Вычислительная модель, используемая в машинном обучении, основанная на связанных иерархических функциях.
Искусственная нейронная сеть — это взаимосвязанная группа узлов, созданная на основе упрощения нейронов мозга . Здесь каждый круглый узел представляет собой искусственный нейрон , а стрелка представляет соединение выхода одного искусственного нейрона со входом другого.
Искусственные нейронные сети ( ИНС , также сокращенно до нейронных сетей (НС) или нейронных сетей ) — это ветвь моделей машинного обучения , которые построены с использованием принципов нейронной организации, открытых коннекционизмом в биологических нейронных сетях, составляющих мозг животных . [1] [2]
ИНС состоит из связанных единиц или узлов, называемых искусственными нейронами , которые в общих чертах моделируют нейроны биологического мозга. Они соединены ребрами , моделирующими синапсы биологического мозга. Искусственный нейрон получает сигналы от связанных нейронов, затем обрабатывает их и отправляет сигнал другим подключенным нейронам. «Сигнал» — это действительное число , а выход каждого нейрона вычисляется некоторой нелинейной функцией суммы его входов, называемой функцией активации . Нейроны и ребра обычно имеют вес , который корректируется по мере обучения. Вес увеличивает или уменьшает силу сигнала при соединении.
Обычно нейроны объединяются в слои. Разные слои могут выполнять разные преобразования на своих входах. Сигналы перемещаются от первого слоя ( входной уровень ) к последнему уровню ( выходной уровень ), возможно, проходя через несколько промежуточных слоев ( скрытые уровни ). Сеть обычно называется глубокой нейронной сетью, если она имеет как минимум два скрытых слоя. [3]
Искусственные нейронные сети используются для прогнозного моделирования , адаптивного управления и других приложений, где их можно обучать с помощью набора данных. Их также используют для решения задач в области искусственного интеллекта . Сети могут учиться на опыте и делать выводы из сложного и, казалось бы, несвязанного набора информации.
Обучение
Нейронные сети обычно обучаются посредством минимизации эмпирического риска . Этот метод основан на идее оптимизации параметров сети для минимизации разницы или эмпирического риска между прогнозируемыми выходными данными и фактическими целевыми значениями в данном наборе данных. [4] Для оценки параметров сети обычно используются градиентные методы, такие как обратное распространение ошибки . [4] На этапе обучения ИНС обучаются на помеченных обучающих данных, итеративно обновляя свои параметры, чтобы минимизировать определенную функцию потерь . [5] Этот метод позволяет сети обобщать невидимые данные.
История
Исторически цифровые компьютеры произошли от модели фон Неймана и работают посредством выполнения явных инструкций посредством доступа к памяти несколькими процессорами. С другой стороны, происхождение нейронных сетей основано на попытках смоделировать обработку информации в биологических системах. В отличие от модели фон Неймана, нейронные сети не разделяют память и обработку.
Самый простой вид нейронной сети прямого распространения (FNN) — это линейная сеть, состоящая из одного слоя выходных узлов; входные данные подаются непосредственно на выходы через ряд весов. Сумма произведений весов и входных данных рассчитывается в каждом узле. Среднеквадратические ошибки между этими рассчитанными выходными данными и заданными целевыми значениями сводятся к минимуму за счет корректировки весов. Этот метод известен уже более двух столетий как метод наименьших квадратов или линейная регрессия . Лежандр (1805 г.) и Гаусс (1795 г.) использовали его как средство нахождения хорошей грубой линейной аппроксимации набора точек для предсказания движения планет. [7] [8] [9] [10] [11]
Уоррен Маккалок и Уолтер Питтс [15] (1943) также рассматривали необучающуюся вычислительную модель для нейронных сетей. [16]
В конце 1940-х годов Д.О. Хебб [17] создал гипотезу обучения , основанную на механизме нейронной пластичности , которая стала известна как обучение Хебба . Хеббианское обучение считается «типичным» правилом обучения без присмотра , а его более поздние варианты были ранними моделями долгосрочного потенцирования . Эти идеи начали применяться к вычислительным моделям в 1948 году с « неорганизованными машинами » Тьюринга. Фарли и Уэсли Кларк [18] были первыми, кто смоделировал сеть Хебба в 1954 году в Массачусетском технологическом институте. Они использовали вычислительные машины, которые тогда назывались «калькуляторами». Другие вычислительные машины с нейронными сетями были созданы Рочестером, Холландом, Хабитом и Дудой [19] в 1956 году. В 1958 году психолог Фрэнк Розенблатт изобрел перцептрон , первую реализованную искусственную нейронную сеть, [20] [21] [22] [23] ] финансируется Управлением военно-морских исследований США . [24]
Изобретение перцептрона вызвало общественный интерес к исследованиям в области искусственных нейронных сетей, что заставило правительство США резко увеличить финансирование исследований в области глубокого обучения. Это привело к «золотому веку искусственного интеллекта», чему способствовали оптимистические заявления ученых-компьютерщиков относительно способности перцептронов имитировать человеческий интеллект. [25] Например, в 1957 году Герберт Саймон сказал: [25]
У меня нет цели удивить или шокировать вас, но самый простой способ, которым я могу подвести итог, — это сказать, что сейчас в мире существуют машины, которые думают, учатся и творят. Более того, их способность делать эти вещи будет быстро возрастать до тех пор, пока — в обозримом будущем — диапазон проблем, с которыми они могут справиться, не станет таким же обширным, как и диапазон, к которому применяется человеческий разум.
