . [92] Модели диффузии (2015) [93] с тех пор затмили GAN в генеративном моделировании, представив такие системы, как DALL·E 2 (2022) и Stable Diffusion (2022).
В 2014 году последним словом техники было обучение «очень глубокой нейронной сети» с 20–30 слоями. [94] Наложение слишком большого количества слоев приводило к резкому снижению точности обучения , [95] известному как проблема «деградации». [96] В 2015 году были разработаны две методики обучения очень глубоких сетей: сеть шоссе была опубликована в мае 2015 года, [97] а остаточная нейронная сеть (ResNet) — в декабре 2015 года. [98] [99] ResNet ведет себя как открытая сеть шоссе.
В 2010-х годах была разработана модель seq2seq и добавлены механизмы внимания. Это привело к появлению современной архитектуры Transformer в 2017 году в Attention Is All You Need . [100]
Она требует времени вычислений, квадратичного по размеру контекстного окна. Быстрый контроллер веса Юргена Шмидхубера (1992) [101] масштабируется линейно и, как позже было показано, эквивалентен ненормализованному линейному Transformer. [102] [103] [10]
Transformers все чаще становятся моделью выбора для обработки естественного языка . [104] Многие современные большие языковые модели, такие как ChatGPT , GPT-4 и BERT , используют эту архитектуру.
Модели
Нейрон и миелинизированный аксон с потоком сигнала от входов на дендритах к выходам на окончаниях аксона
ИНС начинались как попытка использовать архитектуру человеческого мозга для выполнения задач, с которыми обычные алгоритмы не имели большого успеха. Вскоре они переориентировались на улучшение эмпирических результатов, отказавшись от попыток оставаться верными своим биологическим предшественникам. ИНС обладают способностью обучаться и моделировать нелинейности и сложные отношения. Это достигается за счет того, что нейроны соединяются в различные схемы, позволяя выходу некоторых нейронов становиться входом других. Сеть образует направленный взвешенный граф . [105]
Искусственная нейронная сеть состоит из смоделированных нейронов. Каждый нейрон соединен с другими узлами посредством связей , подобно биологической связи аксон-синапс-дендрит. Все узлы, соединенные связями, принимают некоторые данные и используют их для выполнения определенных операций и задач над данными. Каждая связь имеет вес, определяющий силу влияния одного узла на другой, [106] позволяя весам выбирать сигнал между нейронами.
Искусственные нейроны
ИНС состоят из искусственных нейронов , которые концептуально получены из биологических нейронов . Каждый искусственный нейрон имеет входы и производит один выход, который может быть отправлен нескольким другим нейронам. [107] Входы могут быть значениями признаков выборки внешних данных, таких как изображения или документы, или они могут быть выходами других нейронов. Выходы конечных выходных нейронов нейронной сети выполняют задачу, такую как распознавание объекта на изображении. [ необходима цитата ]
Чтобы найти выход нейрона, мы берем взвешенную сумму всех входов, взвешенных по весам связей от входов к нейрону. Мы добавляем к этой сумме смещение . [108] Эту взвешенную сумму иногда называют активацией . Затем эта взвешенная сумма проходит через (обычно нелинейную) функцию активации для получения выхода. Начальные входы — это внешние данные, такие как изображения и документы. Конечные выходы выполняют задачу, такую как распознавание объекта на изображении. [109]
Организация
Нейроны обычно организованы в несколько слоев, особенно в глубоком обучении . Нейроны одного слоя соединяются только с нейронами непосредственно предшествующих и непосредственно следующих слоев. Слой, который получает внешние данные, является входным слоем . Слой, который производит конечный результат, является выходным слоем . Между ними находится ноль или более скрытых слоев . Также используются однослойные и бесслоевые сети. Между двумя слоями возможны множественные схемы соединений. Они могут быть «полностью связанными», при этом каждый нейрон в одном слое соединяется с каждым нейроном в следующем слое. Они могут быть объединяющими , когда группа нейронов в одном слое соединяется с одним нейроном в следующем слое, тем самым уменьшая количество нейронов в этом слое. [110] Нейроны только с такими соединениями образуют направленный ациклический граф и известны как сети прямого распространения . [111] В качестве альтернативы сети, которые допускают соединения между нейронами в том же или предыдущих слоях, известны как рекуррентные сети . [112]
Гиперпараметр
Гиперпараметр — это постоянный параметр , значение которого задается до начала процесса обучения. Значения параметров выводятся в процессе обучения. Примерами гиперпараметров являются скорость обучения , количество скрытых слоев и размер пакета. [ необходима цитата ] Значения некоторых гиперпараметров могут зависеть от значений других гиперпараметров. Например, размер некоторых слоев может зависеть от общего количества слоев. [ необходима цитата ]
Обучение
Обучение — это адаптация сети для лучшего выполнения задачи путем рассмотрения выборочных наблюдений. Обучение включает в себя корректировку весов (и необязательных порогов) сети для повышения точности результата. Это делается путем минимизации наблюдаемых ошибок. Обучение завершается, когда изучение дополнительных наблюдений не приводит к полезному снижению частоты ошибок. Даже после обучения частота ошибок обычно не достигает 0. Если после обучения частота ошибок слишком высока, сеть обычно необходимо перепроектировать. На практике это делается путем определения функции стоимости , которая периодически оценивается во время обучения. Пока ее выход продолжает снижаться, обучение продолжается. Стоимость часто определяется как статистика , значение которой может быть только приближено. Выходы на самом деле являются числами, поэтому, когда ошибка мала, разница между выходом (почти наверняка кошка) и правильным ответом (кошка) мала. Обучение пытается уменьшить общую разницу между наблюдениями. Большинство моделей обучения можно рассматривать как прямое применение теории оптимизации и статистической оценки . [105] [113]
Скорость обучения
Скорость обучения определяет размер корректирующих шагов, которые модель предпринимает для корректировки ошибок в каждом наблюдении. [114] Высокая скорость обучения сокращает время обучения, но с меньшей конечной точностью, в то время как низкая скорость обучения занимает больше времени, но с потенциалом большей точности. Оптимизации, такие как Quickprop, в первую очередь направлены на ускорение минимизации ошибок, в то время как другие улучшения в основном пытаются повысить надежность. Чтобы избежать колебаний внутри сети, таких как чередование весов соединений, и улучшить скорость сходимости, уточнения используют адаптивную скорость обучения , которая увеличивается или уменьшается по мере необходимости. [115] Концепция импульса позволяет взвешивать баланс между градиентом и предыдущим изменением таким образом, чтобы корректировка веса в некоторой степени зависела от предыдущего изменения. Импульс, близкий к 0, подчеркивает градиент, в то время как значение, близкое к 1, подчеркивает последнее изменение. [ необходима цитата ]
Обратное распространение — это метод, используемый для корректировки весов связей для компенсации каждой ошибки, обнаруженной во время обучения. Количество ошибок эффективно распределяется между связями. Технически, обратное распространение вычисляет градиент ( производную) функции стоимости , связанной с заданным состоянием относительно весов. Обновления весов могут быть выполнены с помощью стохастического градиентного спуска или других методов, таких как экстремальные обучающие машины , [116] сети «без опор», [117] обучение без возврата, [118] сети «без веса», [119] [120] и неконнекционистские нейронные сети . [ требуется ссылка ]
Контролируемое обучение использует набор парных входов и желаемых выходов. Задача обучения заключается в создании желаемого выхода для каждого входа. В этом случае функция стоимости связана с устранением неправильных выводов. [124] Обычно используемая стоимость — это среднеквадратическая ошибка , которая пытается минимизировать среднеквадратичную ошибку между выходом сети и желаемым выходом. Задачи, подходящие для контролируемого обучения, — это распознавание образов (также известное как классификация) и регрессия (также известная как аппроксимация функции). Контролируемое обучение также применимо к последовательным данным (например, для распознавания почерка, речи и жестов ). Это можно рассматривать как обучение с «учителем» в форме функции, которая обеспечивает непрерывную обратную связь по качеству решений, полученных до сих пор.
Неконтролируемое обучение
В неконтролируемом обучении входные данные задаются вместе с функцией стоимости, некоторой функцией данных и выходом сети. Функция стоимости зависит от задачи (области модели) и любых априорных предположений (неявных свойств модели, ее параметров и наблюдаемых переменных). В качестве тривиального примера рассмотрим модель, где — константа, а стоимость . Минимизация этой стоимости дает значение , равное среднему значению данных. Функция стоимости может быть намного сложнее. Ее форма зависит от приложения: например, в сжатии она может быть связана с взаимной информацией между и , тогда как в статистическом моделировании она может быть связана с апостериорной вероятностью модели с учетом данных (обратите внимание, что в обоих этих примерах эти величины будут максимизированы, а не минимизированы). Задачи, которые попадают в парадигму неконтролируемого обучения, — это общие проблемы оценки ; приложения включают кластеризацию , оценку статистических распределений , сжатие и фильтрацию .
Обучение с подкреплением
В таких приложениях, как видеоигры, актер выполняет ряд действий, получая в целом непредсказуемый ответ от среды после каждого из них. Цель состоит в том, чтобы выиграть в игре, т. е. сгенерировать наиболее положительные (самые дешевые) ответы. В обучении с подкреплением цель состоит в том, чтобы взвесить сеть (разработать политику) для выполнения действий, которые минимизируют долгосрочные (ожидаемые кумулятивные) затраты. В каждый момент времени агент выполняет действие, а среда генерирует наблюдение и мгновенные затраты в соответствии с некоторыми (обычно неизвестными) правилами. Правила и долгосрочные затраты обычно можно оценить только приблизительно. В любой момент времени агент решает, исследовать ли новые действия, чтобы раскрыть их затраты, или использовать предшествующее обучение, чтобы действовать быстрее.
Формально среда моделируется как процесс принятия решений Маркова (MDP) с состояниями и действиями . Поскольку переходы состояний неизвестны, вместо них используются распределения вероятностей: мгновенное распределение стоимости , распределение наблюдения и распределение перехода , в то время как политика определяется как условное распределение по действиям, заданным наблюдениями. Вместе они определяют цепь Маркова (MC). Цель состоит в том, чтобы обнаружить MC с наименьшей стоимостью.
ИНС служат компонентом обучения в таких приложениях. [125] [126] Динамическое программирование в сочетании с ИНС (обеспечивающее нейродинамическое программирование) [127] применялось к таким проблемам, как маршрутизация транспортных средств , [128] видеоигры, управление природными ресурсами [129] [130] и медицина [131] из-за способности ИНС смягчать потери точности даже при уменьшении плотности сетки дискретизации для численного приближения решения задач управления. Задачи, которые попадают в парадигму обучения с подкреплением, — это задачи управления, игры и другие задачи последовательного принятия решений.
Самообучение
Самообучение в нейронных сетях было введено в 1982 году вместе с нейронной сетью, способной к самообучению, названной перекрестной адаптивной матрицей (CAA). [132] Это система только с одним входом, ситуацией s, и только одним выходом, действием (или поведением) a. Она не имеет ни внешнего входного совета, ни внешнего подкрепляющего входа из окружающей среды. CAA вычисляет перекрестным способом как решения о действиях, так и эмоции (чувства) по поводу встреченных ситуаций. Система управляется взаимодействием между познанием и эмоциями. [133] Учитывая матрицу памяти, W =||w(a,s)||, перекрестный алгоритм самообучения на каждой итерации выполняет следующие вычисления:
В ситуации s выполните действие a; Получить последствия ситуации s'; Вычислить эмоцию нахождения в ситуации последствий v(s'); Обновить память кроссбара w'(a,s) = w(a,s) + v(s').
Обратно распространяемое значение (вторичное подкрепление) — это эмоция по отношению к ситуации последствий. CAA существует в двух средах: одна — поведенческая среда, где он себя ведет, а другая — генетическая среда, откуда он изначально и только один раз получает начальные эмоции, которые вот-вот должны встретиться в ситуациях в поведенческой среде. Получив вектор генома (видовой вектор) из генетической среды, CAA научится целенаправленному поведению в поведенческой среде, которая содержит как желательные, так и нежелательные ситуации. [134]
Нейроэволюция
Нейроэволюция может создавать топологии и веса нейронных сетей с использованием эволюционных вычислений . Она конкурентоспособна со сложными подходами градиентного спуска. [135] [136] Одним из преимуществ нейроэволюции является то, что она может быть менее склонна попадать в «тупики». [137]
Стохастическая нейронная сеть
Стохастические нейронные сети, происходящие от моделей Шеррингтона-Киркпатрика, являются типом искусственной нейронной сети, построенной путем введения случайных вариаций в сеть, либо путем придания искусственным нейронам сети стохастических передаточных функций [ требуется ссылка ] , либо путем придания им стохастических весов. Это делает их полезными инструментами для задач оптимизации , поскольку случайные флуктуации помогают сети выходить из локальных минимумов . [138] Стохастические нейронные сети, обученные с использованием байесовского подхода, известны как байесовские нейронные сети . [139]
Доступны два режима обучения: стохастический и пакетный. При стохастическом обучении каждый вход создает корректировку веса. При пакетном обучении веса корректируются на основе пакета входов, накапливая ошибки по всему пакету. Стохастическое обучение вносит «шум» в процесс, используя локальный градиент, рассчитанный по одной точке данных; это снижает вероятность застревания сети в локальных минимумах. Однако пакетное обучение обычно дает более быстрый и стабильный спуск к локальному минимуму, поскольку каждое обновление выполняется в направлении средней ошибки пакета. Распространенным компромиссом является использование «мини-пакетов», небольших пакетов с выборками в каждом пакете, выбранными стохастически из всего набора данных.
