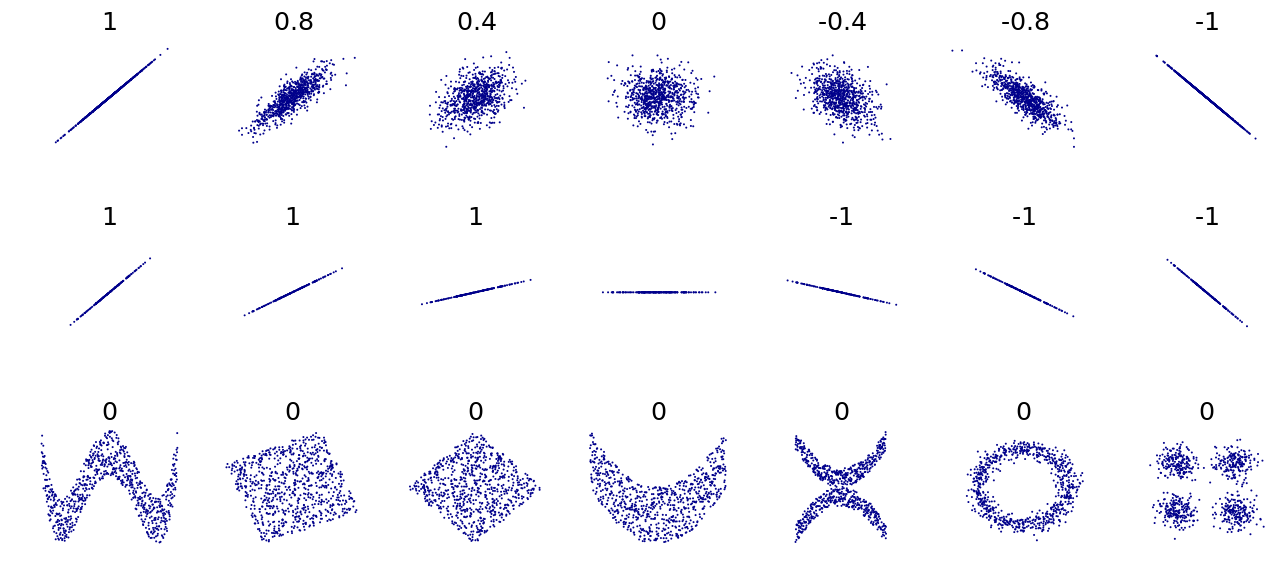
Примеры диаграмм рассеяния с разными значениями коэффициента корреляции ( ρ )Несколько наборов точек ( x , y ) с коэффициентом корреляции x и y для каждого набора. Корреляция отражает силу и направление линейной зависимости (верхний ряд), но не наклон этой зависимости (средний) и многие аспекты нелинейных связей (нижний). Примечание: фигура в центре имеет наклон 0, но в этом случае коэффициент корреляции не определен, поскольку дисперсия Y равна нулю.
В статистике коэффициент корреляции Пирсона ( PCC ) [a] — это коэффициент корреляции , который измеряет линейную корреляцию между двумя наборами данных. Это отношение между ковариацией двух переменных и произведением их стандартных отклонений ; таким образом, это, по сути, нормализованное измерение ковариации, так что результат всегда имеет значение от -1 до 1. Как и сама ковариация, эта мера может отражать только линейную корреляцию переменных и игнорировать многие другие типы отношений или корреляции. В качестве простого примера можно было бы ожидать, что возраст и рост выборки подростков из средней школы будут иметь коэффициент корреляции Пирсона значительно больше 0, но меньше 1 (поскольку 1 будет представлять собой нереально идеальную корреляцию).
Именование и история
Он был разработан Карлом Пирсоном на основе схожей идеи, предложенной Фрэнсисом Гальтоном в 1880-х годах, и для которой математическая формула была выведена и опубликована Огюстом Браве в 1844 году. [b] [6] [7] [8] [9 ] Таким образом, наименование коэффициента является примером закона Стиглера .
Определение
Коэффициент корреляции Пирсона представляет собой ковариацию двух переменных, деленную на произведение их стандартных отклонений. Форма определения включает в себя «момент продукта», то есть среднее значение (первый момент начала координат) произведения случайных величин с поправкой на среднее значение; отсюда и модификатор product-moment в названии.
Для населения
Коэффициент корреляции Пирсона, применительно к популяции , обычно обозначается греческой буквой ρ (rho) и может называться коэффициентом корреляции популяции или коэффициентом корреляции Пирсона популяции . Учитывая пару случайных величин (например, рост и вес), формула для ρ [10] имеет вид [11]
Формулу для можно выразить через среднее и математическое ожидание . Поскольку [10]
формулу для также можно записать как
где
и определяются, как указано выше
это среднее значение
это среднее значение
это ожидание.
Формулу можно выразить через нецентрированные моменты. С
формулу для также можно записать как
Для образца
Коэффициент корреляции Пирсона, применяемый к выборке , обычно обозначается и может называться выборочным коэффициентом корреляции или выборочным коэффициентом корреляции Пирсона . Мы можем получить формулу для , подставив оценки ковариаций и дисперсий на основе выборки в приведенную выше формулу. Учитывая парные данные, состоящие из пар, определяются как
где
размер выборки
отдельные точки выборки, индексированные i
(выборочное среднее); и аналогично для .