Однако это было не так, поскольку исследования в Соединенных Штатах застопорились после работы Мински и Паперта (1969), [26] которые обнаружили, что базовые перцептроны неспособны обрабатывать схему «исключительное-или» и что компьютерам не хватает мощности для этого. обучайте полезные нейронные сети. Это, наряду с другими факторами, такими как отчет Лайтхилла 1973 года Джеймса Лайтхилла , в котором говорится, что исследования в области искусственного интеллекта «не дали того серьезного эффекта, который тогда был обещан», прекращение финансирования исследований в области ИИ во всех университетах США, кроме двух. Великобритании и во многих крупных учреждениях по всему миру. [27] Это положило начало эпохе, получившей название « Зима ИИ» , когда исследования в области коннекционизма сократились из-за уменьшения государственного финансирования и повышенного внимания к символическому искусственному интеллекту в США и других западных странах. [28] [27]
Архитектура сверточной нейронной сети (CNN) со сверточными слоями и слоями понижающей дискретизации была представлена Кунихико Фукусимой в 1980 году . [38] Он назвал ее неокогнитроном . В 1969 году он также представил функцию активации ReLU (выпрямленная линейная единица) . [39] [10] Выпрямитель стал самой популярной функцией активации для CNN и глубоких нейронных сетей в целом. [40] CNN стали важным инструментом компьютерного зрения .
Ключом к более поздним достижениям в исследованиях искусственных нейронных сетей стал алгоритм обратного распространения ошибки — эффективное применение цепного правила Лейбница (1673) [41] к сетям дифференцируемых узлов. [10] Он также известен как обратный режим автоматического дифференцирования или обратного накопления , согласно Сеппо Линнаинмаа (1970). [42] [43] [44] [45] [10] Термин «обратное распространение ошибки» был введен в 1962 году Фрэнком Розенблаттом , [46] [10] но у него не было реализации этой процедуры, хотя Генри Дж. Келли [47] и Брайсон [48] имели непрерывные предшественники обратного распространения ошибки на основе динамического программирования [29] [49] [50] [51] уже в 1960–61 годах в контексте теории управления . [10]
В 1973 году Дрейфус использовал обратное распространение ошибки для адаптации параметров контроллеров пропорционально градиентам ошибок. [52]
В 1982 году Пол Вербос применил обратное распространение ошибки к MLP способом, который стал стандартным. [53] [49] В 1986 году Румельхарт , Хинтон и Уильямс показали, что метод обратного распространения ошибки научился интересным внутренним представлениям слов в виде векторов признаков при обучении прогнозированию следующего слова в последовательности. [54]
В конце 1970-х — начале 1980-х годов ненадолго возник интерес к теоретическому исследованию модели Изинга Вильгельма Ленца (1920) и Эрнста Изинга (1925) [12]
применительно к топологиям дерева Кэли и большим нейронным сетям . В 1981 году модель Изинга была точно решена Питером Бартом для общего случая замкнутых деревьев Кэли (с петлями) с произвольным коэффициентом ветвления [55] и было обнаружено, что она демонстрирует необычное поведение фазового перехода в ее локальной вершине и дальнем участке. - корреляция сайтов. [56] [57]
Нейронная сеть с задержкой по времени (TDNN) Алекса Вайбеля (1987) объединила свертки, распределение веса и обратное распространение ошибки . [58] [59] В 1988 году Вэй Чжан и др. применил обратное распространение ошибки к CNN (упрощенный неокогнитрон со сверточными взаимосвязями между слоями признаков изображения и последним полностью связным слоем) для распознавания алфавита. [60] [61] В 1989 году Янн Лекун и др. обучил CNN распознавать рукописные почтовые индексы в почте. [62]
В 1992 году Хуан Венг и др. представили максимальное объединение CNN. для обеспечения инвариантности при наименьшем сдвиге и устойчивости к деформации для облегчения распознавания трехмерных объектов . [63] [64] [65]
LeNet-5 (1998), 7-уровневая CNN Янна ЛеКуна и др., [66] которая классифицирует цифры, применялась несколькими банками для распознавания рукописных чисел на чеках, оцифрованных в Изображения размером 32х32 пикселя.