Типы
ИНС развились в обширное семейство методов, которые продвинули современное состояние в нескольких областях. Простейшие типы имеют один или несколько статических компонентов, включая количество единиц, количество слоев, веса единиц и топологию . Динамические типы позволяют одному или нескольким из них развиваться посредством обучения. Последнее намного сложнее, но может сократить периоды обучения и дать лучшие результаты. Некоторые типы допускают/требуют, чтобы обучение «контролировалось» оператором, в то время как другие работают независимо. Некоторые типы работают исключительно на аппаратном уровне, в то время как другие являются чисто программными и работают на компьютерах общего назначения.
Некоторые из основных достижений включают в себя:
Сверточные нейронные сети , которые оказались особенно успешными в обработке визуальных и других двумерных данных; [146] [147] где длительная кратковременная память избегает проблемы исчезающего градиента [148] и может обрабатывать сигналы, которые имеют смесь низко- и высокочастотных компонентов, помогая распознавать речь с большим словарным запасом, [149] [150] синтез текста в речь, [151] [152] [153] и фотореалистичные говорящие головы; [154]
Конкурентные сети, такие как генеративные состязательные сети , в которых несколько сетей (различной структуры) конкурируют друг с другом, выполняя такие задачи, как победа в игре [155] или обманывая противника относительно подлинности входных данных. [87]
Проектирование сети
Использование искусственных нейронных сетей требует понимания их характеристик.
Выбор модели: зависит от представления данных и приложения. Параметры модели включают количество, тип и связанность слоев сети, а также размер каждого и тип соединения (полное, объединение и т. д.). Слишком сложные модели обучаются медленно.
Алгоритм обучения : существует множество компромиссов между алгоритмами обучения. Почти любой алгоритм будет хорошо работать с правильными гиперпараметрами [156] для обучения на определенном наборе данных. Однако выбор и настройка алгоритма для обучения на невидимых данных требует значительного экспериментирования.
Надежность : если модель, функция стоимости и алгоритм обучения выбраны правильно, полученная ИНС может стать надежной.
Поиск нейронной архитектуры (NAS) использует машинное обучение для автоматизации проектирования ИНС. Различные подходы к NAS разработали сети, которые хорошо сравниваются с системами, разработанными вручную. Основной алгоритм поиска заключается в предложении модели-кандидата, ее оценке по набору данных и использовании результатов в качестве обратной связи для обучения сети NAS. [157] Доступные системы включают AutoML и AutoKeras. [158] Библиотека scikit-learn предоставляет функции, помогающие в построении глубокой сети с нуля. Затем мы можем реализовать глубокую сеть с помощью TensorFlow или Keras .
Гиперпараметры также должны быть определены как часть дизайна (они не изучаются), определяя такие вопросы, как количество нейронов в каждом слое, скорость обучения, шаг, глубина, рецептивное поле и заполнение (для сверточных нейронных сетей) и т. д. [159]
Фрагмент кода Python предоставляет обзор функции обучения, которая использует в качестве параметров набор данных для обучения, количество единиц скрытого слоя, скорость обучения и количество итераций:
Благодаря своей способности воспроизводить и моделировать нелинейные процессы, искусственные нейронные сети нашли применение во многих дисциплинах. К ним относятся:
Искусственные нейронные сети использовались для диагностики нескольких типов рака [177] [178] и для различения высокоинвазивных линий раковых клеток от менее инвазивных линий, используя только информацию о форме клеток. [179] [180]
ИНС использовались для ускорения анализа надежности инфраструктур, подверженных стихийным бедствиям [181] [182] и для прогнозирования осадки фундамента. [183] Также может быть полезно смягчить наводнение, используя ИНС для моделирования дождевого стока. [184] ИНС также использовались для построения моделей черного ящика в геонауках : гидрологии , [185] [186] моделировании океана и прибрежной инженерии , [187] [188] и геоморфологии . [189] ИНС использовались в кибербезопасности с целью различения законных действий и вредоносных. Например, машинное обучение использовалось для классификации вредоносных программ для Android, [190] для определения доменов, принадлежащих субъектам угроз, и для обнаружения URL-адресов, представляющих риск для безопасности. [191] Ведутся исследования систем ИНС, предназначенных для тестирования на проникновение, обнаружения ботнетов, [192] мошенничества с кредитными картами [193] и сетевых вторжений.
ИНС были предложены в качестве инструмента для решения частных дифференциальных уравнений в физике [194] [195] [196] и моделирования свойств многочастичных открытых квантовых систем . [197] [198] [199] [200] В исследованиях мозга ИНС изучали краткосрочное поведение отдельных нейронов , [201] динамика нейронных цепей возникает из взаимодействий между отдельными нейронами и то, как поведение может возникать из абстрактных нейронных модулей, представляющих собой полные подсистемы. Исследования рассматривали долгосрочную и краткосрочную пластичность нейронных систем и их связь с обучением и памятью от отдельного нейрона до системного уровня.
Можно создать профиль интересов пользователя по фотографиям, используя искусственные нейронные сети, обученные распознавать объекты. [202]
Помимо традиционных приложений, искусственные нейронные сети все чаще используются в междисциплинарных исследованиях, таких как материаловедение. Например, графовые нейронные сети (GNN) продемонстрировали свою способность масштабировать глубокое обучение для открытия новых стабильных материалов, эффективно предсказывая общую энергию кристаллов. Это приложение подчеркивает адаптивность и потенциал ANN в решении сложных проблем за пределами сфер предиктивного моделирования и искусственного интеллекта, открывая новые пути для научных открытий и инноваций. [203]
Специфическая рекуррентная архитектура с рациональными -значными весами (в отличие от действительных -значных весов полной точности) имеет мощность универсальной машины Тьюринга , [204] используя конечное число нейронов и стандартные линейные соединения. Кроме того, использование иррациональных значений для весов приводит к машине с супер-тьюринговой мощностью. [205] [206] [ неудавшаяся проверка ]
Емкость
Свойство «емкости» модели соответствует ее способности моделировать любую заданную функцию. Оно связано с объемом информации, которая может храниться в сети, и с понятием сложности. Сообществу известны два понятия емкости. Информационная емкость и измерение VC. Информационная емкость персептрона подробно обсуждается в книге сэра Дэвида Маккея [207] , которая обобщает работу Томаса Кавера. [208] Емкость сети стандартных нейронов (не сверточных) можно вывести с помощью четырех правил [209] , которые вытекают из понимания нейрона как электрического элемента. Информационная емкость охватывает функции, моделируемые сетью, учитывая любые данные в качестве входных данных. Второе понятие — измерение VC . Измерение VC использует принципы теории меры и находит максимальную емкость при наилучших возможных обстоятельствах. То есть, учитывая входные данные в определенной форме. Как отмечено в [207] , измерение VC для произвольных входных данных составляет половину информационной емкости персептрона. Измерение VC для произвольных точек иногда называют емкостью памяти. [210]
Конвергенция
Модели могут не сходиться последовательно к одному решению, во-первых, потому что могут существовать локальные минимумы, в зависимости от функции стоимости и модели. Во-вторых, используемый метод оптимизации может не гарантировать сходимости, когда он начинается далеко от любого локального минимума. В-третьих, для достаточно больших данных или параметров некоторые методы становятся непрактичными.
Еще одна проблема, которую стоит упомянуть, заключается в том, что обучение может пересечь некоторую седловую точку , что может привести к сближению в неправильном направлении.
Поведение сходимости некоторых типов архитектур ИНС более изучено, чем других. Когда ширина сети приближается к бесконечности, ИНС хорошо описывается ее разложением Тейлора первого порядка на протяжении всего обучения и, таким образом, наследует поведение сходимости аффинных моделей . [211] [212] Другой пример — когда параметры малы, наблюдается, что ИНС часто подходят целевым функциям от низких до высоких частот. Такое поведение называется спектральным смещением или частотным принципом нейронных сетей. [213] [214] [215] [216] Это явление противоположно поведению некоторых хорошо изученных итеративных численных схем, таких как метод Якоби . Было замечено, что более глубокие нейронные сети более смещены в сторону низкочастотных функций. [217]
Обобщение и статистика
Приложения, целью которых является создание системы, которая хорошо обобщает невиданные примеры, сталкиваются с возможностью переобучения. Это возникает в запутанных или переопределенных системах, когда емкость сети значительно превышает необходимые свободные параметры. Два подхода решают проблему переобучения. Первый заключается в использовании перекрестной проверки и аналогичных методов для проверки наличия переобучения и выбора гиперпараметров для минимизации ошибки обобщения.
Второй способ — использовать некоторую форму регуляризации . Эта концепция возникает в вероятностной (байесовской) структуре, где регуляризация может быть выполнена путем выбора большей априорной вероятности из более простых моделей; но также и в статистической теории обучения, где цель состоит в минимизации двух величин: «эмпирического риска» и «структурного риска», что примерно соответствует ошибке в обучающем наборе и прогнозируемой ошибке в невидимых данных из-за переобучения.
Анализ достоверности нейронной сети
Контролируемые нейронные сети, использующие функцию стоимости среднеквадратической ошибки (MSE), могут использовать формальные статистические методы для определения достоверности обученной модели. MSE на проверочном наборе может использоваться в качестве оценки дисперсии. Это значение затем может использоваться для расчета доверительного интервала выходных данных сети, предполагая нормальное распределение . Анализ достоверности, выполненный таким образом, является статистически достоверным, пока выходное распределение вероятностей остается прежним, а сеть не изменяется.
Назначая функцию активации softmax , обобщение логистической функции , на выходном слое нейронной сети (или компонент softmax в компонентной сети) для категориальных целевых переменных, выходные данные можно интерпретировать как апостериорные вероятности. Это полезно в классификации, поскольку дает меру определенности в классификациях.
Функция активации softmax:
Критика
Обучение
Распространенная критика нейронных сетей, особенно в робототехнике, заключается в том, что они требуют слишком много обучающих образцов для работы в реальном мире. [218]
Любая обучающаяся машина нуждается в достаточном количестве репрезентативных примеров для того, чтобы уловить базовую структуру, которая позволяет ей обобщать новые случаи. Потенциальные решения включают случайное перемешивание обучающих примеров, используя числовой алгоритм оптимизации, который не делает слишком больших шагов при изменении сетевых соединений после примера, группирование примеров в так называемые мини-пакеты и/или введение рекурсивного алгоритма наименьших квадратов для CMAC . [144]
Дин Померло использует нейронную сеть для обучения роботизированного транспортного средства вождению по нескольким типам дорог (однополосным, многополосным, грунтовым и т. д.), и большая часть его исследований посвящена экстраполяции нескольких обучающих сценариев из одного обучающего опыта и сохранению разнообразия прошлых обучающих данных, чтобы система не переобучалась (например, если ей предъявляют серию правых поворотов — она не должна учиться всегда поворачивать направо). [219]
Теория
Центральное утверждение [ требуется ссылка ] об ИНС заключается в том, что они воплощают новые и мощные общие принципы обработки информации. Эти принципы плохо определены. Часто утверждается [ кем? ] , что они возникают из самой сети. Это позволяет описывать простую статистическую ассоциацию (основную функцию искусственных нейронных сетей) как обучение или распознавание. В 1997 году Александр Дьюдни , бывший обозреватель Scientific American , прокомментировал, что в результате искусственные нейронные сети обладают «качеством чего-то за бесценок, которое придает особую ауру лени и отчетливое отсутствие любопытства относительно того, насколько хороши эти вычислительные системы. Никакая человеческая рука (или разум) не вмешиваются; решения находятся как по волшебству; и никто, кажется, ничему не научился». [220] Один из ответов Дьюдни заключается в том, что нейронные сети успешно использовались для решения многих сложных и разнообразных задач, начиная от автономного управления самолетом [221] и заканчивая обнаружением мошенничества с кредитными картами и освоением игры в го .
Технологический писатель Роджер Бриджмен прокомментировал:
Нейронные сети, например, оказались на скамье подсудимых не только потому, что их разрекламировали до небес (а что не разрекламировали?), но и потому, что можно создать успешную сеть, не понимая, как она работает: набор чисел, описывающих ее поведение, по всей вероятности, будет «непрозрачной, нечитаемой таблицей... бесполезной как научный ресурс».
Несмотря на его решительное заявление о том, что наука не является технологией, Дьюдни, похоже, здесь принижает нейронные сети как плохую науку, когда большинство из тех, кто их разрабатывает, просто пытаются быть хорошими инженерами. Нечитаемая таблица, которую могла бы прочитать полезная машина, все равно была бы весьма ценной. [222]
Хотя верно, что анализ того, что было изучено искусственной нейронной сетью, сложен, сделать это гораздо проще, чем анализировать то, что было изучено биологической нейронной сетью. Более того, недавний акцент на объяснимости ИИ способствовал разработке методов, в частности, основанных на механизмах внимания , для визуализации и объяснения изученных нейронных сетей. Кроме того, исследователи, занимающиеся изучением алгоритмов обучения для нейронных сетей, постепенно открывают общие принципы, которые позволяют обучающейся машине быть успешной. Например, Бенджио и ЛеКун (2007) написали статью о локальном и нелокальном обучении, а также о поверхностной и глубокой архитектуре. [223]
Биологический мозг использует как поверхностные, так и глубокие цепи, как сообщает анатомия мозга, [224] демонстрируя широкий спектр инвариантности. Вэн [225] утверждал, что мозг сам себя связывает в значительной степени в соответствии со статистикой сигнала, и поэтому последовательный каскад не может уловить все основные статистические зависимости.