Перестановка дает нам следующую формулу :
где определены, как указано выше.
Эта формула предлагает удобный однопроходный алгоритм расчета выборочных корреляций, хотя в зависимости от задействованных чисел он иногда может быть численно нестабильным .
Повторная перестановка дает нам формулу [10] для :
где определены, как указано выше.
Эквивалентное выражение дает формулу для среднего значения произведений стандартных оценок следующим образом:
где
определены, как указано выше, и определены ниже
— стандартный балл (и аналогично стандартному баллу ).
Альтернативные формулы также доступны. Например, можно использовать следующую формулу для :
В условиях сильного шума извлечение коэффициента корреляции между двумя наборами стохастических переменных является нетривиальной задачей, в частности, когда канонический корреляционный анализ сообщает об ухудшении значений корреляции из-за сильного шума. Обобщение подхода дано в другом месте. [12]
Значения коэффициентов корреляции Пирсона выборки и генеральной совокупности находятся в пределах от -1 до 1 или между ними. Корреляции, равные +1 или -1, соответствуют точкам данных, лежащим точно на прямой (в случае выборочной корреляции), или двумерное распределение, полностью поддерживаемое линией (в случае корреляции населения). Коэффициент корреляции Пирсона симметричен: corr( X , Y ) = corr( Y , X ).
Ключевым математическим свойством коэффициента корреляции Пирсона является то, что он инвариантен при отдельных изменениях местоположения и масштаба двух переменных. То есть мы можем преобразовать X в a + bX и преобразовать Y в c + dY , где a , b , c и d — константы с b , d > 0 , без изменения коэффициента корреляции. (Это справедливо как для генеральных, так и для выборочных коэффициентов корреляции Пирсона.) Более общие линейные преобразования действительно меняют корреляцию: см. § Декорреляция n случайных величин , чтобы узнать об этом.
Интерпретация
Коэффициент корреляции находится в диапазоне от -1 до 1. Абсолютное значение, равное ровно 1, означает, что линейное уравнение идеально описывает взаимосвязь между X и Y , причем все точки данных лежат на прямой . Знак корреляции определяется наклоном регрессии : значение +1 подразумевает, что все точки данных лежат на линии, для которой Y увеличивается по мере увеличения X , и наоборот для -1. [14] Значение 0 означает, что между переменными нет линейной зависимости. [15]
В более общем смысле, ( X i - X )( Y i - Y ) является положительным тогда и только тогда, когда X i и Y i лежат по одну сторону от своих соответствующих средних значений. Таким образом, коэффициент корреляции является положительным, если X i и Y i имеют тенденцию быть одновременно больше или одновременно меньше своих соответствующих средних значений. Коэффициент корреляции является отрицательным ( антикорреляция ), если X i и Y i имеют тенденцию лежать на противоположных сторонах своих соответствующих средних значений. При этом чем сильнее та или иная тенденция, тем больше абсолютное значение коэффициента корреляции.
Роджерс и Найсвандер [16] каталогизировали тринадцать способов интерпретации корреляции или простых ее функций:
Функция необработанных оценок и средних значений
Стандартизованная ковариация
Стандартизованный наклон линии регрессии
Среднее геометрическое двух наклонов регрессии
Квадратный корень из отношения двух дисперсий
Среднее перекрестное произведение стандартизированных переменных
Функция угла между двумя стандартизированными линиями регрессии
Функция угла между двумя переменными векторами
Изменена дисперсия разницы между стандартизированными оценками.
Оценка по правилу воздушного шара
Связано с двумерными эллипсами изоконцентрации.
Функция статистики испытаний из запланированных экспериментов
Соотношение двух средств
Геометрическая интерпретация
Линии регрессии для y = g X ( x ) [ красный ] и x = g Y ( y ) [ синий ]
Для нецентрированных данных существует связь между коэффициентом корреляции и углом φ между двумя линиями регрессии, y = g X ( x ) и x = g Y ( y ) , полученными путем регрессии y по x и x по y соответственно. (Здесь φ измеряется против часовой стрелки в пределах первого квадранта, образованного вокруг точки пересечения линий, если r > 0 , или против часовой стрелки от четвертого ко второму квадранту, если r < 0. ) Можно показать [17] , что если стандартные отклонения равны равны, то r = sec φ − tan φ , где sec и tan — тригонометрические функции .
Для центрированных данных (т. е. данных, которые были сдвинуты выборочными средними их соответствующих переменных так, чтобы среднее значение каждой переменной было равно нулю), коэффициент корреляции также можно рассматривать как косинус угла θ между двумя наблюдаемыми значениями. векторы в N -мерном пространстве (для N наблюдений каждой переменной). [18]
Для набора данных можно определить как нецентрированные (не соответствующие Пирсону), так и центрированные коэффициенты корреляции. В качестве примера предположим, что валовой национальный продукт пяти стран составляет 1, 2, 3, 5 и 8 миллиардов долларов соответственно. Предположим, что в этих же пяти странах (в том же порядке) уровень бедности составляет 11%, 12%, 13%, 15% и 18%. Тогда пусть x и y — упорядоченные 5-элементные векторы, содержащие приведенные выше данные: x = (1, 2, 3, 5, 8) и y = (0,11, 0,12, 0,13, 0,15, 0,18) .