Начиная с 1988 года, [67] [68] использование нейронных сетей изменило область предсказания структуры белков , в частности, когда первые каскадные сети обучались на профилях (матрицах), полученных путем множественного выравнивания последовательностей . [69]
В 1980-х годах обратное распространение ошибки не очень хорошо работало для глубоких FNN и RNN. Чтобы преодолеть эту проблему, Юрген Шмидхубер (1992) предложил иерархию RNN, предварительно обучаемых по одному уровню за раз посредством самостоятельного обучения . [70] Он использует прогнозирующее кодирование для изучения внутренних представлений в нескольких самоорганизующихся временных масштабах. Это может существенно облегчить последующее глубокое обучение. Иерархию RNN можно свернуть в единую RNN путем разделения сети блоков более высокого уровня в сеть автоматизатора более низкого уровня . [70] [10] В 1993 году чанкёр решил задачу глубокого обучения, глубина которой превысила 1000. [71]
В 1992 году Юрген Шмидхубер также опубликовал альтернативу RNN [72] , которая теперь называется линейным преобразователем или преобразователем с линеаризованным самообслуживанием [73] [74] [10] (за исключением оператора нормализации). Она изучает внутренние прожекторы внимания : [75] медленная нейронная сеть прямого распространения учится путем градиентного спуска управлять быстрыми весами другой нейронной сети через внешние продукты самогенерируемых шаблонов активации ОТ и ДО (которые теперь называются ключом и значением для себя) . -внимание ). [73] Это быстрое отображение внимания к весам применяется к шаблону запроса.
Современный Трансформер был представлен Ашишем Васвани и др. в своей статье 2017 года «Внимание — это все, что вам нужно». [76]
Он сочетает в себе это с оператором softmax и матрицей проекции. [10]
Трансформаторы все чаще становятся предпочтительной моделью для обработки естественного языка . [77] Его используют многие современные модели больших языков, такие как ChatGPT , GPT-4 и BERT . Трансформаторы также все чаще используются в компьютерном зрении . [78]
В 1991 году Юрген Шмидхубер также опубликовал состязательные нейронные сети , которые соревнуются друг с другом в форме игры с нулевой суммой , где выигрыш одной сети является проигрышем другой сети. [79] [80] [81] Первая сеть представляет собой генеративную модель , которая моделирует распределение вероятностей по шаблонам выходных данных. Вторая сеть учится с помощью градиентного спуска предсказывать реакцию окружающей среды на эти закономерности. Это называлось «искусственным любопытством».
В 2014 году этот принцип был использован в генеративно-состязательной сети (GAN) Яном Гудфеллоу и др. [82] Здесь реакция окружающей среды равна 1 или 0 в зависимости от того, находится ли выход первой сети в данном наборе. Это можно использовать для создания реалистичных дипфейков . [83]
Превосходное качество изображения достигается с помощью StyleGAN (2018) от Nvidia [84], основанного на Progressive GAN Теро Карраса, Тимо Айла, Самули Лайне и Яакко Лехтинена. [85] Здесь генератор GAN растет от малого к большому по пирамидальной схеме.
Дипломную работу Зеппа Хохрайтера (1991) [86] его научный руководитель Юрген Шмидхубер назвал «одним из важнейших документов в истории машинного обучения» . [10] Хохрейтер идентифицировал и проанализировал проблему исчезающего градиента [86] [87] и предложил рекуррентные остаточные связи для ее решения. Это привело к созданию метода глубокого обучения под названием « длинная краткосрочная память» (LSTM), опубликованного в журнале Neural Computation (1997). [88] Рекуррентные нейронные сети LSTM могут изучать задачи «очень глубокого обучения» [89] с длинными путями присвоения кредитов, которые требуют воспоминаний о событиях, которые произошли за тысячи дискретных шагов времени ранее. «Ванильный LSTM» с затвором забывания был представлен в 1999 году Феликсом Герсом , Шмидхубером и Фредом Камминсом. [90] LSTM стала самой цитируемой нейронной сетью 20-го века. [10]
В 2015 году Рупеш Кумар Шривастава, Клаус Грефф и Шмидхубер использовали принцип LSTM для создания сети Highway — нейронной сети прямого распространения с сотнями слоев, гораздо более глубокой, чем предыдущие сети. [91] [92] 7 месяцев спустя, Каймин Хэ, Сянъюй Чжан; Шаоцин Рен и Цзянь Сунь выиграли конкурс ImageNet 2015, предложив вариант сети шоссе с открытыми воротами или без ворот под названием Остаточная нейронная сеть . [93] Эта нейронная сеть стала самой цитируемой в 21 веке. [10]
Первые успехи нейронных сетей включали предсказание фондового рынка, а в 1995 году (в основном) беспилотный автомобиль. [а] [95]
Джеффри Хинтон и др. (2006) предложили изучать представление высокого уровня с использованием последовательных слоев бинарных или вещественнозначных скрытых переменных с помощью ограниченной машины Больцмана [96] для моделирования каждого слоя. В 2012 году Нг и Дин создали сеть, которая научилась распознавать понятия более высокого уровня, такие как кошки, только при просмотре немаркированных изображений. [97] Предварительное обучение без присмотра и увеличение вычислительной мощности графических процессоров и распределенных вычислений позволили использовать более крупные сети, особенно для задач распознавания изображений и визуальных эффектов, которые стали известны как « глубокое обучение ». [5]
Вычислительные устройства были созданы на КМОП как для биофизического моделирования, так и для нейроморфных вычислений . Более поздние усилия показывают перспективу создания наноустройств для очень крупномасштабного анализа главных компонентов и свертки . [101] В случае успеха эти усилия могут открыть новую эру нейронных вычислений , которая является шагом за пределы цифровых вычислений, [102] потому что они зависят от обучения , а не от программирования , и потому что они по своей сути являются аналоговыми , а не цифровыми , даже несмотря на то, что первые экземпляры на самом деле может быть с цифровыми устройствами CMOS.