Аппаратное обеспечение
Большие и эффективные нейронные сети требуют значительных вычислительных ресурсов. [226] В то время как мозг имеет аппаратное обеспечение, адаптированное для обработки сигналов через граф нейронов, моделирование даже упрощенного нейрона на архитектуре фон Неймана может потреблять огромные объемы памяти и хранилища. Кроме того, проектировщику часто необходимо передавать сигналы через многие из этих соединений и связанных с ними нейронов, что требует огромной мощности процессора и времени. [ необходима цитата ]
Некоторые утверждают, что возрождение нейронных сетей в двадцать первом веке во многом объясняется достижениями в области аппаратного обеспечения: с 1991 по 2015 год вычислительная мощность, особенно предоставляемая GPGPU (на графических процессорах ), увеличилась примерно в миллион раз, что делает стандартный алгоритм обратного распространения осуществимым для обучения сетей, которые на несколько слоев глубже, чем раньше. [36] Использование ускорителей, таких как ПЛИС и графические процессоры, может сократить время обучения с месяцев до дней. [226] [227]
Нейроморфная инженерия или физическая нейронная сеть напрямую решает аппаратную сложность, создавая нефон-неймановские чипы для прямой реализации нейронных сетей в схемах. Другой тип чипа, оптимизированного для обработки нейронных сетей, называется Tensor Processing Unit , или TPU. [228]
Практические контрпримеры
Анализ того, чему научилась ИНС, намного проще, чем анализ того, чему научилась биологическая нейронная сеть. Более того, исследователи, занимающиеся изучением алгоритмов обучения для нейронных сетей, постепенно открывают общие принципы, которые позволяют обучающейся машине быть успешной. Например, локальное обучение против нелокального и поверхностная архитектура против глубокой. [229]
Гибридные подходы
Сторонники гибридных моделей (объединяющих нейронные сети и символические подходы) говорят, что такая смесь может лучше охватить механизмы человеческого разума. [230] [231]
Смещение набора данных
Нейронные сети зависят от качества данных, на которых они обучаются, поэтому данные низкого качества с несбалансированной репрезентативностью могут привести к обучению модели и закреплению социальных предубеждений. [232] [233] Эти унаследованные предубеждения становятся особенно критическими, когда ИНС интегрируются в реальные сценарии, где данные для обучения могут быть несбалансированными из-за нехватки данных для определенной расы, пола или другого атрибута. [232] Этот дисбаланс может привести к тому, что модель будет иметь неадекватное представление и понимание недостаточно представленных групп, что приведет к дискриминационным результатам, которые усугубляют социальное неравенство, особенно в таких приложениях, как распознавание лиц , процессы найма и обеспечение соблюдения законов . [233] [234] Например, в 2018 году Amazon пришлось отказаться от инструмента рекрутинга, поскольку модель отдавала предпочтение мужчинам, а не женщинам при приеме на работу в сфере разработки программного обеспечения из-за большего числа мужчин, работающих в этой области. [234] Программа будет штрафовать любое резюме со словом «женщина» или названием любого женского колледжа. Однако использование синтетических данных может помочь уменьшить смещение набора данных и увеличить репрезентативность в наборах данных. [235]
Галерея
Однослойная искусственная нейронная сеть прямого распространения. Стрелки, исходящие из , опущены для ясности. В этой сети есть p входов и q выходов. В этой системе значение q-го выхода, , вычисляется как
Двухслойная искусственная нейронная сеть прямого распространения
Искусственная нейронная сеть
График зависимости ИНС
Однослойная искусственная нейронная сеть прямого распространения с 4 входами, 6 скрытыми узлами и 2 выходами. При заданном положении и направлении она выводит значения управления на основе колеса.
Двухслойная искусственная нейронная сеть прямого распространения с 8 входами, 2x8 скрытыми узлами и 2 выходами. Учитывая состояние положения, направление и другие значения среды, она выводит значения управления на основе двигателя.
Параллельная конвейерная структура нейронной сети CMAC. Этот алгоритм обучения может сходиться за один шаг.
Последние достижения и будущие направления
Искусственные нейронные сети (ИНС) претерпели значительные усовершенствования, особенно в их способности моделировать сложные системы, обрабатывать большие наборы данных и адаптироваться к различным типам приложений. Их эволюция за последние несколько десятилетий была отмечена широким спектром приложений в таких областях, как обработка изображений, распознавание речи, обработка естественного языка, финансы и медицина. [ необходима цитата ]
Обработка изображений
В сфере обработки изображений ИНС используются в таких задачах, как классификация изображений, распознавание объектов и сегментация изображений. Например, глубокие сверточные нейронные сети (CNN) играют важную роль в распознавании рукописных цифр, достигая самых современных показателей. [236] Это демонстрирует способность ИНС эффективно обрабатывать и интерпретировать сложную визуальную информацию, что приводит к достижениям в областях от автоматизированного наблюдения до медицинской визуализации. [236]
Распознавание речи
Моделируя речевые сигналы, ИНС используются для таких задач, как идентификация говорящего и преобразование речи в текст. Архитектуры глубоких нейронных сетей внесли значительные улучшения в распознавание слитной речи с большим словарным запасом, превзойдя традиционные методы. [236] [237] Эти достижения позволили разработать более точные и эффективные системы с голосовым управлением, улучшив пользовательские интерфейсы в технологических продуктах. [ необходима цитата ]
Обработка естественного языка
В обработке естественного языка ИНС используются для таких задач, как классификация текста, анализ настроений и машинный перевод. Они позволили разработать модели, которые могут точно переводить между языками, понимать контекст и настроения в текстовых данных и классифицировать текст на основе содержания. [236] [237] Это имеет значение для автоматизированного обслуживания клиентов, модерации контента и технологий понимания языка. [ необходима цитата ]
Системы управления
В области систем управления ИНС используются для моделирования динамических систем для таких задач, как идентификация системы, проектирование управления и оптимизация. Например, глубокие нейронные сети прямого распространения важны в приложениях идентификации и управления системой. [ необходима цитата ]
В сфере инвестирования ИНС могут обрабатывать огромные объемы финансовых данных, распознавать сложные закономерности и прогнозировать тенденции фондового рынка, помогая инвесторам и риск-менеджерам принимать обоснованные решения. [236]
В кредитном скоринге ИНС предлагают основанные на данных персонализированные оценки кредитоспособности, повышая точность прогнозов дефолта и автоматизируя процесс кредитования. [237]
ИНС требуют высококачественных данных и тщательной настройки, а их природа «черного ящика» может создавать проблемы в интерпретации. Тем не менее, продолжающиеся достижения показывают, что ИНС продолжают играть роль в финансах, предлагая ценные идеи и улучшая стратегии управления рисками . [ необходима цитата ]
Лекарство
ИНС способны обрабатывать и анализировать обширные наборы медицинских данных. Они повышают точность диагностики, особенно за счет интерпретации сложных медицинских изображений для раннего выявления заболеваний и прогнозирования результатов для пациентов для персонализированного планирования лечения. [237] В разработке лекарств ИНС ускоряют идентификацию потенциальных кандидатов на лекарства и прогнозируют их эффективность и безопасность, значительно сокращая время и затраты на разработку. [236] Кроме того, их применение в персонализированной медицине и анализе данных здравоохранения позволяет разрабатывать индивидуальные терапии и эффективно управлять уходом за пациентами. [237] Текущие исследования направлены на решение оставшихся проблем, таких как конфиденциальность данных и интерпретируемость моделей, а также на расширение сферы применения ИНС в медицине. [ необходима цитата ]
Создание контента
Такие ИНС, как генеративно-состязательные сети ( GAN ) и трансформаторы, используются для создания контента во многих отраслях. [238] Это связано с тем, что модели глубокого обучения способны изучать стиль художника или музыканта из огромных наборов данных и генерировать совершенно новые произведения искусства и музыкальные композиции. Например, DALL-E — это глубокая нейронная сеть, обученная на 650 миллионах пар изображений и текстов по всему Интернету, которая может создавать произведения искусства на основе текста, введенного пользователем. [239] В области музыки трансформаторы используются для создания оригинальной музыки для рекламных роликов и документальных фильмов через такие компании, как AIVA и Jukedeck . [240] В маркетинговой индустрии генеративные модели используются для создания персонализированной рекламы для потребителей. [238] Кроме того, крупные кинокомпании сотрудничают с технологическими компаниями для анализа финансового успеха фильма, например, партнерство между Warner Bros. и технологической компанией Cinelytic, созданное в 2020 году. [241] Кроме того, нейронные сети нашли применение в создании видеоигр, где неигровые персонажи (NPC) могут принимать решения на основе всех персонажей, которые в данный момент находятся в игре. [242]
^ Hardesty L (14 апреля 2017 г.). «Объяснение: Нейронные сети». MIT News Office. Архивировано из оригинала 18 марта 2024 г. Получено 2 июня 2022 г.
^ Yang Z, Yang Z (2014). Комплексная биомедицинская физика. Каролинский институт, Стокгольм, Швеция: Elsevier. стр. 1. ISBN978-0-444-53633-4. Архивировано из оригинала 28 июля 2022 г. . Получено 28 июля 2022 г. .
^ Bishop CM (17 августа 2006 г.). Распознавание образов и машинное обучение . Нью-Йорк: Springer. ISBN978-0-387-31073-2.
^ ab Вапник ВН, Вапник ВН (1998). Природа статистической теории обучения (Исправленное 2-е издание. ред.). Нью-Йорк Берлин Гейдельберг: Springer. ISBN978-0-387-94559-0.
^ ab Ian Goodfellow и Yoshua Bengio и Aaron Courville (2016). Глубокое обучение. MIT Press. Архивировано из оригинала 16 апреля 2016 года . Получено 1 июня 2016 года .
^ Ферри, К., Кайзер, С. (2019). Нейронные сети для младенцев . Справочники. ISBN978-1-4926-7120-6.
^ Мэнсфилд Мерриман, «Список работ, относящихся к методу наименьших квадратов»
^ Stigler SM (1981). «Гаусс и изобретение наименьших квадратов». Ann. Stat . 9 (3): 465–474. doi : 10.1214/aos/1176345451 .
^ Bretscher O (1995). Линейная алгебра с приложениями (3-е изд.). Upper Saddle River, NJ: Prentice Hall.
^ abcdefgh Шмидхубер Дж. (2022). «Аннотированная история современного ИИ и глубокого обучения». arXiv : 2212.11279 [cs.NE].
^ Stigler SM (1986). История статистики: измерение неопределенности до 1900 года . Кембридж: Гарвард. ISBN0-674-40340-1.
^ ab McCulloch WS, Pitts W (декабрь 1943 г.). «Логическое исчисление идей, имманентных нервной деятельности». The Bulletin of Mathematical Biophysics . 5 (4): 115–133. doi :10.1007/BF02478259. ISSN 0007-4985.
^ Клини С. (1956). «Представление событий в нервных сетях и конечных автоматах». Annals of Mathematics Studies . № 34. Princeton University Press. стр. 3–41 . Получено 17 июня 2017 г.
^ Хебб Д. (1949). Организация поведения. Нью-Йорк: Wiley. ISBN978-1-135-63190-1.
^ Фарли Б., У. А. Кларк (1954). «Моделирование самоорганизующихся систем с помощью цифрового компьютера». Труды IRE по теории информации . 4 (4): 76–84. doi :10.1109/TIT.1954.1057468.
^ Rochester N, JH Holland, LH Habit, WL Duda (1956). «Проверки теории сборки клеток в действии мозга с использованием большого цифрового компьютера». IRE Transactions on Information Theory . 2 (3): 80–93. doi :10.1109/TIT.1956.1056810.
^ Хейкин (2008) Нейронные сети и обучающиеся машины, 3-е издание
^ Розенблатт Ф. (1958). «Персептрон: вероятностная модель хранения и организации информации в мозге». Psychological Review . 65 (6): 386–408. CiteSeerX 10.1.1.588.3775 . doi :10.1037/h0042519. PMID 13602029. S2CID 12781225.
^ Вербос П. (1975). За пределами регрессии: новые инструменты для прогнозирования и анализа в поведенческих науках.
^ Розенблатт Ф. (1957). «Персептрон — воспринимающий и распознающий автомат». Отчет 85-460-1 . Корнеллская авиационная лаборатория.
^ Олазаран М (1996). «Социологическое исследование официальной истории спора о персептронах». Социальные исследования науки . 26 (3): 611–659. doi :10.1177/030631296026003005. JSTOR 285702. S2CID 16786738.
^ Джозеф РД (1960). Вклад в теорию персептрона, Отчет Корнельской авиационной лаборатории № VG-11 96--G-7, Буффало .
^ Рассел, Стюарт, Норвиг, Питер (2010). Искусственный интеллект: современный подход (PDF) (3-е изд.). Соединенные Штаты Америки: Pearson Education. стр. 16–28. ISBN978-0-13-604259-4.
^ ab Rosenblatt F (1962). Принципы нейродинамики . Spartan, Нью-Йорк.
^ Ивахненко АГ, Лапа ВГ (1967). Кибернетика и методы прогнозирования. American Elsevier Publishing Co. ISBN978-0-444-00020-0.
^ Ивахненко А (март 1970). «Эвристическая самоорганизация в задачах технической кибернетики». Automatica . 6 (2): 207–219. doi :10.1016/0005-1098(70)90092-0.
^ Ивахненко А (1971). "Polynomial theory of complex systems" (PDF) . IEEE Transactions on Systems, Man, and Cybernetics . SMC-1 (4): 364–378. doi :10.1109/TSMC.1971.4308320. Архивировано (PDF) из оригинала 29 августа 2017 г. . Получено 5 ноября 2019 г. .
^ Роббинс Х. , Монро С. (1951). «Метод стохастической аппроксимации». Анналы математической статистики . 22 (3): 400. doi : 10.1214/aoms/1177729586 .
^ Фукусима К (1969). «Извлечение визуальных признаков с помощью многослойной сети аналоговых пороговых элементов». Труды IEEE по системной науке и кибернетике . 5 (4): 322–333. doi :10.1109/TSSC.1969.300225.