С помощью обычной процедуры нахождения угла θ между двумя векторами (см. скалярное произведение ) нецентрированный коэффициент корреляции равен
Этот нецентрированный коэффициент корреляции идентичен косинусному подобию . Приведенные выше данные были намеренно выбраны так, чтобы они идеально коррелировали: y = 0,10 + 0,01 x . Следовательно, коэффициент корреляции Пирсона должен быть ровно единицей. Центрирование данных (смещение x на ℰ( x ) = 3,8 и y на ℰ( y ) = 0,138 ) дает x = (-2,8, -1,8, -0,8, 1,2, 4,2) и y = (-0,028, -0,018, −0,008, 0,012, 0,042) , откуда
как и ожидалось.
Интерпретация размера корреляции
Этот рисунок дает представление о том, как полезность корреляции Пирсона для прогнозирования значений зависит от ее величины. Учитывая совместно нормальные X , Y с корреляцией ρ (показано здесь как функция ρ ) , это коэффициент, на который данный интервал прогнозирования для Y может быть уменьшен с учетом соответствующего значения X . Например, если ρ = 0,5, то 95%-ный интервал прогнозирования Y | X будет примерно на 13% меньше 95%-го интервала прогнозирования Y .
Некоторые авторы предложили рекомендации по интерпретации коэффициента корреляции. [19] [20] Однако все такие критерии в некоторой степени произвольны. [20] Интерпретация коэффициента корреляции зависит от контекста и целей. Корреляция 0,8 может быть очень низкой, если проверять физический закон с использованием высококачественных инструментов, но может считаться очень высокой в социальных науках, где может быть больший вклад усложняющих факторов.
Вывод
Статистический вывод, основанный на коэффициенте корреляции Пирсона, часто фокусируется на одной из следующих двух целей:
Одна из целей состоит в том, чтобы проверить нулевую гипотезу о том, что истинный коэффициент корреляции ρ равен 0, на основе значения выборочного коэффициента корреляции r .
Другая цель — получить доверительный интервал , который при повторной выборке с заданной вероятностью будет содержать ρ .
Методы достижения одной или обеих этих целей обсуждаются ниже.
Использование теста перестановки
Тесты перестановок обеспечивают прямой подход к проверке гипотез и построению доверительных интервалов. Перестановочный тест коэффициента корреляции Пирсона включает в себя следующие два этапа:
Используя исходные парные данные ( x i , y i ), случайным образом переопределите пары, чтобы создать новый набор данных ( x i , y i ' ), где i ' являются перестановкой набора {1,..., n }. Перестановка i выбирается случайным образом с равными вероятностями, размещенными на всех n ! возможные перестановки. Это эквивалентно рисованию i' случайным образом без замены из набора {1, ..., n }. При начальной загрузке , тесно связанном подходе, i и i' равны и рисуются с заменой из {1, ..., n };
Постройте коэффициент корреляции r из рандомизированных данных.
Чтобы выполнить тест на перестановку, повторите шаги (1) и (2) большое количество раз. Значение p для теста перестановки — это доля значений r , полученных на этапе (2), которые превышают коэффициент корреляции Пирсона, рассчитанный на основе исходных данных. Здесь «больше» может означать либо то, что значение больше по величине, либо больше по знаку, в зависимости от того, требуется ли двусторонний или односторонний тест.
Использование бутстрапа
Бутстрап можно использовать для построения доверительных интервалов для коэффициента корреляции Пирсона. В «непараметрическом» бутстрапе n пар ( x i , y i ) повторно выбираются «с заменой» из наблюдаемого набора из n пар, а коэффициент корреляции r вычисляется на основе повторно дискретизированных данных. Этот процесс повторяется большое количество раз, и эмпирическое распределение повторно выбранных значений r используется для аппроксимации выборочного распределения статистики. 95% доверительный интервал для ρ можно определить как интервал, охватывающий от 2,5 до 97,5 процентиля повторно выбранных значений r .
Стандартная ошибка
Если и являются случайными величинами, стандартная ошибка , связанная с корреляцией в нулевом случае, равна
где – корреляция (предполагается r ≈0) и размер выборки. [21] [22]
Тестирование с использованием t -распределения Стьюдента
Критические значения коэффициента корреляции Пирсона, которые необходимо превысить, чтобы считаться значимо отличным от нуля на уровне 0,05.
Для пар из некоррелированного двумерного нормального распределения выборочное распределение стьюдентизированного коэффициента корреляции Пирсона следует t -распределению Стьюдента со степенями свободы n - 2. В частности, если базовые переменные имеют двумерное нормальное распределение, переменная
имеет t -распределение Стьюдента в нулевом случае (нулевая корреляция). [23] Это приблизительно справедливо в случае ненормальных наблюдаемых значений, если размеры выборки достаточно велики. [24] Для определения критических значений r необходима обратная функция:
В качестве альтернативы можно использовать асимптотические подходы на большой выборке.
В другой ранней статье [25] представлены графики и таблицы для общих значений ρ для небольших размеров выборки и обсуждаются вычислительные подходы.