Чиресан и его коллеги (2010) [103] показали, что, несмотря на исчезающую проблему градиента , графические процессоры делают возможным обратное распространение ошибки для многослойных нейронных сетей с прямой связью. [104] В период с 2009 по 2012 год ИНС начали выигрывать призы в конкурсах по распознаванию изображений, приближаясь к человеческому уровню в выполнении различных задач, первоначально в распознавании образов и распознавании рукописного текста . [105] [106] Например, двунаправленная и многомерная длинная кратковременная память (LSTM) [107] [108] Graves et al. выиграл три конкурса по распознаванию рукописного ввода в 2009 году, не имея никаких предварительных знаний о трех языках, которые предстоит выучить. [107] [108]
Чиресан и его коллеги создали первые распознаватели образов для достижения конкурентоспособных/сверхчеловеческих показателей [109] на таких тестах, как распознавание дорожных знаков (IJCNN 2012).
Рамензанпур и др. в 2020 году показал, что аналитические и вычислительные методы, основанные на статистической физике неупорядоченных систем, можно распространить на крупномасштабные задачи, включая машинное обучение, например, для анализа весового пространства глубоких нейронных сетей . [111]
Модели
Нейрон и миелинизированный аксон с потоком сигналов от входов дендритов к выходам терминалей аксона.
ИНС возникли как попытка использовать архитектуру человеческого мозга для выполнения задач, с которыми традиционные алгоритмы не имели большого успеха. Вскоре они переориентировались на улучшение эмпирических результатов, отказавшись от попыток оставаться верными своим биологическим предшественникам. ИНС обладают способностью обучаться и моделировать нелинейности и сложные взаимосвязи. Это достигается за счет соединения нейронов по различным схемам, что позволяет выходным сигналам одних нейронов становиться входными данными для других. Сеть образует ориентированный взвешенный граф . [112]
Искусственная нейронная сеть состоит из смоделированных нейронов. Каждый нейрон связан с другими узлами посредством связей, подобных биологической связи аксон-синапс-дендрит. Все узлы, соединенные ссылками, принимают некоторые данные и используют их для выполнения определенных операций и задач с данными. Каждое звено имеет вес, определяющий силу влияния одного узла на другой, [113] позволяя весам выбирать сигнал между нейронами.
Искусственные нейроны
ИНС состоят из искусственных нейронов , которые концептуально произошли от биологических нейронов . Каждый искусственный нейрон имеет входы и выдает один выходной сигнал, который можно отправить нескольким другим нейронам. [114] Входные данные могут быть значениями признаков выборки внешних данных, таких как изображения или документы, или они могут быть выходными данными других нейронов. Выходы конечных выходных нейронов нейронной сети выполняют такую задачу, как распознавание объекта на изображении.
Чтобы найти выход нейрона, мы берем взвешенную сумму всех входов, взвешенную по весам связей от входов к нейрону. Мы добавляем к этой сумме слагаемое смещения . [115] Эту взвешенную сумму иногда называют активацией . Эта взвешенная сумма затем передается через (обычно нелинейную) функцию активации для получения выходных данных. Исходными входными данными являются внешние данные, такие как изображения и документы. Конечные результаты выполняют задачу, например, распознавание объекта на изображении. [116]
Организация
Нейроны обычно организованы в несколько слоев, особенно при глубоком обучении . Нейроны одного слоя соединяются только с нейронами непосредственно предшествующего и непосредственно последующего слоев. Уровень, который получает внешние данные, является входным слоем . Слой, который дает конечный результат, является выходным слоем . Между ними находится ноль или более скрытых слоев . Также используются однослойные и многоуровневые сети. Между двумя слоями возможны несколько шаблонов соединения. Они могут быть «полностью связанными», когда каждый нейрон одного слоя соединяется с каждым нейроном следующего слоя. Они могут быть объединенными , когда группа нейронов в одном слое соединяется с одним нейроном в следующем слое, тем самым уменьшая количество нейронов в этом слое. [117] Нейроны только с такими связями образуют направленный ациклический граф и известны как сети прямого распространения . [118] Альтернативно, сети, которые обеспечивают соединения между нейронами в том же или предыдущих слоях, известны как рекуррентные сети . [119]
Гиперпараметр
Гиперпараметр — это постоянный параметр , значение которого устанавливается до начала процесса обучения. Значения параметров получаются путем обучения. Примеры гиперпараметров включают скорость обучения , количество скрытых слоев и размер пакета. [120] Значения некоторых гиперпараметров могут зависеть от значений других гиперпараметров. Например, размер некоторых слоев может зависеть от общего количества слоев.