^ Sonoda S, Murata N (2017). «Нейронная сеть с неограниченными функциями активации — универсальный аппроксиматор». Applied and Computational Harmonic Analysis . 43 (2): 233–268. arXiv : 1505.03654 . doi : 10.1016/j.acha.2015.12.005. S2CID 12149203.
^ Рамачандран П., Баррет З., Куок В.Л. (16 октября 2017 г.). «Поиск функций активации». arXiv : 1710.05941 [cs.NE].
^ Минский М, Паперт С (1969). Персептроны: Введение в вычислительную геометрию. MIT Press. ISBN978-0-262-63022-1.
^ ab Fukushima K (1979). "Нейронная сетевая модель для механизма распознавания образов, не зависящего от сдвига положения — Неокогнитрон". Trans. IECE (на японском языке) . J62-A (10): 658–665. doi :10.1007/bf00344251. PMID 7370364. S2CID 206775608.
^ Фукусима К (1980). «Неокогнитрон: самоорганизующаяся модель нейронной сети для механизма распознавания образов, не зависящего от смещения положения». Biol. Cybern . 36 (4): 193–202. doi :10.1007/bf00344251. PMID 7370364. S2CID 206775608.
^ abc Schmidhuber J (2015). «Глубокое обучение в нейронных сетях: обзор». Neural Networks . 61 : 85–117. arXiv : 1404.7828 . doi : 10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509.
^ Лейбниц ГВ (1920). Ранние математические рукописи Лейбница: Перевод с латинских текстов, опубликованных Карлом Иммануэлем Герхардтом с критическими и историческими примечаниями (Лейбниц опубликовал цепное правило в мемуарах 1676 года). Open Court Publication Company. ISBN9780598818461.
^ Келли Х. Дж. (1960). «Градиентная теория оптимальных траекторий полета». ARS Journal . 30 (10): 947–954. doi :10.2514/8.5282.
^ Linnainmaa S (1970). Представление кумулятивной ошибки округления алгоритма как разложения Тейлора локальных ошибок округления (Masters) (на финском языке). Университет Хельсинки. стр. 6–7.
^ Linnainmaa S (1976). «Разложение Тейлора накопленной ошибки округления». BIT Numerical Mathematics . 16 (2): 146–160. doi :10.1007/bf01931367. S2CID 122357351.
^ Островский, ГМ, Волин, ЮМ и Борис, ВВ (1971). О вычислении производных. Wiss. Z. Tech. Hochschule for Chemistry, 13:382–384.
^ ab Schmidhuber J (25 октября 2014 г.). «Кто изобрел обратное распространение?». IDSIA, Швейцария. Архивировано из оригинала 30 июля 2024 г. Получено 14 сентября 2024 г.
^ Werbos P (1982). "Применение достижений в нелинейном анализе чувствительности" (PDF) . Моделирование и оптимизация систем . Springer. стр. 762–770. Архивировано (PDF) из оригинала 14 апреля 2016 г. . Получено 2 июля 2017 г. .
^ Андерсон JA, Розенфельд E, ред. (2000). Говорящие сети: устная история нейронных сетей. MIT Press. doi :10.7551/mitpress/6626.003.0016. ISBN978-0-262-26715-1.
^ Werbos PJ (1994). Корни обратного распространения: от упорядоченных производных к нейронным сетям и политическому прогнозированию . Нью-Йорк: John Wiley & Sons. ISBN0-471-59897-6.
^ Rumelhart DE, Hinton GE, Williams RJ (октябрь 1986 г.). «Изучение представлений с помощью обратного распространения ошибок». Nature . 323 (6088): 533–536. Bibcode :1986Natur.323..533R. doi :10.1038/323533a0. ISSN 1476-4687.
^ Фукусима К, Мияке С (1 января 1982 г.). «Неокогнитрон: новый алгоритм распознавания образов, устойчивый к деформациям и сдвигам положения». Pattern Recognition . 15 (6): 455–469. Bibcode : 1982PatRe..15..455F. doi : 10.1016/0031-3203(82)90024-3. ISSN 0031-3203.
^ Waibel A (декабрь 1987 г.). Распознавание фонем с использованием нейронных сетей с задержкой по времени (PDF) . Заседание Института инженеров по электротехнике, информации и связи (IEICE). Токио, Япония.
^ Александр Вайбель и др., Распознавание фонем с использованием нейронных сетей с задержкой по времени. Труды IEEE по акустике, речи и обработке сигналов, том 37, № 3, стр. 328–339, март 1989 г.
^ Чжан В (1988). «Нейронная сеть распознавания образов, инвариантная к сдвигу, и ее оптическая архитектура». Труды ежегодной конференции Японского общества прикладной физики .
^ ЛеКун и др. , «Применение обратного распространения к распознаванию рукописных почтовых индексов», Neural Computation , 1, стр. 541–551, 1989.
^ Чжан В (1990). «Параллельная распределенная модель обработки с локальными пространственно-инвариантными взаимосвязями и ее оптическая архитектура». Прикладная оптика . 29 (32): 4790–7. Bibcode : 1990ApOpt..29.4790Z. doi : 10.1364/AO.29.004790. PMID 20577468.
^ Чжан В (1991). «Обработка изображений эндотелия роговицы человека на основе обучающейся сети». Прикладная оптика . 30 (29): 4211–7. Bibcode : 1991ApOpt..30.4211Z. doi : 10.1364/AO.30.004211. PMID 20706526.
^ Чжан В (1994). «Компьютерное обнаружение кластерных микрокальцификаций на цифровых маммограммах с использованием инвариантной к сдвигу искусственной нейронной сети». Медицинская физика . 21 (4): 517–24. Bibcode : 1994MedPh..21..517Z. doi : 10.1118/1.597177. PMID 8058017.
^ ЛеКун Ю, Леон Ботту, Йошуа Бенджио, Патрик Хаффнер (1998). «Градиентное обучение, применяемое для распознавания документов» (PDF) . Труды IEEE . 86 (11): 2278–2324. CiteSeerX 10.1.1.32.9552 . дои : 10.1109/5.726791. S2CID 14542261 . Проверено 7 октября 2016 г.
^ Цянь, Нин и Терренс Дж. Сейновски. «Предсказание вторичной структуры глобулярных белков с использованием моделей нейронных сетей». Журнал молекулярной биологии 202, № 4 (1988): 865–884.
^ Бор, Хенрик, Якоб Бор, Сёрен Брунак, Родни М. Дж. Коттерилл, Бенни Лаутруп, Лейф Норсков, Оле Х. Олсен и Штеффен Б. Петерсен. «Вторичная структура белка и гомология нейронных сетей. α-спирали в родопсине». Письма ФЕБС 241 (1988): 223–228.
^ Рост, Буркхард и Крис Сандер. «Предсказание вторичной структуры белка с точностью выше 70%». Журнал молекулярной биологии 232, № 2 (1993): 584–599.
^ Амари СИ (ноябрь 1972 г.). «Изучение шаблонов и последовательностей шаблонов с помощью самоорганизующихся сетей пороговых элементов». Труды IEEE по компьютерам . C-21 (11): 1197–1206. doi :10.1109/TC.1972.223477. ISSN 0018-9340.
^ Хопфилд Дж. Дж. (1982). «Нейронные сети и физические системы с возникающими коллективными вычислительными способностями». Труды Национальной академии наук . 79 (8): 2554–2558. Bibcode : 1982PNAS...79.2554H. doi : 10.1073 /pnas.79.8.2554 . PMC 346238. PMID 6953413.
^ Эспиноса-Санчес Х. М., Гомес-Марин А., де Кастро Ф. (5 июля 2023 г.). «Значение нейронауки Кахаля и Лоренте де Но для зарождения кибернетики». The Neuroscientist . doi : 10.1177/10738584231179932. hdl : 10261/348372 . ISSN 1073-8584. PMID 37403768.
^ "reverberating circuit". Oxford Reference . Получено 27 июля 2024 г.
^ Шмидхубер Дж (апрель 1991 г.). «Чанкеры нейронных последовательностей» (PDF) . ТР ФКИ-148, ТУ Мюнхен .
^ Schmidhuber J (1992). «Изучение сложных расширенных последовательностей с использованием принципа сжатия истории (на основе TR FKI-148, 1991)» (PDF) . Neural Computation . 4 (2): 234–242. doi :10.1162/neco.1992.4.2.234. S2CID 18271205.
^ Шмидхубер Дж. (1993). Диссертация на соискание ученой степени: Моделирование и оптимизация систем (PDF) .На странице 150 и далее показано присвоение кредитов по эквиваленту 1200 слоев в развернутой RNN.
^ ab S. Hochreiter., «Untersuchungen zu dynamischen Neuronalen Netzen», Архивировано 6 марта 2015 г. в Wayback Machine , Дипломная работа. Институт ф. Информатика, Технический университет. Мюнхен. Советник: Дж. Шмидхубер , 1991 г.
^ Hochreiter S, et al. (15 января 2001 г.). "Градиентный поток в рекуррентных сетях: сложность изучения долгосрочных зависимостей". В Kolen JF, Kremer SC (ред.). Полевое руководство по динамическим рекуррентным сетям . John Wiley & Sons. ISBN978-0-7803-5369-5. Архивировано из оригинала 19 мая 2024 . Получено 26 июня 2017 .
^ Хохрайтер С. , Шмидхубер Дж. (1 ноября 1997 г.). «Долгая кратковременная память». Neural Computation . 9 (8): 1735–1780. doi :10.1162/neco.1997.9.8.1735. PMID 9377276. S2CID 1915014.
^ Gers F, Schmidhuber J, Cummins F (1999). "Учимся забывать: непрерывное прогнозирование с LSTM". 9-я Международная конференция по искусственным нейронным сетям: ICANN '99 . Том 1999. стр. 850–855. doi :10.1049/cp:19991218. ISBN0-85296-721-7.
^ Ackley DH, Hinton GE, Sejnowski TJ (1 января 1985 г.). «Алгоритм обучения для машин Больцмана». Cognitive Science . 9 (1): 147–169. doi :10.1016/S0364-0213(85)80012-4 (неактивен 7 августа 2024 г.). ISSN 0364-0213.{{cite journal}}: CS1 maint: DOI inactive as of August 2024 (link)
^ Питер Д. , Хинтон GE , Нил Р. М. , Земель RS (1995). «Машина Гельмгольца». Neural Computation . 7 (5): 889–904. doi :10.1162/neco.1995.7.5.889. hdl : 21.11116/0000-0002-D6D3-E . PMID 7584891. S2CID 1890561.
^ Hinton GE , Dayan P , Frey BJ , Neal R (26 мая 1995 г.). «Алгоритм бодрствования-сна для неконтролируемых нейронных сетей». Science . 268 (5214): 1158–1161. Bibcode : 1995Sci...268.1158H. doi : 10.1126/science.7761831. PMID 7761831. S2CID 871473.
^ Интервью 2012 Kurzweil AI, архивировано 31 августа 2018 г. на Wayback Machine с Юргеном Шмидхубером о восьми соревнованиях, выигранных его командой Deep Learning в 2009–2012 гг.
^ "Как био-вдохновленное глубокое обучение продолжает побеждать в соревнованиях | KurzweilAI". kurzweilai.net . Архивировано из оригинала 31 августа 2018 года . Получено 16 июня 2017 года .
^ Cireşan DC, Meier U, Gambardella LM, Schmidhuber J (21 сентября 2010 г.). «Глубокие, большие, простые нейронные сети для распознавания рукописных цифр». Neural Computation . 22 (12): 3207–3220. arXiv : 1003.0358 . doi :10.1162/neco_a_00052. ISSN 0899-7667. PMID 20858131. S2CID 1918673.
^ Ciresan DC, Meier U, Masci J, Gambardella L, Schmidhuber J (2011). "Гибкие, высокопроизводительные сверточные нейронные сети для классификации изображений" (PDF) . Международная объединенная конференция по искусственному интеллекту . doi :10.5591/978-1-57735-516-8/ijcai11-210. Архивировано (PDF) из оригинала 29 сентября 2014 г. . Получено 13 июня 2017 г. .
^ Ciresan D, Giusti A, Gambardella LM, Schmidhuber J (2012). Pereira F, Burges CJ, Bottou L, Weinberger KQ (ред.). Advances in Neural Information Processing Systems 25 (PDF) . Curran Associates, Inc. стр. 2843–2851. Архивировано (PDF) из оригинала 9 августа 2017 г. . Получено 13 июня 2017 г. .
^ Ciresan D, Giusti A, Gambardella L, Schmidhuber J (2013). «Обнаружение митоза на гистологических изображениях рака молочной железы с помощью глубоких нейронных сетей». Медицинские вычисления изображений и компьютерное вмешательство – MICCAI 2013. Конспект лекций по информатике. Том 7908. С. 411–418. doi :10.1007/978-3-642-40763-5_51. ISBN978-3-642-38708-1. PMID 24579167.
^ Ciresan D, Meier U, Schmidhuber J (2012). «Многоколоночные глубокие нейронные сети для классификации изображений». Конференция IEEE 2012 года по компьютерному зрению и распознаванию образов . С. 3642–3649. arXiv : 1202.2745 . doi :10.1109/cvpr.2012.6248110. ISBN978-1-4673-1228-8. S2CID 2161592.
^ Крижевский А., Суцкевер И., Хинтон Г. (2012). «Классификация ImageNet с глубокими сверточными нейронными сетями» (PDF) . NIPS 2012: Системы обработки нейронной информации, Лейк-Тахо, Невада . Архивировано (PDF) из оригинала 10 января 2017 г. . Получено 24 мая 2017 г. .
^ Симонян К, Эндрю З (2014). «Очень глубокие сверточные сети для распознавания изображений большого масштаба». arXiv : 1409.1556 [cs.CV].