В случае, когда основные переменные не являются нормальными, выборочное распределение коэффициента корреляции Пирсона следует t -распределению Стьюдента , но степени свободы уменьшаются. [26]
Использование точного распределения
Для данных, которые следуют двумерному нормальному распределению , точная функция плотности f ( r ) для выборочного коэффициента корреляции r нормального двумерного распределения равна [27] [28] [29]
В особом случае, когда (нулевая корреляция населения), точную функцию плотности f ( r ) можно записать как
где – бета-функция , которая является одним из способов записи плотности t-распределения Стьюдента для коэффициента корреляции стьюдентизированной выборки, как указано выше.
Использование точного доверительного распределения
Доверительные интервалы и тесты можно рассчитать на основе доверительного распределения . Точная доверительная плотность для ρ равна [30]
Чтобы получить доверительный интервал для ρ, мы сначала вычисляем доверительный интервал для F ( ):
Обратное преобразование Фишера возвращает интервал в шкалу корреляции.
Например, предположим, что мы наблюдаем r = 0,7 при размере выборки n = 50 и хотим получить 95% доверительный интервал для ρ . Преобразованное значение равно , поэтому доверительный интервал преобразованной шкалы равен , или (0,5814, 1,1532). Преобразование обратно в шкалу корреляции дает (0,5237, 0,8188).
Регрессионный анализ по методу наименьших квадратов
Квадрат выборочного коэффициента корреляции обычно обозначается r2 и является частным случаем коэффициента детерминации . В этом случае он оценивает долю дисперсии Y , которая объясняется X в простой линейной регрессии . Итак, если у нас есть набор наблюдаемых данных и подобранный набор данных , то в качестве отправной точки общее изменение Y i вокруг их среднего значения можно разложить следующим образом:
где – подобранные значения из регрессионного анализа. Это можно переставить, чтобы дать
Два слагаемых выше представляют собой долю дисперсии Y , которая объясняется X (справа) и необъясняется X (слева).
Затем мы применяем свойство моделей регрессии наименьших квадратов , согласно которому выборочная ковариация между и равна нулю. Таким образом, можно записать выборочный коэффициент корреляции между наблюдаемыми и подобранными значениями ответа в регрессии (расчеты ожидаются, предполагается статистика Гаусса).
Таким образом
где доля дисперсии Y , объясняемая линейной функцией X .
В приведенном выше выводе тот факт, что
можно доказать, заметив, что частные производные остаточной суммы квадратов ( RSS ) по β 0 и β 1 равны 0 в модели наименьших квадратов, где
Коэффициент корреляции Пирсона для населения определяется в терминах моментов и, следовательно, существует для любого двумерного распределения вероятностей , для которого определена ковариация генеральной совокупности и определены предельные дисперсии генеральной совокупности , которые не равны нулю. Некоторые распределения вероятностей, такие как распределение Коши , имеют неопределенную дисперсию и, следовательно, ρ не определен, если X или Y следует такому распределению. В некоторых практических приложениях, например, когда данные предположительно имеют распределение с тяжелым хвостом , это является важным фактором. Однако существование коэффициента корреляции обычно не вызывает беспокойства; например, если диапазон распределения ограничен, ρ всегда определен.
Размер образца
Если размер выборки умеренный или большой, а популяция нормальная, то в случае двумерного нормального распределения коэффициент корреляции выборки представляет собой оценку максимального правдоподобия коэффициента корреляции популяции и является асимптотически несмещенным и эффективным , что примерно означает что невозможно построить более точную оценку, чем выборочный коэффициент корреляции.
Если размер выборки велик, а совокупность не является нормальной, то коэффициент корреляции выборки остается примерно несмещенным, но может быть неэффективным.
Если размер выборки велик, то коэффициент корреляции выборки является последовательной оценкой коэффициента корреляции генеральной совокупности, пока выборочные средние, дисперсии и ковариация последовательны (что гарантируется при применении закона больших чисел ).
Если размер выборки невелик, то выборочный коэффициент корреляции r не является несмещенной оценкой ρ . [10] Вместо этого следует использовать скорректированный коэффициент корреляции: определение см. в других разделах этой статьи.
Корреляции могут быть разными для несбалансированных дихотомических данных, когда в выборке есть ошибка дисперсии. [31]
Статистический вывод для коэффициента корреляции Пирсона чувствителен к распределению данных. Точные тесты и асимптотические тесты, основанные на преобразовании Фишера, могут применяться, если данные примерно нормально распределены, но в противном случае могут вводить в заблуждение. В некоторых ситуациях бутстрап можно применять для построения доверительных интервалов, а тесты перестановок можно применять для проверки гипотез. Эти непараметрические подходы могут дать более значимые результаты в некоторых ситуациях, когда двумерная нормальность не соблюдается. Однако стандартные версии этих подходов полагаются на возможность обмена данными, что означает отсутствие упорядочения или группировки анализируемых пар данных, которые могли бы повлиять на поведение оценки корреляции.
Стратифицированный анализ — это один из способов либо компенсировать отсутствие двумерной нормальности, либо изолировать корреляцию, возникающую в результате одного фактора, при этом контролируя другой. Если W представляет членство в кластере или другой фактор, который желательно контролировать, мы можем стратифицировать данные на основе значения W , а затем вычислить коэффициент корреляции внутри каждого слоя. Затем оценки на уровне страты можно объединить для оценки общей корреляции с учетом W . [36]
Варианты
Вариации коэффициента корреляции можно рассчитывать для разных целей. Вот некоторые примеры.