Обучение
Обучение — это адаптация сети для лучшего выполнения задачи путем рассмотрения выборочных наблюдений. Обучение включает в себя корректировку весов (и дополнительных порогов) сети для повышения точности результата. Это достигается за счет минимизации наблюдаемых ошибок. Обучение считается завершенным, когда изучение дополнительных наблюдений не снижает коэффициент ошибок. Даже после обучения частота ошибок обычно не достигает 0. Если после обучения частота ошибок слишком высока, сеть обычно необходимо перепроектировать. Практически это делается путем определения функции стоимости , которая периодически оценивается во время обучения. Пока его производительность продолжает снижаться, обучение продолжается. Стоимость часто определяется как статистика , значение которой может быть только приблизительно оценено. Выходные данные на самом деле представляют собой числа, поэтому, когда ошибка мала, разница между выходными данными (почти наверняка кот) и правильным ответом (кошка) невелика. Обучение пытается уменьшить общую сумму различий между наблюдениями. Большинство моделей обучения можно рассматривать как прямое применение теории оптимизации и статистической оценки . [112] [121]
Скорость обучения
Скорость обучения определяет размер корректирующих шагов, которые модель предпринимает для корректировки ошибок в каждом наблюдении. [122] Высокая скорость обучения сокращает время обучения, но с более низкой предельной точностью, в то время как более низкая скорость обучения занимает больше времени, но с потенциалом большей точности. Оптимизации, такие как Quickprop, в первую очередь направлены на ускорение минимизации ошибок, тогда как другие улучшения в основном направлены на повышение надежности. Чтобы избежать колебаний внутри сети, таких как чередование весов соединений, и улучшить скорость сходимости, в уточнениях используется адаптивная скорость обучения , которая увеличивается или уменьшается по мере необходимости. [123] Концепция импульса позволяет взвесить баланс между градиентом и предыдущим изменением, так что корректировка веса зависит в некоторой степени от предыдущего изменения. Импульс, близкий к 0, подчеркивает градиент, а значение, близкое к 1, подчеркивает последнее изменение.
Обратное распространение ошибки — это метод, используемый для корректировки весов соединений для компенсации каждой ошибки, обнаруженной во время обучения. Сумма ошибки эффективно распределяется между соединениями. Технически обратное распространение вычисляет градиент (производную) функции стоимости , связанной с данным состоянием, по отношению к весам. Обновления веса могут быть выполнены с помощью стохастического градиентного спуска или других методов, таких как машины экстремального обучения , [124] сети «без опоры», [125] обучение без обратного отслеживания, [126] «невесомые» сети, [127] [128 ] ] и неконнекционистские нейронные сети . [ нужна цитата ]
Обучение с учителем использует набор парных входов и желаемых результатов. Задача обучения состоит в том, чтобы получить желаемый результат для каждого входа. В этом случае функция затрат связана с устранением неверных вычетов. [132] Обычно используемая стоимость — это среднеквадратическая ошибка , которая пытается минимизировать среднеквадратичную ошибку между выходом сети и желаемым выходом. Задачи, подходящие для обучения с учителем, — это распознавание образов (также известное как классификация) и регрессия (также известная как аппроксимация функций). Обучение с учителем также применимо к последовательным данным (например, для распознавания рукописного текста, речи и жестов ). Это можно рассматривать как обучение с «учителем» в виде функции, обеспечивающей непрерывную обратную связь о качестве полученных к настоящему моменту решений.
Обучение без присмотра
При обучении без учителя входные данные передаются вместе с функцией стоимости, некоторой функцией данных и выходными данными сети. Функция стоимости зависит от задачи (области модели) и любых априорных предположений (неявных свойств модели, ее параметров и наблюдаемых переменных). В качестве тривиального примера рассмотрим модель, где – константа и стоимость . Минимизация этой стоимости дает значение, равное среднему значению данных. Функция стоимости может быть гораздо более сложной. Его форма зависит от приложения: например, при сжатии он может быть связан с взаимной информацией между и , тогда как при статистическом моделировании он может быть связан с апостериорной вероятностью модели с учетом данных (обратите внимание, что в обоих этих примерах , эти количества будут максимизированы, а не минимизированы). Задачи, подпадающие под парадигму обучения без учителя, относятся к задачам общей оценки ; приложения включают кластеризацию , оценку статистических распределений , сжатие и фильтрацию .