^ Szegedy C (2015). «Глубже с извилинами» (PDF) . Cvpr2015 . arXiv : 1409.4842 .
^ Нг А, Дин Дж (2012). «Создание высокоуровневых функций с использованием крупномасштабного неконтролируемого обучения». arXiv : 1112.6209 [cs.LG].
^ ab Billings SA (2013). Нелинейная системная идентификация: методы NARMAX во временной, частотной и пространственно-временной областях . Wiley. ISBN978-1-119-94359-4.
^ ab Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. (2014). Generative Adversarial Networks (PDF) . Труды Международной конференции по системам обработки нейронной информации (NIPS 2014). стр. 2672–2680. Архивировано (PDF) из оригинала 22 ноября 2019 г. . Получено 20 августа 2019 г. .
^ Шмидхубер Дж. (1991). «Возможность реализации любопытства и скуки в нейронных контроллерах построения моделей». Proc. SAB'1991 . MIT Press/Bradford Books. стр. 222–227.
^ Schmidhuber J (2020). «Генеративно-состязательные сети являются особыми случаями искусственного любопытства (1990), а также тесно связаны с минимизацией предсказуемости (1991)». Нейронные сети . 127 : 58–66. arXiv : 1906.04493 . doi : 10.1016/j.neunet.2020.04.008. PMID 32334341. S2CID 216056336.
^ "GAN 2.0: Гиперреалистичный генератор лиц от NVIDIA". SyncedReview.com . 14 декабря 2018 г. . Получено 3 октября 2019 г. .
^ Karras T, Aila T, Laine S, Lehtinen J (26 февраля 2018 г.). «Прогрессивное выращивание GAN для улучшения качества, стабильности и вариативности». arXiv : 1710.10196 [cs.NE].
^ «Prepare, Don't Panic: Synthetic Media and Deepfakes». witness.org. Архивировано из оригинала 2 декабря 2020 г. Получено 25 ноября 2020 г.
^ Sohl-Dickstein J, Weiss E, Maheswaranathan N, Ganguli S (1 июня 2015 г.). «Глубокое неконтролируемое обучение с использованием неравновесной термодинамики» (PDF) . Труды 32-й Международной конференции по машинному обучению . 37. PMLR: 2256–2265. arXiv : 1503.03585 .
^ Симонян К, Зиссерман А (10 апреля 2015 г.), Очень глубокие сверточные сети для крупномасштабного распознавания изображений , arXiv : 1409.1556
^ He K, Zhang X, Ren S, Sun J (2016). «Глубокое изучение выпрямителей: превосходство человеческого уровня в классификации ImageNet». arXiv : 1502.01852 [cs.CV].
^ He K, Zhang X, Ren S, Sun J (10 декабря 2015 г.). Глубокое остаточное обучение для распознавания изображений . arXiv : 1512.03385 .
^ Шривастава Р.К., Грефф К., Шмидхубер Дж. (2 мая 2015 г.). «Дорожные сети». arXiv : 1505.00387 [cs.LG].
^ He K, Zhang X, Ren S, Sun J (2016). Глубокое остаточное обучение для распознавания изображений. Конференция IEEE 2016 года по компьютерному зрению и распознаванию образов (CVPR) . Лас-Вегас, Невада, США: IEEE. стр. 770–778. arXiv : 1512.03385 . doi : 10.1109/CVPR.2016.90. ISBN978-1-4673-8851-1.
^ Linn A (10 декабря 2015 г.). «Исследователи Microsoft выигрывают конкурс компьютерного зрения ImageNet». The AI Blog . Получено 29 июня 2024 г.
^ Васвани А., Шазир Н., Пармар Н., Ушкорейт Дж., Джонс Л., Гомес А.Н. и др. (12 июня 2017 г.). «Внимание — это все, что вам нужно». arXiv : 1706.03762 [cs.CL].
^ Шмидхубер Дж. (1992). «Обучение управлению быстрой памятью с весом: альтернатива рекуррентным сетям» (PDF) . Нейронные вычисления . 4 (1): 131–139. doi :10.1162/neco.1992.4.1.131. S2CID 16683347.
^ Katharopoulos A, Vyas A, Pappas N, Fleuret F (2020). «Трансформаторы — это RNN: быстрые авторегрессионные трансформаторы с линейным вниманием». ICML 2020. PMLR. стр. 5156–5165.
^ Шлаг И, Ири К, Шмидхубер Дж (2021). «Линейные трансформаторы — тайные быстрые весовые программисты». ICML 2021. Springer. стр. 9355–9366.
^ Wolf T, Debut L, Sanh V, Chaumond J, Delangue C, Moi A и др. (2020). «Трансформаторы: современная обработка естественного языка». Труды конференции 2020 года по эмпирическим методам обработки естественного языка: системные демонстрации . стр. 38–45. doi :10.18653/v1/2020.emnlp-demos.6. S2CID 208117506.
^ аб Зелл А (2003). «глава 5.2». Моделирование нейроналера Netze [ Моделирование нейронных сетей ] (на немецком языке) (1-е изд.). Аддисон-Уэсли. ISBN978-3-89319-554-1. OCLC 249017987.
^ Abbod MF (2007). «Применение искусственного интеллекта для лечения урологического рака». Журнал урологии . 178 (4): 1150–1156. doi :10.1016/j.juro.2007.05.122. PMID 17698099.
^ Доусон CW (1998). «Подход к моделированию осадков и стока с использованием искусственных нейронных сетей». Журнал гидрологических наук . 43 (1): 47–66. Bibcode : 1998HydSJ..43...47D. doi : 10.1080/02626669809492102 .
^ "The Machine Learning Dictionary". cse.unsw.edu.au . Архивировано из оригинала 26 августа 2018 года . Получено 4 ноября 2009 года .
^ Ciresan D, Ueli Meier, Jonathan Masci, Luca M. Gambardella, Jurgen Schmidhuber (2011). "Гибкие, высокопроизводительные сверточные нейронные сети для классификации изображений" (PDF) . Труды Двадцать второй Международной совместной конференции по искусственному интеллекту - Том Второй . 2 : 1237–1242. Архивировано (PDF) из оригинала 5 апреля 2022 г. . Получено 7 июля 2022 г. .
^ Зелл А (1994). Simulation Neuronaler Netze [ Моделирование нейронных сетей ] (на немецком языке) (1-е изд.). Аддисон-Уэсли. п. 73. ИСБН3-89319-554-8.
^ Miljanovic M (февраль–март 2012 г.). «Сравнительный анализ рекуррентных и конечных импульсных нейронных сетей в прогнозировании временных рядов» (PDF) . Indian Journal of Computer and Engineering . 3 (1). Архивировано (PDF) из оригинала 19 мая 2024 г. . Получено 21 августа 2019 г. .
^ Kelleher JD, Mac Namee B, D'Arcy A (2020). "7-8". Основы машинного обучения для предиктивной аналитики данных: алгоритмы, рабочие примеры и тематические исследования (2-е изд.). Кембридж, Массачусетс: The MIT Press. ISBN978-0-262-36110-1. OCLC 1162184998.
^ Wei J (26 апреля 2019 г.). «Забудьте о скорости обучения, потери уменьшаются». arXiv : 1905.00094 [cs.LG].
^ Li Y, Fu Y, Li H, Zhang SW (1 июня 2009 г.). «Улучшенный алгоритм обучения нейронной сети обратного распространения с самоадаптивной скоростью обучения». Международная конференция по вычислительному интеллекту и естественным вычислениям 2009 г. Том 1. стр. 73–76. doi :10.1109/CINC.2009.111. ISBN978-0-7695-3645-3. S2CID 10557754.
^ Huang GB, Zhu QY, Siew CK (2006). «Экстремальная обучающая машина: теория и приложения». Neurocomputing . 70 (1): 489–501. CiteSeerX 10.1.1.217.3692 . doi :10.1016/j.neucom.2005.12.126. S2CID 116858.
^ Видроу Б. и др. (2013). «Алгоритм без опоры: новый алгоритм обучения для многослойных нейронных сетей». Neural Networks . 37 : 182–188. doi : 10.1016/j.neunet.2012.09.020. PMID 23140797.
^ Ollivier Y, Charpiat G (2015). «Обучение рекуррентных сетей без возврата». arXiv : 1507.07680 [cs.NE].
^ Hinton GE (2010). "Практическое руководство по обучению ограниченных машин Больцмана". Технический отчет UTML TR 2010-003 . Архивировано из оригинала 9 мая 2021 г. Получено 27 июня 2017 г.
^ Бернард Э. (2021). Введение в машинное обучение. Шампейн: Wolfram Media. стр. 9. ISBN978-1-57955-048-6. Архивировано из оригинала 19 мая 2024 . Получено 22 марта 2023 .
^ Бернард Э. (2021). Введение в машинное обучение. Шампейн: Wolfram Media. стр. 12. ISBN978-1-57955-048-6. Архивировано из оригинала 19 мая 2024 . Получено 22 марта 2023 .
^ Бернард Э. (2021). Введение в машинное обучение. Wolfram Media Inc. стр. 9. ISBN978-1-57955-048-6. Архивировано из оригинала 19 мая 2024 . Получено 28 июля 2022 .
^ Ojha VK, Abraham A, Snášel V (1 апреля 2017 г.). «Метаэвристическое проектирование нейронных сетей прямого распространения: обзор двух десятилетий исследований». Engineering Applications of Artificial Intelligence . 60 : 97–116. arXiv : 1705.05584 . Bibcode : 2017arXiv170505584O. doi : 10.1016/j.engappai.2017.01.013. S2CID 27910748.
^ Доминик, С., Дас, Р., Уитли, Д., Андерсон, К. (июль 1991 г.). "Генетическое обучение с подкреплением для нейронных сетей" . IJCNN-91-Сиэтлская международная совместная конференция по нейронным сетям . IJCNN-91-Сиэтлская международная совместная конференция по нейронным сетям. Сиэтл, Вашингтон, США: IEEE. стр. 71–76. doi :10.1109/IJCNN.1991.155315. ISBN0-7803-0164-1.
^ Хоскинс Дж., Химмельблау, Д. М. (1992). «Управление процессами с помощью искусственных нейронных сетей и обучения с подкреплением». Компьютеры и химическая инженерия . 16 (4): 241–251. doi :10.1016/0098-1354(92)80045-B.
^ Берцекас Д., Цициклис Дж. (1996). Нейродинамическое программирование. Athena Scientific. стр. 512. ISBN978-1-886529-10-6. Архивировано из оригинала 29 июня 2017 . Получено 17 июня 2017 .
^ Secomandi N (2000). «Сравнение алгоритмов нейродинамического программирования для задачи маршрутизации транспортных средств со стохастическими требованиями». Computers & Operations Research . 27 (11–12): 1201–1225. CiteSeerX 10.1.1.392.4034 . doi :10.1016/S0305-0548(99)00146-X.
^ de Rigo, D., Rizzoli, AE, Soncini-Sessa, R., Weber, E., Zenesi, P. (2001). "Нейродинамическое программирование для эффективного управления сетями резервуаров". Труды MODSIM 2001, Международный конгресс по моделированию и имитации . MODSIM 2001, Международный конгресс по моделированию и имитации. Канберра, Австралия: Общество моделирования и имитации Австралии и Новой Зеландии. doi :10.5281/zenodo.7481. ISBN0-86740-525-2. Архивировано из оригинала 7 августа 2013 . Получено 29 июля 2013 .
^ Damas, M., Salmeron, M., Diaz, A., Ortega, J., Prieto, A., Olivares, G. (2000). "Генетические алгоритмы и нейродинамическое программирование: применение к сетям водоснабжения". Труды Конгресса по эволюционным вычислениям 2000 года . Конгресс по эволюционным вычислениям 2000 года. Том 1. Ла-Хойя, Калифорния, США: IEEE. стр. 7–14. doi :10.1109/CEC.2000.870269. ISBN0-7803-6375-2.
^ Дэн Г., Феррис, М. К. (2008). «Нейродинамическое программирование для планирования фракционированной радиотерапии». Оптимизация в медицине . Springer Optimization and Its Applications. Том 12. С. 47–70. CiteSeerX 10.1.1.137.8288 . doi :10.1007/978-0-387-73299-2_3. ISBN978-0-387-73298-5.
^ Бозиновски, С. (1982). «Самообучающаяся система с использованием вторичного подкрепления». В R. Trappl (ред.) Cybernetics and Systems Research: Proceedings of the Sixth European Meeting on Cybernetics and Systems Research. North Holland. стр. 397–402. ISBN 978-0-444-86488-8 .
^ Бозиновски, С. (2014) «Моделирование механизмов взаимодействия познания и эмоций в искусственных нейронных сетях с 1981 г. Архивировано 23 марта 2019 г. в Wayback Machine ». Procedia Computer Science, стр. 255–263
^ Бозиновски С., Бозиновска Л. (2001). «Самообучающиеся агенты: коннекционистская теория эмоций, основанная на перекрестных оценочных суждениях». Кибернетика и системы . 32 (6): 637–667. doi :10.1080/01969720118145. S2CID 8944741.
^ Салиманс Т., Хо Дж., Чен Х., Сидор С., Суцкевер И. (7 сентября 2017 г.). «Стратегии эволюции как масштабируемая альтернатива обучению с подкреплением». arXiv : 1703.03864 [stat.ML].
^ Such FP, Madhavan V, Conti E, Lehman J, Stanley KO, Clune J (20 апреля 2018 г.). «Глубокая нейроэволюция: генетические алгоритмы — конкурентоспособная альтернатива для обучения глубоких нейронных сетей для обучения с подкреплением». arXiv : 1712.06567 [cs.NE].
^ «Искусственный интеллект может «эволюционировать» для решения проблем». Наука | AAAS . 10 января 2018 г. Архивировано из оригинала 9 декабря 2021 г. Получено 7 февраля 2018 г.