Скорректированный коэффициент корреляции
Выборочный коэффициент корреляции r не является несмещенной оценкой ρ . Для данных, которые следуют двумерному нормальному распределению , математическое ожидание E[ r ] для выборочного коэффициента корреляции r нормального двумерного распределения равно [37]
поэтому r является смещенной оценкой
Уникальная несмещенная оценка минимальной дисперсии r adj имеет вид [38]
r adj также можно получить путем максимизации log( f ( r )),
r adj имеет минимальную дисперсию для больших значений n ,
r adj имеет смещение порядка 1 ⁄ ( n - 1) .
Другой предложенный [10] скорректированный коэффициент корреляции :
r adj ≈ r для больших значений n .
Взвешенный коэффициент корреляции
Предположим, что наблюдения, подлежащие корреляции, имеют разную степень важности, которую можно выразить с помощью весового вектора w . Чтобы вычислить корреляцию между векторами x и y с весовым вектором w (все длины n ), [39] [40]
Средневзвешенное значение:
Взвешенная ковариация
Взвешенная корреляция
Коэффициент отражательной корреляции
Рефлексивная корреляция — это вариант корреляции Пирсона, в котором данные не сосредоточены вокруг их средних значений. [ нужна ссылка ] Рефлективная корреляция населения
Рефлексивная корреляция симметрична, но не инвариантна при трансляции:
Взвешенная версия выборочной отражательной корреляции:
Масштабированный коэффициент корреляции
Масштабированная корреляция — это вариант корреляции Пирсона, в котором диапазон данных ограничен намеренно и контролируемым образом, чтобы выявить корреляции между быстрыми компонентами временных рядов . [41] Масштабированная корреляция определяется как средняя корреляция между короткими сегментами данных.
Пусть будет число сегментов, которые могут вписаться в общую длину сигнала для данного масштаба :
Масштабированная корреляция по всем сигналам затем вычисляется как
где коэффициент корреляции Пирсона для сегмента .
При выборе параметра диапазон значений сокращается и корреляции на длительном временном масштабе отфильтровываются, выявляются только корреляции на коротких временных масштабах. Таким образом, вклады медленных компонент удаляются, а вклады быстрых компонент сохраняются.
Расстояние Пирсона
Метрика расстояния для двух переменных X и Y , известная как расстояние Пирсона, может быть определена на основе их коэффициента корреляции как [42]
Учитывая, что коэффициент корреляции Пирсона находится в диапазоне [−1, +1], расстояние Пирсона лежит в диапазоне [0, 2]. Расстояние Пирсона использовалось в кластерном анализе и обнаружении данных для связи и хранения с неизвестным усилением и смещением. [43]
Определенное таким образом «расстояние» Пирсона присваивает расстояние больше 1 отрицательным корреляциям. В действительности, имеют значение как сильная положительная, так и отрицательная корреляция, поэтому необходимо соблюдать осторожность, когда «расстояние» Пирсона используется для алгоритма ближайшего соседа, поскольку такой алгоритм будет включать только соседей с положительной корреляцией и исключать соседей с отрицательной корреляцией. В качестве альтернативы можно применить абсолютное расстояние , которое будет учитывать как положительные, так и отрицательные корреляции. Информацию о положительных и отрицательных ассоциациях можно будет извлечь позже отдельно.
Коэффициент круговой корреляции
Для переменных X = { x 1 ,..., x n } и Y = { y 1 ,..., y n }, которые определены на единичной окружности [0, 2π) , можно определить круговой аналог коэффициента Пирсона. [44] Это делается путем преобразования точек данных по X и Y с помощью синусоидальной функции, так что коэффициент корреляции задается как:
где и — круговые средние X и Y. _ Эта мера может быть полезна в таких областях, как метеорология, где важно угловое направление данных.
Частичная корреляция
Если совокупность или набор данных характеризуются более чем двумя переменными, коэффициент частичной корреляции измеряет силу зависимости между парой переменных, которая не учитывается тем, как они обе изменяются в ответ на изменения в выбранном подмножестве. других переменных.
Декорреляция n случайных величин
Всегда можно удалить корреляции между всеми парами произвольного числа случайных величин с помощью преобразования данных, даже если связь между переменными нелинейна. Представление этого результата для распределения населения дано Коксом и Хинкли. [45]
Соответствующий результат существует для сведения выборочных корреляций к нулю. Предположим, что вектор из n случайных величин наблюдается m раз. Пусть X — матрица, где — j- я переменная наблюдения i . Пусть это квадратная матрица размером m на m с каждым элементом 1. Тогда D — это данные, преобразованные так, что каждая случайная величина имеет нулевое среднее значение, а T — это данные, преобразованные так, чтобы все переменные имели нулевое среднее значение и нулевую корреляцию со всеми другими переменными — выборочная корреляция . матрица T будет единичной матрицей . Чтобы получить единичную дисперсию, это значение необходимо разделить на стандартное отклонение. Преобразованные переменные не будут коррелированы, даже если они не будут независимыми .