Обучение с подкреплением
В таких приложениях, как видеоигры, актер выполняет ряд действий, после каждого из которых получает в целом непредсказуемый ответ от окружающей среды. Цель состоит в том, чтобы выиграть игру, т. е. получить наиболее положительные (с наименьшими затратами) ответы. Целью обучения с подкреплением является взвешивание сети (разработка политики) для выполнения действий, которые минимизируют долгосрочные (ожидаемые совокупные) затраты. В каждый момент времени агент выполняет действие, а среда генерирует наблюдение и мгновенную стоимость в соответствии с некоторыми (обычно неизвестными) правилами. Правила и долгосрочные затраты обычно можно только оценить. В любой момент агент решает, следует ли исследовать новые действия, чтобы выявить связанные с ними затраты, или использовать предыдущее обучение, чтобы действовать быстрее.
Формально среда моделируется как марковский процесс принятия решений (MDP) с состояниями и действиями . Поскольку переходы состояний неизвестны, вместо них используются распределения вероятностей: мгновенное распределение стоимости , распределение наблюдений и распределение переходов , в то время как политика определяется как условное распределение по действиям с учетом наблюдений. В совокупности они определяют цепь Маркова (MC). Цель состоит в том, чтобы найти самый дешевый MC.
ИНС служат компонентом обучения в таких приложениях. [133] [134] Динамическое программирование в сочетании с ИНС (обеспечивающее нейродинамическое программирование) [135] применялось к таким проблемам, как определение маршрута транспортных средств , [136] видеоигры, управление природными ресурсами [137] [138] и медицина [133 ]. 139] из-за способности ИНС компенсировать потери точности даже при уменьшении плотности сетки дискретизации для численной аппроксимации решения задач управления. Задачи, подпадающие под парадигму обучения с подкреплением, — это задачи управления, игры и другие задачи последовательного принятия решений.
Самообучение
Самообучение в нейронных сетях было представлено в 1982 году вместе с нейронной сетью, способной к самообучению, названной перекрестной адаптивной матрицей (CAA). [140] Это система только с одним входом, ситуацией s, и только одним выходом, действием (или поведением) a. Он не имеет ни внешних рекомендаций, ни внешнего подкрепления из окружающей среды. CAA перекрестно вычисляет как решения о действиях, так и эмоции (чувства) в отношении возникших ситуаций. Система управляется взаимодействием познания и эмоций. [141] Учитывая матрицу памяти W =||w(a,s)||, алгоритм самообучения перекрестной панели на каждой итерации выполняет следующие вычисления:
В ситуации s выполните действие a; Получать последствия ситуации; Вычислить эмоции от нахождения в следственной ситуации v(s'); Обновить память перекрестия w'(a,s) = w(a,s) + v(s').
Значение обратного распространения (вторичное подкрепление) — это эмоция по отношению к последствиям ситуации. ВГА существует в двух средах: одна - поведенческая среда, в которой он ведет себя, и другая - генетическая среда, откуда он первоначально и только один раз получает первоначальные эмоции о том, с какими ситуациями придется столкнуться в поведенческой среде. Получив геномный вектор (вектор вида) из генетической среды, ВГА научится целенаправленному поведению в поведенческой среде, содержащей как желательные, так и нежелательные ситуации. [142]
Нейроэволюция
Нейроэволюция может создавать топологии и веса нейронных сетей с использованием эволюционных вычислений . Он конкурирует со сложными подходами градиентного спуска . Одним из преимуществ нейроэволюции является то, что она менее склонна заходить в «тупики». [143]
Стохастическая нейронная сеть
Стохастические нейронные сети , возникшие на основе моделей Шеррингтона-Киркпатрика, представляют собой тип искусственных нейронных сетей, построенных путем введения в сеть случайных изменений либо путем присвоения искусственным нейронам сети стохастических передаточных функций, либо путем присвоения им стохастических весов. Это делает их полезными инструментами для решения задач оптимизации , поскольку случайные колебания помогают сети избежать локальных минимумов . [144] Стохастические нейронные сети, обученные с использованием байесовского подхода, известны как байесовские нейронные сети . [145]
Доступны два режима обучения: стохастический и пакетный. При стохастическом обучении каждый ввод создает корректировку веса. При пакетном обучении веса корректируются на основе пакета входных данных, накапливая ошибки по всему пакету. Стохастическое обучение вносит в процесс «шум», используя локальный градиент, рассчитанный на основе одной точки данных; это снижает вероятность того, что сеть застрянет в локальных минимумах. Однако пакетное обучение обычно обеспечивает более быстрый и стабильный спуск к локальному минимуму, поскольку каждое обновление выполняется в направлении средней ошибки пакета. Распространенным компромиссом является использование «мини-партий», небольших партий, в каждой партии образцы которых выбираются стохастически из всего набора данных.