^ Turchetti C (2004), Стохастические модели нейронных сетей , Границы искусственного интеллекта и приложений: интеллектуальные инженерные системы, основанные на знаниях, т. 102, IOS Press, ISBN978-1-58603-388-0
^ Jospin LV, Laga H, Boussaid F, Buntine W, Bennamoun M (2022). «Практическое байесовские нейронные сети — учебное пособие для пользователей глубокого обучения». Журнал IEEE Computational Intelligence . Том 17, № 2. С. 29–48. arXiv : 2007.06823 . doi : 10.1109/mci.2022.3155327. ISSN 1556-603X. S2CID 220514248.
^ de Rigo, D., Castelletti, A., Rizzoli, AE, Soncini-Sessa, R., Weber, E. (январь 2005 г.). «Методика выборочного улучшения для закрепления нейродинамического программирования в управлении сетями водных ресурсов». В Pavel Zítek (ред.). Труды 16-го Всемирного конгресса IFAC – IFAC-PapersOnLine . 16-й Всемирный конгресс IFAC. Том 16. Прага, Чешская Республика: IFAC. стр. 7–12. doi : 10.3182/20050703-6-CZ-1902.02172. hdl : 11311/255236 . ISBN978-3-902661-75-3. Архивировано из оригинала 26 апреля 2012 . Получено 30 декабря 2011 .
^ Ferreira C (2006). «Проектирование нейронных сетей с использованием программирования экспрессии генов». В A. Abraham, B. de Baets, M. Köppen, B. Nickolay (ред.). Applied Soft Computing Technologies: The Challenge of Complexity (PDF) . Springer-Verlag. стр. 517–536. Архивировано (PDF) из оригинала 19 декабря 2013 г. . Получено 8 октября 2012 г. .
^ Da, Y., Xiurun, G. (июль 2005 г.). «Улучшенная ANN на основе PSO с методом имитации отжига». В T. Villmann (ред.). Новые аспекты в нейрокомпьютинге: 11-й европейский симпозиум по искусственным нейронным сетям . Том 63. Elsevier. стр. 527–533. doi :10.1016/j.neucom.2004.07.002. Архивировано из оригинала 25 апреля 2012 г. Получено 30 декабря 2011 г.
^ Wu, J., Chen, E. (май 2009 г.). "Новый непараметрический регрессионный ансамбль для прогнозирования осадков с использованием метода оптимизации роя частиц в сочетании с искусственной нейронной сетью". В Wang, H., Shen, Y., Huang, T., Zeng, Z. (ред.). 6-й международный симпозиум по нейронным сетям, ISNN 2009. Конспект лекций по информатике. Том 5553. Springer. стр. 49–58. doi :10.1007/978-3-642-01513-7_6. ISBN978-3-642-01215-0. Архивировано из оригинала 31 декабря 2014 . Получено 1 января 2012 .
^ ab Ting Qin, Zonghai Chen, Haitao Zhang, Sifu Li, Wei Xiang, Ming Li (2004). "A learning algorithm of CMAC based on RLS" (PDF) . Neural Processing Letters . 19 (1): 49–61. doi :10.1023/B:NEPL.0000016847.18175.60. S2CID 6233899. Архивировано (PDF) из оригинала 14 апреля 2021 г. . Получено 30 января 2019 г. .
^ Ting Qin, Haitao Zhang, Zonghai Chen, Wei Xiang (2005). «Continuous CMAC-QRLS and its systolic array» (PDF) . Neural Processing Letters . 22 (1): 1–16. doi :10.1007/s11063-004-2694-0. S2CID 16095286. Архивировано (PDF) из оригинала 18 ноября 2018 г. . Получено 30 января 2019 г. .
^ LeCun Y, Boser B, Denker JS, Henderson D, Howard RE, Hubbard W и др. (1989). «Обратное распространение ошибки применительно к распознаванию рукописных почтовых индексов». Neural Computation . 1 (4): 541–551. doi :10.1162/neco.1989.1.4.541. S2CID 41312633.
^ Янн ЛеКун (2016). Слайды о глубоком обучении онлайн Архивировано 23 апреля 2016 года на Wayback Machine
^ Хохрайтер С. , Шмидхубер Дж. (1 ноября 1997 г.). «Долгая кратковременная память». Neural Computation . 9 (8): 1735–1780. doi :10.1162/neco.1997.9.8.1735. ISSN 0899-7667. PMID 9377276. S2CID 1915014.
^ Sak H, Senior A, Beaufays F (2014). "Рекуррентные архитектуры нейронных сетей с долговременной краткосрочной памятью для крупномасштабного акустического моделирования" (PDF) . Архивировано из оригинала (PDF) 24 апреля 2018 г.
^ Ли X, У X (15 октября 2014 г.). «Построение глубоких рекуррентных нейронных сетей на основе долговременной краткосрочной памяти для распознавания речи с большим словарным запасом». arXiv : 1410.4281 [cs.CL].
^ Fan Y, Qian Y, Xie F, Soong FK (2014). «Синтез TTS с двунаправленными рекуррентными нейронными сетями на основе LSTM». Труды ежегодной конференции Международной ассоциации речевой коммуникации, Interspeech : 1964–1968 . Получено 13 июня 2017 г.
^ Zen H, Sak H (2015). «Однонаправленная рекуррентная нейронная сеть с долговременной краткосрочной памятью и рекуррентным выходным слоем для синтеза речи с малой задержкой» (PDF) . Google.com . ICASSP. стр. 4470–4474. Архивировано (PDF) из оригинала 9 мая 2021 г. . Получено 27 июня 2017 г. .
^ Fan B, Wang L, Soong FK, Xie L (2015). "Фотореалистичная говорящая голова с глубокой двунаправленной LSTM" (PDF) . Труды ICASSP . Архивировано (PDF) из оригинала 1 ноября 2017 г. . Получено 27 июня 2017 г. .
^ Сильвер Д. , Хуберт Т., Шритвизер Дж., Антоноглу И., Лай М., Гез А. и др. (5 декабря 2017 г.). «Освоение шахмат и сёги путем самостоятельной игры с помощью общего алгоритма обучения с подкреплением». arXiv : 1712.01815 [cs.AI].
^ Probst P, Boulesteix AL, Bischl B (26 февраля 2018 г.). «Настраиваемость: важность гиперпараметров алгоритмов машинного обучения». J. Mach. Learn. Res . 20 : 53:1–53:32. S2CID 88515435.
^ Zoph B, Le QV (4 ноября 2016 г.). «Поиск нейронной архитектуры с подкреплением». arXiv : 1611.01578 [cs.LG].
^ Хайфэн Цзинь, Цинцюань Сун, Ся Ху (2019). «Auto-keras: эффективная система поиска нейронной архитектуры». Труды 25-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных . ACM. arXiv : 1806.10282 . Архивировано из оригинала 21 августа 2019 г. Получено 21 августа 2019 г. – через autokeras.com.
^ Клаесен М., Де Мур Б. (2015). «Поиск гиперпараметров в машинном обучении». arXiv : 1502.02127 [cs.LG].Библиотечный код : 2015arXiv150202127C
^ Esch R (1990). «Функциональная аппроксимация». Справочник по прикладной математике (изд. Springer, США). Бостон, Массачусетс: Springer, США. стр. 928–987. doi :10.1007/978-1-4684-1423-3_17. ISBN978-1-4684-1423-3.
^ Sarstedt M, Moo E (2019). «Регрессионный анализ». Краткое руководство по исследованию рынка . Springer Texts in Business and Economics. Springer Berlin Heidelberg. стр. 209–256. doi :10.1007/978-3-662-56707-4_7. ISBN978-3-662-56706-7. S2CID 240396965. Архивировано из оригинала 20 марта 2023 г. . Получено 20 марта 2023 г. .
^ Tian J, Tan Y, Sun C, Zeng J, Jin Y (декабрь 2016 г.). «Самоадаптивная аппроксимация приспособленности на основе сходства для эволюционной оптимизации». Серия симпозиумов IEEE 2016 года по вычислительному интеллекту (SSCI) . стр. 1–8. doi :10.1109/SSCI.2016.7850209. ISBN978-1-5090-4240-1. S2CID 14948018. Архивировано из оригинала 19 мая 2024 г. . Получено 22 марта 2023 г. .
^ Alaloul WS, Qureshi AH (2019). «Обработка данных с использованием искусственных нейронных сетей». Динамическое усвоение данных — преодоление неопределенностей . doi : 10.5772/intechopen.91935. ISBN978-1-83968-083-0. S2CID 219735060. Архивировано из оригинала 20 марта 2023 г. . Получено 20 марта 2023 г. .
^ Pal M, Roy R, Basu J, Bepari MS (2013). "Слепое разделение источников: обзор и анализ". Международная конференция Oriental COCOSDA 2013 года, проведенная совместно с Конференцией по исследованиям и оценке азиатских разговорных языков (O-COCOSDA/CASLRE) 2013 года . IEEE. стр. 1–5. doi :10.1109/ICSDA.2013.6709849. ISBN978-1-4799-2378-6. S2CID 37566823. Архивировано из оригинала 20 марта 2023 г. . Получено 20 марта 2023 г. .
^ Zissis D (октябрь 2015 г.). «Архитектура на основе облака, способная воспринимать и предсказывать поведение нескольких судов». Applied Soft Computing . 35 : 652–661. doi :10.1016/j.asoc.2015.07.002. Архивировано из оригинала 26 июля 2020 г. Получено 18 июля 2019 г.
^ Сенгупта Н., Сахидулла, Мд., Саха, Гаутам (август 2016 г.). «Классификация звуков легких с использованием статистических признаков на основе кепстрального сигнала». Компьютеры в биологии и медицине . 75 (1): 118–129. doi :10.1016/j.compbiomed.2016.05.013. PMID 27286184.
^ Чой, Кристофер Б. и др. «3d-r2n2: унифицированный подход к одно- и многоракурсной реконструкции 3D-объектов. Архивировано 26 июля 2020 г. на Wayback Machine ». Европейская конференция по компьютерному зрению. Springer, Cham, 2016.
^ Турек, Фред Д. (март 2007 г.). «Введение в машинное зрение на основе нейронных сетей». Проектирование систем машинного зрения . 12 (3). Архивировано из оригинала 16 мая 2013 г. Получено 5 марта 2013 г.
^ Maitra DS, Bhattacharya U, Parui SK (август 2015 г.). «Общий подход к распознаванию рукописных символов нескольких шрифтов на основе CNN». 2015 13-я Международная конференция по анализу и распознаванию документов (ICDAR) . стр. 1021–1025. doi :10.1109/ICDAR.2015.7333916. ISBN978-1-4799-1805-8. S2CID 25739012. Архивировано из оригинала 16 октября 2023 г. . Получено 18 марта 2021 г. .
^ Gessler J (август 2021 г.). «Датчик для анализа пищевых продуктов с применением импедансной спектроскопии и искусственных нейронных сетей». RiuNet UPV (1): 8–12. Архивировано из оригинала 21 октября 2021 г. Получено 21 октября 2021 г.
^ French J (2016). «CAPM путешественника во времени». Журнал инвестиционных аналитиков . 46 (2): 81–96. doi :10.1080/10293523.2016.1255469. S2CID 157962452.
^ Роман М. Балабин, Екатерина И. Ломакина (2009). "Нейросетевой подход к данным квантовой химии: точное предсказание энергий теории функционала плотности". J. Chem. Phys. 131 (7): 074104. Bibcode :2009JChPh.131g4104B. doi :10.1063/1.3206326. PMID 19708729.
^ Silver D, et al. (2016). «Mastering the game of Go with deep neural networks and tree search» (PDF) . Nature . 529 (7587): 484–489. Bibcode :2016Natur.529..484S. doi :10.1038/nature16961. PMID 26819042. S2CID 515925. Архивировано (PDF) из оригинала 23 ноября 2018 г. . Получено 31 января 2019 г. .
^ Pasick A (27 марта 2023 г.). «Глоссарий искусственного интеллекта: объяснение нейронных сетей и других терминов». The New York Times . ISSN 0362-4331. Архивировано из оригинала 1 сентября 2023 г. Получено 22 апреля 2023 г.
^ Шехнер С. (15 июня 2017 г.). «Facebook Boosts AI to Block Terrorist Propaganda». The Wall Street Journal . ISSN 0099-9660. Архивировано из оригинала 19 мая 2024 г. Получено 16 июня 2017 г.
^ Ciaramella A , Ciaramella M (2024). Введение в искусственный интеллект: от анализа данных до генеративного ИИ . Издания Intellisemantic. ISBN978-8-8947-8760-3.
^ Ганесан Н (2010). «Применение нейронных сетей в диагностике онкологических заболеваний с использованием демографических данных». Международный журнал компьютерных приложений . 1 (26): 81–97. Bibcode : 2010IJCA....1z..81G. doi : 10.5120/476-783 .
^ Bottaci L (1997). «Искусственные нейронные сети, применяемые для прогнозирования результатов лечения пациентов с колоректальным раком в отдельных учреждениях» (PDF) . Lancet . 350 (9076). The Lancet: 469–72. doi :10.1016/S0140-6736(96)11196-X. PMID 9274582. S2CID 18182063. Архивировано из оригинала (PDF) 23 ноября 2018 г. . Получено 2 мая 2012 г. .
^ Ализаде Э., Лайонс С.М., Касл Дж.М., Прасад А. (2016). «Измерение систематических изменений в форме инвазивных раковых клеток с использованием моментов Цернике». Интегративная биология . 8 (11): 1183–1193. doi :10.1039/C6IB00100A. PMID 27735002. Архивировано из оригинала 19 мая 2024 г. Получено 28 марта 2017 г.