где показатель степени —+1 ⁄ 2 представляет собой матричный квадратный корень из обратной матрицы. Корреляционная матрица T будет единичной матрицей. Если новое наблюдение данных x представляет собой вектор-строку из n элементов, то то же преобразование можно применить к x , чтобы получить преобразованные векторы d и t :
^ Также известный как r Пирсона , коэффициент корреляции момента произведения Пирсона ( PPMCC ), двумерная корреляция , [1] или просто неквалифицированный коэффициент корреляции [2]
↑ Еще в 1877 году Гальтон использовал термин «реверсия» и символ « r » для обозначения того, что впоследствии стало «регрессией». [3] [4] [5]
Рекомендации
^ «Учебные пособия по SPSS: корреляция Пирсона» .
^ «Коэффициент корреляции: простое определение, формула, простые шаги» . Статистика Как сделать .
^ Гальтон, Ф. (5–19 апреля 1877 г.). «Типичные законы наследственности». Природа . 15 (388, 389, 390): 492–495, 512–514, 532–533. Бибкод : 1877Natur..15..492.. doi : 10.1038/015492a0 . S2CID 4136393.В «Приложении» на стр. 532 Гальтон использует термин «реверсия» и символ r .
↑ Гальтон, Ф. (24 сентября 1885 г.). «Британская ассоциация: Секция II, Антропология: Вступительная речь Фрэнсиса Гальтона, ФРС и т. д., президента Антропологического института, президента секции». Природа . 32 (830): 507–510.
^ Гальтон, Ф. (1886). «Регрессия к посредственности в наследственном росте». Журнал Антропологического института Великобритании и Ирландии . 15 : 246–263. дои : 10.2307/2841583. JSTOR 2841583.
↑ Пирсон, Карл (20 июня 1895 г.). «Заметки о регрессии и наследовании в случае двух родителей». Труды Лондонского королевского общества . 58 : 240–242. Бибкод : 1895RSPS...58..240P.
^ Стиглер, Стивен М. (1989). «Отчет Фрэнсиса Гальтона об изобретении корреляции». Статистическая наука . 4 (2): 73–79. дои : 10.1214/ss/1177012580 . JSTOR 2245329.
^ «Математический анализ вероятностей ошибок в ситуации в точке» . Память акад. Рой. наук. Инст. Франция . наук. Математика и физика. (На французском). 9 : 255–332. 1844 г. - через Google Книги.
^ Райт, С. (1921). «Корреляция и причинно-следственная связь». Журнал сельскохозяйственных исследований . 20 (7): 557–585.
^ abcde Реальная статистика с использованием Excel, «Основные понятия корреляции», получено 22 февраля 2015 г.
^ Вайсштейн, Эрик В. «Статистическая корреляция». Вольфрам Математический мир . Проверено 22 августа 2020 г.
^ Мория, Н. (2008). «Многомерный оптимальный совместный анализ, связанный с шумом, в продольных стохастических процессах». В Ян, Фэншань (ред.). Прогресс в прикладном математическом моделировании . Nova Science Publishers, Inc., стр. 223–260. ISBN978-1-60021-976-4.
↑ Гаррен, Стивен Т. (15 июня 1998 г.). «Оценка максимального правдоподобия коэффициента корреляции в двумерной нормальной модели с отсутствующими данными». Статистика и вероятностные буквы . 38 (3): 281–288. дои : 10.1016/S0167-7152(98)00035-2.
^ "2,6 - (Пирсон) Коэффициент корреляции r" . СТАТ 462 . Проверено 10 июля 2021 г.
^ «Вводная бизнес-статистика: коэффициент корреляции r». opentextbc.ca . Проверено 21 августа 2020 г.
^ Шмид, Джон младший (декабрь 1947 г.). «Взаимосвязь между коэффициентом корреляции и углом между линиями регрессии». Журнал образовательных исследований . 41 (4): 311–313. дои : 10.1080/00220671.1947.10881608. JSTOR 27528906.
^ Раммель, Р.Дж. (1976). «Понимание корреляции». гл. 5 (как показано для особого случая в следующем параграфе).
^ Буда, Анджей; Яриновский, Анджей (декабрь 2010 г.). Время жизни корреляций и его приложения . Видавництво Незалежне. стр. 5–21. ISBN9788391527290.
^ Аб Коэн, Дж. (1988). Статистический анализ мощности для поведенческих наук (2-е изд.).
^ Боули, Алабама (1928). «Стандартное отклонение коэффициента корреляции». Журнал Американской статистической ассоциации . 23 (161): 31–34. дои : 10.2307/2277400. ISSN 0162-1459. JSTOR 2277400.
^ «Вывод стандартной ошибки для коэффициента корреляции Пирсона». Крест проверен . Проверено 30 июля 2021 г.
^ Рахман, Н.А. (1968) Курс теоретической статистики , Чарльз Гриффин и компания, 1968
^ Кендалл, М.Г., Стюарт, А. (1973) Передовая теория статистики, Том 2: Выводы и взаимосвязи , Гриффин. ISBN 0-85264-215-6 (раздел 31.19)
^ Сопер, HE ; Янг, AW; Пещера, БМ; Ли, А.; Пирсон, К. (1917). «О распределении коэффициента корреляции в малых выборках. Приложение II к статьям «Студента» и Р.А. Фишера. Совместное исследование». Биометрика . 11 (4): 328–413. дои : 10.1093/биомет/11.4.328.