Типы
ИНС превратились в широкое семейство методов, которые продвинули современный уровень техники во многих областях. Простейшие типы имеют один или несколько статических компонентов, включая количество модулей, количество слоев, веса модулей и топологию . Динамические типы позволяют одному или нескольким из них развиваться посредством обучения. Последнее намного сложнее, но может сократить период обучения и дать лучшие результаты. Некоторые типы позволяют/требуют обучения под «контролем» оператора, тогда как другие работают независимо. Некоторые типы работают исключительно аппаратно, тогда как другие являются чисто программными и работают на компьютерах общего назначения.
Некоторые из основных прорывов включают в себя:
Сверточные нейронные сети , доказавшие свою эффективность в обработке визуальных и других двумерных данных; [152] [153] где длинная кратковременная память позволяет избежать проблемы исчезающего градиента [154] и может обрабатывать сигналы, которые имеют смесь низкочастотных и высокочастотных компонентов, что способствует распознаванию речи с большим словарным запасом, [155] [156] преобразование текста в текст -синтез речи, [157] [49] [158] и фотореалистичные говорящие головы; [159]
Конкурентные сети, такие как генеративно-состязательные сети , в которых несколько сетей (разной структуры) конкурируют друг с другом в таких задачах, как победа в игре [160] или обман оппонента относительно подлинности входных данных. [82]
Проектирование сети
Использование искусственных нейронных сетей требует понимания их характеристик.
Выбор модели: зависит от представления данных и приложения. Параметры модели включают количество, тип и связность сетевых слоев, а также размер каждого и тип соединения (полное, пуловое и т. д.). Слишком сложные модели обучаются медленно.
Алгоритм обучения . Между алгоритмами обучения существует множество компромиссов. Практически любой алгоритм будет хорошо работать с правильными гиперпараметрами [161] для обучения на конкретном наборе данных. Однако выбор и настройка алгоритма обучения на невидимых данных требует значительного экспериментирования.
Устойчивость : если модель, функция стоимости и алгоритм обучения выбраны правильно, результирующая ИНС может стать устойчивой.
Поиск нейронной архитектуры (NAS) использует машинное обучение для автоматизации проектирования ИНС. Различные подходы к NAS позволяют создавать сети, которые не уступают системам, созданным вручную. Основной алгоритм поиска состоит в том, чтобы предложить модель-кандидат, сравнить ее с набором данных и использовать результаты в качестве обратной связи для обучения сети NAS. [162] Доступные системы включают AutoML и AutoKeras. [163] Библиотека scikit-learn предоставляет функции, помогающие построить глубокую сеть с нуля. Затем мы можем реализовать глубокую сеть с помощью TensorFlow или Keras .
Гиперпараметры также должны быть определены как часть проекта (они не изучаются), определяя такие вопросы, как количество нейронов в каждом слое, скорость обучения, шаг, шаг, глубина, рецептивное поле и заполнение (для CNN) и т. д. [ 164]
Фрагмент кода Python предоставляет обзор функции обучения, которая использует набор обучающих данных, количество модулей скрытого слоя, скорость обучения и количество итераций в качестве параметров:
def train ( X , y , n_hidden , Learning_rate , n_iter ):м , n_input = X. _ форма# 1. случайная инициализация весов и смещенийw1 = np . случайный . randn ( n_input , n_hidden )б1 = НП . нули (( 1 , n_hidden ))w2 = np . случайный . randn ( n_hidden , 1 )б2 = НП . нули (( 1 , 1 ))# 2. на каждой итерации загружать все слои последними значениями веса и смещения.для i в диапазоне ( n_iter + 1 ):z2 = np . точка ( X , w1 ) + b1a2 = сигмовидная ( z2 )z3 = np . точка ( a2 , w2 ) + b2а3 = z3dz3 = а3 - уdw2 = np . точка ( а2 . Т , dz3 )дб2 = НП . сумма ( dz3 , ось = 0 , keepdims = True )dz2 = np . точка ( dz3 , w2 . T ) * sigmoid_derivative ( z2 )dw1 = np . точка ( X . T , dz2 )db1 = np . сумма ( dz2 , ось = 0 )# 3. обновить веса и смещения с помощью градиентовw1 —= скорость обучения * dw1 / mw2 —= скорость обучения * dw2 / мb1 —= скорость обучения * db1 / mb2 —= скорость обучения * db2 / mесли я % 1000 == 0 :print ( "Эпоха" , i , "потеря:" , np . среднее ( np . квадрат ( dz3 )))модель = { "w1" : w1 , "b1" : b1 , "w2" : w2 , "b2" : b2 }возвратная модель
Благодаря своей способности воспроизводить и моделировать нелинейные процессы искусственные нейронные сети нашли применение во многих дисциплинах. К ним относятся:
ИНС использовались для диагностики нескольких типов рака [181] [182] и для различения высокоинвазивных линий раковых клеток от менее инвазивных линий, используя только информацию о форме клеток. [183] [184]
ИНС использовались для ускорения анализа надежности инфраструктур, подверженных стихийным бедствиям [185] [186] , а также для прогнозирования осадок фундаментов. [187] Для смягчения последствий наводнений также может быть полезно использовать ИНС для моделирования дождевого стока. [188] ИНС также использовались для построения моделей «черного ящика» в геонауках : гидрологии , [189] [190] моделировании океана и прибрежной инженерии , [191] [192] и геоморфологии . [193] ИНС используются в сфере кибербезопасности с целью отличить законную деятельность от злонамеренной. Например, машинное обучение использовалось для классификации вредоносного ПО для Android, [194] для идентификации доменов, принадлежащих злоумышленникам, и для обнаружения URL-адресов, представляющих угрозу безопасности. [195] В настоящее время проводятся исследования систем ИНС, предназначенных для тестирования на проникновение, обнаружения бот-сетей, [196] мошенничества с кредитными картами [197] и сетевых вторжений.