^ Lyons S (2016). «Изменения в форме клеток коррелируют с метастатическим потенциалом у мышей». Biology Open . 5 (3): 289–299. doi :10.1242/bio.013409. PMC 4810736. PMID 26873952.
^ Nabian MA, Meidani H (28 августа 2017 г.). «Глубокое обучение для ускоренного анализа надежности инфраструктурных сетей». Computer-Aided Civil and Infrastructure Engineering . 33 (6): 443–458. arXiv : 1708.08551 . Bibcode : 2017arXiv170808551N. doi : 10.1111/mice.12359. S2CID 36661983.
^ Nabian MA, Meidani H (2018). «Ускорение стохастической оценки связности транспортной сети после землетрясения с помощью суррогатов на основе машинного обучения». 97-е ежегодное заседание Совета по транспортным исследованиям . Архивировано из оригинала 9 марта 2018 г. Получено 14 марта 2018 г.
^ Диас Э., Бротонс В., Томас Р. (сентябрь 2018 г.). «Использование искусственных нейронных сетей для прогнозирования трехмерной упругой осадки фундаментов на грунтах с наклонным залеганием скальных пород». Soils and Foundations . 58 (6): 1414–1422. Bibcode :2018SoFou..58.1414D. doi : 10.1016/j.sandf.2018.08.001 . hdl : 10045/81208 . ISSN 0038-0806.
^ Tayebiyan A, Mohammad TA, Ghazali AH, Mashohor S. "Искусственная нейронная сеть для моделирования осадков-стока". Pertanika Journal of Science & Technology . 24 (2): 319–330. Архивировано из оригинала 17 мая 2023 г. Получено 17 мая 2023 г.
^ Govindaraju RS (1 апреля 2000 г.). «Искусственные нейронные сети в гидрологии. I: Предварительные концепции». Журнал гидрологической инженерии . 5 (2): 115–123. doi :10.1061/(ASCE)1084-0699(2000)5:2(115).
^ Govindaraju RS (1 апреля 2000 г.). «Искусственные нейронные сети в гидрологии. II: Гидрологические приложения». Журнал гидрологической инженерии . 5 (2): 124–137. doi :10.1061/(ASCE)1084-0699(2000)5:2(124).
^ Перес DJ, Иуппа C, Кавалларо L, Канчеллиере A, Фоти E (1 октября 2015 г.). «Значительное расширение записи высоты волны с помощью нейронных сетей и повторного анализа данных о ветре». Ocean Modelling . 94 : 128–140. Bibcode : 2015OcMod..94..128P. doi : 10.1016/j.ocemod.2015.08.002.
^ Дваракиш GS, Ракшит С, Натесан У (2013). «Обзор приложений нейронных сетей в прибрежной инженерии». Искусственные интеллектуальные системы и машинное обучение . 5 (7): 324–331. Архивировано из оригинала 15 августа 2017 г. Получено 5 июля 2017 г.
^ Ermini L, Catani F, Casagli N (1 марта 2005 г.). «Искусственные нейронные сети, применяемые для оценки восприимчивости к оползням». Геоморфология . Геоморфологическая опасность и воздействие человека в горных условиях. 66 (1): 327–343. Bibcode : 2005Geomo..66..327E. doi : 10.1016/j.geomorph.2004.09.025.
^ Nix R, Zhang J (май 2017 г.). «Классификация приложений и вредоносных программ Android с использованием глубоких нейронных сетей». Международная объединенная конференция по нейронным сетям (IJCNN) 2017 г. . стр. 1871–1878. doi :10.1109/IJCNN.2017.7966078. ISBN978-1-5090-6182-2. S2CID 8838479.
^ "Обнаружение вредоносных URL-адресов". Группа систем и сетей в Калифорнийском университете в Сан-Диего . Архивировано из оригинала 14 июля 2019 г. Получено 15 февраля 2019 г.
^ Хомаюн С., Ахмадзаде М., Хашеми С., Дехгантанха А., Хаями Р. (2018), Дехгантанха А., Конти М., Даргахи Т. (ред.), «BoTShark: подход глубокого обучения для обнаружения трафика ботнетов», Cyber Threat Intelligence , Advances in Information Security, т. 70, Springer International Publishing, стр. 137–153, doi : 10.1007/978-3-319-73951-9_7, ISBN978-3-319-73951-9
^ Ghosh, Reilly (январь 1994). "Обнаружение мошенничества с кредитными картами с помощью нейронной сети". Труды Двадцать седьмой Гавайской международной конференции по системным наукам HICSS-94 . Том 3. С. 621–630. doi :10.1109/HICSS.1994.323314. ISBN978-0-8186-5090-1. S2CID 13260377.
^ Ananthaswamy A (19 апреля 2021 г.). «Новейшие нейронные сети решают самые сложные уравнения мира быстрее, чем когда-либо». Журнал Quanta . Архивировано из оригинала 19 мая 2024 г. Получено 12 мая 2021 г.
^ «ИИ разгадал ключевую математическую головоломку для понимания нашего мира». MIT Technology Review . Архивировано из оригинала 19 мая 2024 года . Получено 19 ноября 2020 года .
^ "Caltech Open-Sources AI for Solving Partial Differential Equations". InfoQ . Архивировано из оригинала 25 января 2021 г. . Получено 20 января 2021 г. .
^ Nagy A (28 июня 2019 г.). «Вариационный квантовый метод Монте-Карло с нейросетевым анзацем для открытых квантовых систем». Physical Review Letters . 122 (25): 250501. arXiv : 1902.09483 . Bibcode : 2019PhRvL.122y0501N. doi : 10.1103/PhysRevLett.122.250501. PMID 31347886. S2CID 119074378.
^ Yoshioka N, Hamazaki R (28 июня 2019 г.). «Построение нейронных стационарных состояний для открытых квантовых многочастичных систем». Physical Review B. 99 ( 21): 214306. arXiv : 1902.07006 . Bibcode : 2019PhRvB..99u4306Y. doi : 10.1103/PhysRevB.99.214306. S2CID 119470636.
^ Hartmann MJ, Carleo G (28 июня 2019 г.). «Нейронно-сетевой подход к диссипативной квантовой динамике многих тел». Physical Review Letters . 122 (25): 250502. arXiv : 1902.05131 . Bibcode : 2019PhRvL.122y0502H. doi : 10.1103/PhysRevLett.122.250502. PMID 31347862. S2CID 119357494.
^ Vicentini F, Biella A, Regnault N, Ciuti C (28 июня 2019 г.). "Вариационный нейронный сетевой анзац для стационарных состояний в открытых квантовых системах". Physical Review Letters . 122 (25): 250503. arXiv : 1902.10104 . Bibcode :2019PhRvL.122y0503V. doi :10.1103/PhysRevLett.122.250503. PMID 31347877. S2CID 119504484.
^ Forrest MD (апрель 2015 г.). «Моделирование действия алкоголя на детальную модель нейрона Пуркинье и более простую суррогатную модель, которая работает >400 раз быстрее». BMC Neuroscience . 16 (27): 27. doi : 10.1186/s12868-015-0162-6 . PMC 4417229 . PMID 25928094.
^ Wieczorek S, Filipiak D, Filipowska A (2018). "Семантическое профилирование интересов пользователей на основе изображений с помощью нейронных сетей". Исследования семантической паутины . 36 (Новые темы в семантических технологиях). doi :10.3233/978-1-61499-894-5-179. Архивировано из оригинала 19 мая 2024 г. Получено 20 января 2024 г.
^ Merchant A, Batzner S, Schoenholz SS, Aykol M, Cheon G, Cubuk ED (декабрь 2023 г.). «Масштабирование глубокого обучения для открытия материалов». Nature . 624 (7990): 80–85. Bibcode :2023Natur.624...80M. doi :10.1038/s41586-023-06735-9. ISSN 1476-4687. PMC 10700131 . PMID 38030720.
^ Siegelmann H, Sontag E (1991). "Turing computability with neural nets" (PDF) . Appl. Math. Lett . 4 (6): 77–80. doi :10.1016/0893-9659(91)90080-F. Архивировано (PDF) из оригинала 19 мая 2024 г. . Получено 10 января 2017 г. .
^ Bains S (3 ноября 1998 г.). «Аналоговый компьютер превосходит модель Тьюринга». EE Times . Архивировано из оригинала 11 мая 2023 г. Получено 11 мая 2023 г.
^ Balcázar J (июль 1997 г.). «Вычислительная мощность нейронных сетей: характеристика сложности Колмогорова». Труды IEEE по теории информации . 43 (4): 1175–1183. CiteSeerX 10.1.1.411.7782 . doi :10.1109/18.605580.
^ ab MacKay DJ (2003). Теория информации, вывод и алгоритмы обучения (PDF) . Cambridge University Press . ISBN978-0-521-64298-9. Архивировано (PDF) из оригинала 19 октября 2016 г. . Получено 11 июня 2016 г. .
^ Cover T (1965). «Геометрические и статистические свойства систем линейных неравенств с приложениями в распознавании образов» (PDF) . IEEE Transactions on Electronic Computers . EC-14 (3). IEEE : 326–334. doi :10.1109/PGEC.1965.264137. Архивировано (PDF) из оригинала 5 марта 2016 года . Получено 10 марта 2020 года .
^ Джеральд Ф (2019). «Воспроизводимость и экспериментальное проектирование для машинного обучения на аудио- и мультимедийных данных». Труды 27-й Международной конференции ACM по мультимедиа . ACM . С. 2709–2710. doi :10.1145/3343031.3350545. ISBN978-1-4503-6889-6. S2CID 204837170.
^ "Хватит возиться, начинайте измерять! Предсказуемый экспериментальный дизайн экспериментов с нейронными сетями". The Tensorflow Meter . Архивировано из оригинала 18 апреля 2022 г. Получено 10 марта 2020 г.
^ Lee J, Xiao L, Schoenholz SS, Bahri Y, Novak R, Sohl-Dickstein J и др. (2020). «Широкие нейронные сети любой глубины развиваются как линейные модели при градиентном спуске». Журнал статистической механики: теория и эксперимент . 2020 (12): 124002. arXiv : 1902.06720 . Bibcode : 2020JSMTE2020l4002L. doi : 10.1088/1742-5468/abc62b. S2CID 62841516.
^ Артур Жако, Франк Габриэль, Клемент Хонглер (2018). Neural Tangent Kernel: Convergence and Generalization in Neural Networks (PDF) . 32-я конференция по нейронным системам обработки информации (NeurIPS 2018), Монреаль, Канада. Архивировано (PDF) из оригинала 22 июня 2022 г. . Получено 4 июня 2022 г. .
^ Xu ZJ, Zhang Y, Xiao Y (2019). «Поведение обучения глубокой нейронной сети в частотной области». В Gedeon T, Wong K, Lee M (ред.). Neural Information Processing . Lecture Notes in Computer Science. Vol. 11953. Springer, Cham. стр. 264–274. arXiv : 1807.01251 . doi :10.1007/978-3-030-36708-4_22. ISBN978-3-030-36707-7. S2CID 49562099.
^ Насим Рахаман, Аристид Баратин, Деванш Арпит, Феликс Дракслер, Мин Лин, Фред Хампрехт и др. (2019). «О спектральном смещении нейронных сетей» (PDF) . Труды 36-й Международной конференции по машинному обучению . 97 : 5301–5310. arXiv : 1806.08734 . Архивировано (PDF) из оригинала 22 октября 2022 г. . Получено 4 июня 2022 г. .
^ Чжи-Цинь Джон Сюй, Яоюй Чжан, Тао Ло, Яньян Сяо, Чжэн Ма (2020). «Частотный принцип: анализ Фурье проливает свет на глубокие нейронные сети». Communications in Computational Physics . 28 (5): 1746–1767. arXiv : 1901.06523 . Bibcode : 2020CCoPh..28.1746X. doi : 10.4208/cicp.OA-2020-0085. S2CID 58981616.
^ Тао Ло, Чжэн Ма, Чжи-Цинь Джон Сюй, Яоюй Чжан (2019). «Теория частотного принципа для глубоких нейронных сетей общего назначения». arXiv : 1906.09235 [cs.LG].
^ Xu ZJ, Zhou H (18 мая 2021 г.). «Принцип глубокой частоты к пониманию того, почему более глубокое обучение быстрее». Труды конференции AAAI по искусственному интеллекту . 35 (12): 10541–10550. arXiv : 2007.14313 . doi : 10.1609/aaai.v35i12.17261. ISSN 2374-3468. S2CID 220831156. Архивировано из оригинала 5 октября 2021 г. . Получено 5 октября 2021 г. .
^ Parisi GI, Kemker R, Part JL, Kanan C, Wermter S (1 мая 2019 г.). «Непрерывное обучение на протяжении всей жизни с помощью нейронных сетей: обзор». Neural Networks . 113 : 54–71. arXiv : 1802.07569 . doi : 10.1016/j.neunet.2019.01.012 . ISSN 0893-6080. PMID 30780045.
^ Дин Померло, «Обучение искусственных нейронных сетей на основе знаний для автономного вождения робота»
^ Dewdney AK (1 апреля 1997 г.). Да, у нас нет нейтронов: открывающий глаза тур по перипетиям плохой науки. Wiley. стр. 82. ISBN978-0-471-10806-1.
^ NASA – Исследовательский центр Драйдена – Новостная комната: Пресс-релизы: ПРОЕКТ НЕЙРОННОЙ СЕТИ НАСА ПРОШЕЛ ВАЖНУЮ ВЕХУ Архивировано 2 апреля 2010 г. на Wayback Machine . Nasa.gov. Получено 20 ноября 2013 г.
^ "Защита нейронных сетей Роджером Бриджменом". Архивировано из оригинала 19 марта 2012 года . Получено 12 июля 2010 года .