^ Дэйви, Кэтрин Э.; Грейден, Дэвид Б.; Иган, Гэри Ф.; Джонстон, Ли А. (январь 2013 г.). «Фильтрация вызывает корреляцию в данных о состоянии покоя фМРТ». НейроИмидж . 64 : 728–740. doi :10.1016/j.neuroimage.2012.08.022. hdl : 11343/44035 . PMID 22939874. S2CID 207184701.
^ Хотеллинг, Гарольд (1953). «Новый взгляд на коэффициент корреляции и его преобразования». Журнал Королевского статистического общества . Серия Б (Методическая). 15 (2): 193–232. doi :10.1111/j.2517-6161.1953.tb00135.x. JSTOR 2983768.
^ Кенни, Дж. Ф.; Хранение, Е.С. (1951). Математика статистики . Том. Часть 2 (2-е изд.). Принстон, Нью-Джерси: Ван Ностранд.
^ Вайсштейн, Эрик В. «Коэффициент корреляции - двумерное нормальное распределение». Вольфрам Математический мир .
^ Таральдсен, Гуннар (2020). «Уверенность в корреляции». Исследовательские ворота . дои : 10.13140/RG.2.2.23673.49769 .
^ Лай, Чун Синг; Тао, Иншань; Сюй, Фанъюань; Нг, Крыло, Вайоминг; Цзя, Ювэй; Юань, Хаолян; Хуан, Чао; Лай, Лой Лей; Сюй, Чжао; Локателли, Джорджо (январь 2019 г.). «Надежная система корреляционного анализа для несбалансированных и дихотомических данных с неопределенностью» (PDF) . Информационные науки . 470 : 58–77. doi :10.1016/j.ins.2018.08.017. S2CID 52878443.
^ Аб Уилкокс, Рэнд Р. (2005). Введение в робастную оценку и проверку гипотез . Академическая пресса.
^ Девлин, Сьюзен Дж .; Гнанадэсикан, Р.; Кеттенринг-младший (1975). «Надежная оценка и обнаружение выбросов с помощью коэффициентов корреляции». Биометрика . 62 (3): 531–545. дои : 10.1093/biomet/62.3.531. JSTOR 2335508.
↑ Ваарт, А.В. ван дер (13 октября 1998 г.). Асимптотическая статистика. Издательство Кембриджского университета. ISBN978-0-511-80225-6.
^ Кац., Митчелл Х. (2006) Многомерный анализ – практическое руководство для клиницистов . 2-е издание. Издательство Кембриджского университета. ISBN 978-0-521-54985-1 . ISBN 0-521-54985-X
^ Хотеллинг, Х. (1953). «Новый взгляд на коэффициент корреляции и его преобразования». Журнал Королевского статистического общества. Серия Б (Методическая) . 15 (2): 193–232. doi :10.1111/j.2517-6161.1953.tb00135.x. JSTOR 2983768.
^ Олкин, Ингрэм; Пратт, Джон В. (март 1958 г.). «Непредвзятая оценка некоторых коэффициентов корреляции». Анналы математической статистики . 29 (1): 201–211. дои : 10.1214/aoms/1177706717 . JSTOR 2237306..
^ Фулекар (ред.), MH (2009) Биоинформатика: приложения в науках о жизни и окружающей среде , Springer (стр. 110) ISBN 1-4020-8879-5
^ Имминк, К. Шухамер; Вебер, Дж. (октябрь 2010 г.). «Обнаружение минимального расстояния Пирсона для многоуровневых каналов с несоответствием усиления и/или смещения». Транзакции IEEE по теории информации . 60 (10): 5966–5974. CiteSeerX 10.1.1.642.9971 . дои : 10.1109/tit.2014.2342744. S2CID 1027502 . Проверено 11 февраля 2018 г.
^ Джаммаламадака, С. Рао; СенГупта, А. (2001). Темы круговой статистики. Нью-Джерси: World Scientific. п. 176. ИСБН978-981-02-3778-3. Проверено 21 сентября 2016 г.
В Викиверситете есть учебные ресурсы по линейной корреляции.
«кокор». сайт сравнения корреляций .– Бесплатный веб-интерфейс и пакет R для статистического сравнения двух зависимых или независимых корреляций с перекрывающимися или непересекающимися переменными.
«Корреляция». nagysandor.eu .– интерактивное Flash-моделирование корреляции двух нормально распределенных переменных.
«Критические значения коэффициента корреляции Пирсона» (PDF) . Frank.mtsu.edu/~dkfuller .– большой стол.
«Угадай корреляцию».– Игра, в которой игроки угадывают, насколько коррелируют две переменные на диаграмме рассеяния, чтобы лучше понять концепцию корреляции.