^ «Масштабирование алгоритмов обучения в направлении {AI} – LISA – Публикации – Aigaion 2.0». iro.umontreal.ca .
^ DJ Felleman и DC Van Essen, «Распределенная иерархическая обработка в коре головного мозга приматов», Cerebral Cortex , 1, стр. 1–47, 1991.
^ J. Weng, «Естественный и искусственный интеллект: введение в вычислительный мозг-разум. Архивировано 19 мая 2024 г. в Wayback Machine », BMI Press, ISBN 978-0-9858757-2-5 , 2012.
^ ab Edwards C (25 июня 2015 г.). «Болезни роста для глубокого обучения». Сообщения ACM . 58 (7): 14–16. doi :10.1145/2771283. S2CID 11026540.
^ "Горький урок". incompleteideas.net . Получено 7 августа 2024 г. .
^ Кейд Метц (18 мая 2016 г.). «Google создала собственные чипы для питания своих ботов с искусственным интеллектом». Wired . Архивировано из оригинала 13 января 2018 г. Получено 5 марта 2017 г.
^ "Масштабирование алгоритмов обучения в сторону ИИ" (PDF) . Архивировано (PDF) из оригинала 12 августа 2022 г. . Получено 6 июля 2022 г. .
^ Tahmasebi, Hezarkhani (2012). «Гибрид нейронных сетей, нечеткой логики и генетического алгоритма для оценки оценок». Computers & Geosciences . 42 : 18–27. Bibcode :2012CG.....42...18T. doi :10.1016/j.cageo.2012.02.004. PMC 4268588 . PMID 25540468.
^ Сан и Букман, 1990
^ ab Norori N, Hu Q, Aellen FM, Faraci FD, Tzovara A (октябрь 2021 г.). «Устранение предвзятости в больших данных и ИИ для здравоохранения: призыв к открытой науке». Patterns . 2 (10): 100347. doi : 10.1016/j.patter.2021.100347 . PMC 8515002 . PMID 34693373.
^ ab Carina W (27 октября 2022 г.). «Провал по номинальной стоимости: влияние предвзятой технологии распознавания лиц на расовую дискриминацию в уголовном правосудии». Научные и социальные исследования . 4 (10): 29–40. doi : 10.26689/ssr.v4i10.4402 . ISSN 2661-4332.
^ ab Chang X (13 сентября 2023 г.). «Гендерная предвзятость при найме: анализ влияния алгоритма найма Amazon». Advances in Economics, Management and Political Sciences . 23 (1): 134–140. doi : 10.54254/2754-1169/23/20230367 . ISSN 2754-1169. Архивировано из оригинала 9 декабря 2023 г. . Получено 9 декабря 2023 г. .
^ Kortylewski A, Egger B, Schneider A, Gerig T, Morel-Forster A, Vetter T (июнь 2019 г.). «Анализ и снижение ущерба от смещения набора данных при распознавании лиц с помощью синтетических данных». IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 2019 г. (PDF) . IEEE. стр. 2261–2268. doi :10.1109/cvprw.2019.00279. ISBN978-1-7281-2506-0. S2CID 198183828. Архивировано (PDF) из оригинала 19 мая 2024 г. . Получено 30 декабря 2023 г. .
^ abcdef Хуан И (2009). «Достижения в области искусственных нейронных сетей – методологическая разработка и применение». Алгоритмы . 2 (3): 973–1007. doi : 10.3390/algor2030973 . ISSN 1999-4893.
^ abcde Kariri E, Louati H, Louati A, Masmoudi F (2023). «Изучение достижений и будущих направлений исследований искусственных нейронных сетей: подход к интеллектуальному анализу текста». Прикладные науки . 13 (5): 3186. doi : 10.3390/app13053186 . ISSN 2076-3417.
^ ab Fui-Hoon Nah F, Zheng R, Cai J, Siau K, Chen L (3 июля 2023 г.). «Генеративный ИИ и ChatGPT: приложения, проблемы и сотрудничество ИИ и человека». Журнал исследований случаев и приложений информационных технологий . 25 (3): 277–304. doi : 10.1080/15228053.2023.2233814 . ISSN 1522-8053.
^ "DALL-E 2's Failures Are the Most Interesting Thing About It – IEEE Spectrum". IEEE . Архивировано из оригинала 15 июля 2022 г. Получено 9 декабря 2023 г.
^ Briot JP (январь 2021 г.). «От искусственных нейронных сетей к глубокому обучению для создания музыки: история, концепции и тенденции». Neural Computing and Applications . 33 (1): 39–65. doi : 10.1007/s00521-020-05399-0 . ISSN 0941-0643.
^ Chow PS (6 июля 2020 г.). «Призрак в (голливудской) машине: новые применения искусственного интеллекта в киноиндустрии». NECSUS_European Journal of Media Studies . doi : 10.25969/MEDIAREP/14307. ISSN 2213-0217.
^ Yu X, He S, Gao Y, Yang J, Sha L, Zhang Y и др. (июнь 2010 г.). «Динамическая настройка сложности игрового ИИ для видеоигры Dead-End». 3-я международная конференция по информационным наукам и наукам взаимодействия . IEEE. стр. 583–587. doi :10.1109/icicis.2010.5534761. ISBN978-1-4244-7384-7. S2CID 17555595.
Библиография
Bhadeshia HKDH (1999). «Нейронные сети в материаловедении» (PDF) . ISIJ International . 39 (10): 966–979. doi :10.2355/isijinternational.39.966.
Bishop CM (1995). Нейронные сети для распознавания образов . Clarendon Press. ISBN 978-0-19-853849-3. OCLC 33101074.
Боргельт С (2003). Neuro-Fuzzy-Systeme: von den Grundlagen künstlicher Neuronaler Netze zur Kopplung mit Fuzzy-Systemen . Посмотретьег. ISBN 978-3-528-25265-6. OCLC 76538146.
Egmont-Petersen M, de Ridder D, Handels H (2002). «Обработка изображений с помощью нейронных сетей – обзор». Pattern Recognition . 35 (10): 2279–2301. CiteSeerX 10.1.1.21.5444 . doi :10.1016/S0031-3203(01)00178-9.
Fahlman S, Lebiere C (1991). "Архитектура каскадно-корреляционного обучения" (PDF) . Архивировано из оригинала (PDF) 3 мая 2013 г. . Получено 28 августа 2006 г. .
Гурни К (1997). Введение в нейронные сети . UCL Press. ISBN 978-1-85728-673-1. OCLC 37875698.
Хайкин СС (1999). Нейронные сети: всеобъемлющая основа . Prentice Hall. ISBN 978-0-13-273350-2. OCLC 38908586.
Герц Дж., Палмер Р.Г., Крог А.С. (1991). Введение в теорию нейронных вычислений . Эддисон-Уэсли. ISBN 978-0-201-51560-2. OCLC 21522159.
Теория информации, вывод и алгоритмы обучения . Cambridge University Press. 25 сентября 2003 г. Bibcode :2003itil.book.....M. ISBN 978-0-521-64298-9. OCLC 52377690.
Крузе Р., Боргельт С., Клавонн Ф., Мовес С., Штайнбрехер М., Хелд П. (2013). Вычислительный интеллект: методологическое введение . Спрингер. ISBN 978-1-4471-5012-1. OCLC 837524179.
Лоуренс Дж. (1994). Введение в нейронные сети: проектирование, теория и приложения . California Scientific Software. ISBN 978-1-883157-00-5. OCLC 32179420.
Мастерс Т. (1994). Обработка сигналов и изображений с помощью нейронных сетей: справочник по C++ . J. Wiley. ISBN 978-0-471-04963-0. OCLC 29877717.
Maurer H (2021). Когнитивная наука: интегративные механизмы синхронизации в когнитивных нейроархитектурах современного коннекционизма . CRC Press. doi : 10.1201/9781351043526. ISBN 978-1-351-04352-6. S2CID 242963768.
Рипли Б.Д. (2007). Распознавание образов и нейронные сети. Cambridge University Press. ISBN 978-0-521-71770-0.
Siegelmann H, Sontag ED (1994). «Аналоговые вычисления с помощью нейронных сетей». Теоретическая информатика . 131 (2): 331–360. doi : 10.1016/0304-3975(94)90178-3 . S2CID 2456483.
Смит М. (1993). Нейронные сети для статистического моделирования . Ван Ностранд Рейнхольд. ISBN 978-0-442-01310-3. OCLC 27145760.
Вассерман ПД (1993). Передовые методы нейронных вычислений . Ван Ностранд Рейнхольд. ISBN 978-0-442-00461-3. OCLC 27429729.
Wilson H (2018). Искусственный интеллект . Grey House Publishing. ISBN 978-1-68217-867-6.
Внешние ссылки
Послушайте эту статью ( 31 минута )
Этот аудиофайл был создан на основе редакции этой статьи от 27 ноября 2011 года и не отражает последующие правки. (2011-11-27)
Краткое введение в нейронные сети (Д. Кризель) – иллюстрированная двуязычная рукопись об искусственных нейронных сетях; темы на данный момент: персептроны, обратное распространение, радиальные базисные функции, рекуррентные нейронные сети, самоорганизующиеся карты, сети Хопфилда.
Обзор нейронных сетей в материаловедении Архивировано 7 июня 2015 г. на Wayback Machine
Учебное пособие по искусственным нейронным сетям на трех языках (Мадридский политехнический университет)
Еще одно введение в ANN
Следующее поколение нейронных сетей Архивировано 24 января 2011 г. на Wayback Machine – Google Tech Talks
Производительность нейронных сетей
Нейронные сети и информация Архивировано 9 июля 2009 г. на Wayback Machine
Sanderson G (5 октября 2017 г.). «Но что такое нейронная сеть?». 3Blue1Brown . Архивировано из оригинала 7 ноября 2021 г. – через YouTube .





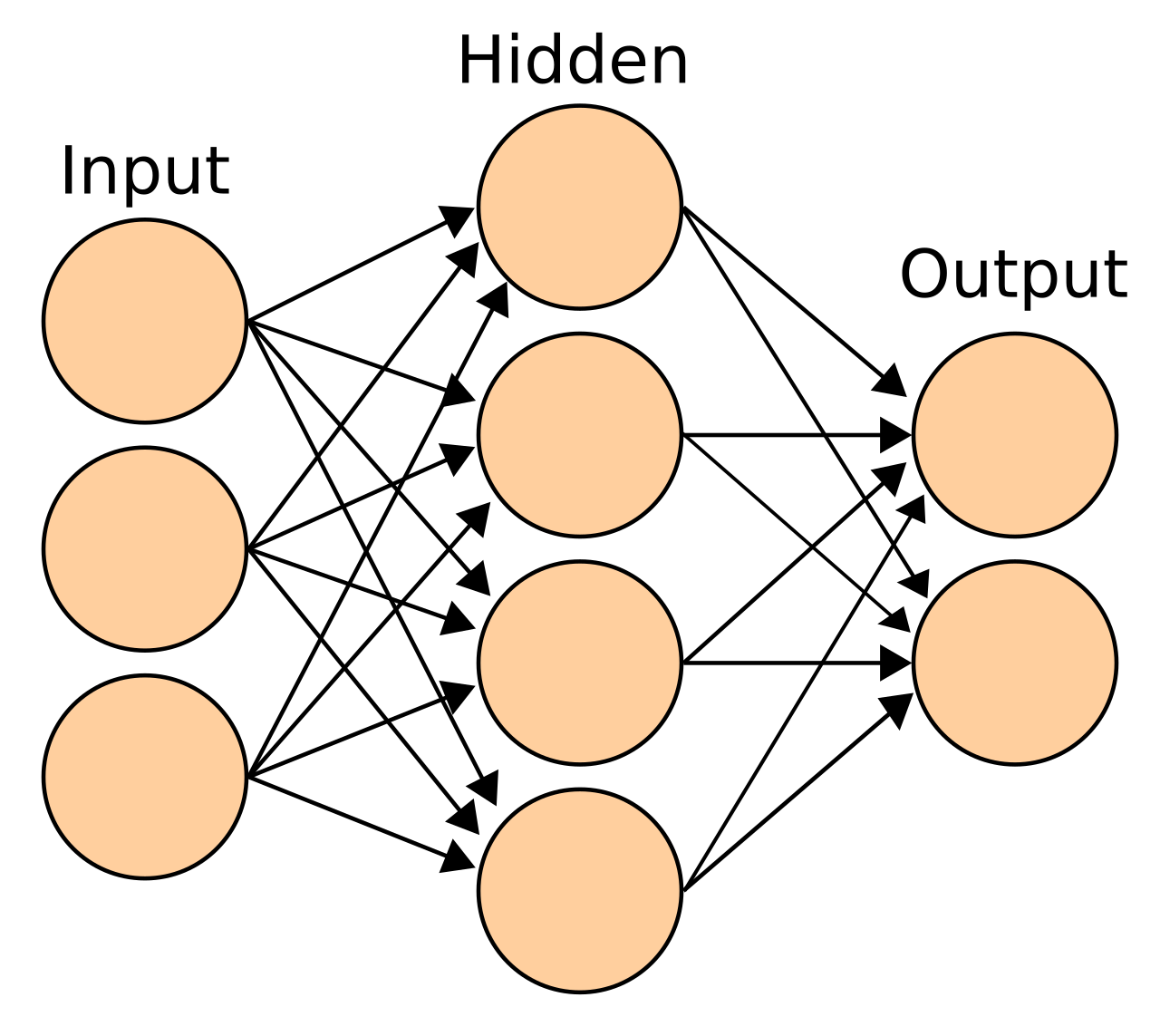
.svg/1280px-Ann_dependency_(graph).svg.png)





![{\displaystyle \textstyle C=E[(xf(x))^{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2929ecb1606fdfeaddc55477d9671e11c034e21c)