![{\displaystyle \operatorname {cov} (X,Y)=\operatorname {\mathbb {E} } [(X-\mu _{X})(Y-\mu _{Y})],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1e88bc4ba085b98d5cca09b958ad378d50127308)

![{\displaystyle \rho _{X,Y} = {\frac {\operatorname {\mathbb {E} } [(X-\mu _{X})(Y-\mu _{Y})]}{\ сигма _{X}\сигма _{Y}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/042c646e848d2dc6e15d7b5c7a5b891941b2eab6)



![{\displaystyle {\begin{aligned}\mu _{X}={}&\operatorname {\mathbb {E} } [\,X\,]\\\mu _{Y}={}&\operatorname { \mathbb {E} } [\,Y\,]\\\sigma _{X}^{2}={}&\operatorname {\mathbb {E} } \left[\,\left(X-\operatorname {\mathbb {E} } [X]\right)^{2}\,\right]=\operatorname {\mathbb {E} } \left[\,X^{2}\,\right]-\left (\operatorname {\mathbb {E} } [\,X\,]\right)^{2}\\\sigma _{Y}^{2}={}&\operatorname {\mathbb {E} } \ left[\,\left(Y-\operatorname {\mathbb {E} } [Y]\right)^{2}\,\right]=\operatorname {\mathbb {E} } \left[\,Y^ {2}\,\right]-\left(\,\operatorname {\mathbb {E} } [\,Y\,]\right)^{2}\\&\operatorname {\mathbb {E} } [ \,\left(X-\mu _{X}\right)\left(Y-\mu _{Y}\right)\,]=\operatorname {\mathbb {E} } [\,\left(X -\operatorname {\mathbb {E} } [\,X\,]\right)\left(Y-\operatorname {\mathbb {E} } [\,Y\,]\right)\,]=\operatorname {\mathbb {E} } [\,X\,Y\,]-\operatorname {\mathbb {E} } [\,X\,]\operatorname {\mathbb {E} } [\,Y\,] \,,\end{выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a2469cdb397ef7d50c200b03c9e9f7311f0ab2b1)
![{\displaystyle \rho _{X,Y} = {\frac {\operatorname {\mathbb {E} } [\,X\,Y\,]-\operatorname {\mathbb {E} } [\,X\ ,]\operatorname {\mathbb {E} } [\,Y\,]}{{\sqrt {\operatorname {\mathbb {E} } \left[\,X^{2}\,\right]-\ left(\operatorname {\mathbb {E} } [\,X\,]\right)^{2}}}~{\sqrt {\operatorname {\mathbb {E} } \left[\,Y^{2 }\,\right]-\left(\operatorname {\mathbb {E} } [\,Y\,]\right)^{2}}}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5984dfb290912b0e0b92a984bf49cdd628c38b2c)










































![{\displaystyle z={\frac {x- {\text{mean}}}{\text{SE}}}=[F(r)-F(\rho _{0})]{\sqrt {n- 3}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/da7a3d54a70f9005e3bf9a2accf62cbf0fa0ea71)

![{\displaystyle 100(1-\alpha)\%{\text{CI}}:\operatorname {artanh} (\rho)\in [\operatorname {artanh} (r)\pm z_ {\alpha /2}{ \text{SE}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/affc3f0ee39499c97bb851229113f49d83100bf2)
![{\displaystyle 100(1-\alpha)\%{\text{CI}}:\rho \in [\tanh(\operatorname {artanh} (r)-z_{\alpha /2}{\text{SE} }),\tanh(\operatorname {artanh} (r)+z_{\alpha /2}{\text{SE}})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf658969d39ea848505750b5cd76db21da78dd5c)








![{\displaystyle {\begin{aligned}r(Y,{\hat {Y}})&={\frac {\sum _{i}(Y_{i}-{\bar {Y}})({\ шляпа {Y}}_{i}-{\bar {Y}})}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \ sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\frac {\sum _{i} (Y_{i}-{\hat {Y}}_{i}+{\hat {Y}}_{i}-{\bar {Y}})({\hat {Y}}_{i} -{\bar {Y}})}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\frac {\sum _{i}[(Y_{i}-{\ шляпа {Y}}_{i})({\hat {Y}}_{i}-{\bar {Y}})+({\hat {Y}}_{i}-{\bar {Y }})^{2}]}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{i}({\hat { Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\frac {\sum _{i}({\hat {Y}}_{ i}-{\bar {Y}})^{2}}{\sqrt {\sum _{i}(Y_{i}-{\bar {Y}})^{2}\cdot \sum _{ i}({\hat {Y}}_{i}-{\bar {Y}})^{2}}}}\\[6pt]&={\sqrt {\frac {\sum _{i} ({\hat {Y}}_{i}-{\bar {Y}})^{2}}{\sum _{i}(Y_{i}-{\bar {Y}})^{2 }}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d86595f3f77e8ee96952760d9176a5fa140cc562)









![{\displaystyle \operatorname {\mathbb {E} } \left[r\right]=\rho - {\frac {\rho \left(1-\rho ^{2}\right)}{2n}}+\ cdots ,\quad }](https://wikimedia.org/api/rest_v1/media/math/render/svg/683b838e709e3b32a3c22dfec4fa665a593f42ad)







![{\displaystyle \operatorname {corr} _{r}(X,Y)={\frac {\operatorname {\mathbb {E} } [\,X\,Y\,]}{\sqrt {\operatorname {\ mathbb {E} } [\,X^{2}\,]\cdot \operatorname {\mathbb {E} } [\,Y^{2}\,]}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6d897e4b303a062ed14cc9f88f35f5c8ffc91f7)




