ИНС были предложены в качестве инструмента для решения уравнений в частных производных в физике [198] [199] [200] и моделирования свойств открытых квантовых систем многих тел . [201] [202] [203] [204] В исследованиях мозга ИНС изучали кратковременное поведение отдельных нейронов , [205] динамика нейронных цепей возникает в результате взаимодействия между отдельными нейронами и то, как поведение может возникать из абстрактных нейронных модулей, которые представляют собой полные подсистемы. В исследованиях рассматривалась долгосрочная и краткосрочная пластичность нейронных систем и их связь с обучением и памятью от отдельного нейрона до системного уровня.
По картинкам можно создать профиль интересов пользователя, используя искусственные нейронные сети, обученные распознаванию объектов. [206]
Свойство модели «емкость» соответствует ее способности моделировать любую заданную функцию. Это связано с объемом информации, которая может храниться в сети, и с понятием сложности. Сообществу известны два понятия емкости. Информационная емкость и размерность венчурного капитала. Информационная емкость перцептрона интенсивно обсуждается в книге сэра Дэвида Маккея [210] , которая обобщает работу Томаса Ковера. [211] Емкость сети стандартных нейронов (не сверточных) можно определить с помощью четырех правил [212] , которые вытекают из понимания нейрона как электрического элемента. Информационная емкость охватывает функции, моделируемые сетью, если на входе имеются любые данные. Второе понятие — это размер венчурного капитала . VC Dimension использует принципы теории меры и находит максимальную мощность при наилучших возможных обстоятельствах. Это если ввести входные данные в определенном виде. Как отмечено в [210] , размерность VC для произвольных входных данных равна половине информационной емкости персептрона. Размер VC для произвольных точек иногда называют объемом памяти. [213]
Конвергенция
Модели могут не всегда сходиться к единому решению, во-первых, потому, что могут существовать локальные минимумы, в зависимости от функции стоимости и модели. Во-вторых, используемый метод оптимизации может не гарантировать сходимость, когда он начинается далеко от любого локального минимума. В-третьих, при достаточно больших данных или параметрах некоторые методы становятся непрактичными.
Еще одна проблема, о которой стоит упомянуть, заключается в том, что обучение может пересечь некоторую седловую точку , что может привести к сближению в неправильном направлении.
Поведение конвергенции определенных типов архитектур ИНС более понятно, чем других. Когда ширина сети приближается к бесконечности, ИНС хорошо описывается расширением Тейлора первого порядка на протяжении всего обучения и, таким образом, наследует поведение сходимости аффинных моделей . [214] [215] Другой пример: когда параметры малы, замечено, что ИНС часто соответствуют целевым функциям от низких до высоких частот. Такое поведение называется спектральным смещением или частотным принципом нейронных сетей. [216] [217] [218] [219] Это явление противоположно поведению некоторых хорошо изученных итерационных численных схем, таких как метод Якоби . Было замечено, что более глубокие нейронные сети более склонны к низкочастотным функциям. [220]
Обобщение и статистика
Приложения, целью которых является создание системы, которая хорошо обобщает невидимые примеры, сталкиваются с возможностью переобучения. Это возникает в запутанных или переопределенных системах, когда пропускная способность сети значительно превышает необходимые свободные параметры. Два подхода касаются перетренированности. Первый — использовать перекрестную проверку и подобные методы для проверки наличия переобучения и выбора гиперпараметров для минимизации ошибки обобщения.
Второй — использовать некоторую форму регуляризации . Эта концепция возникает в вероятностной (байесовской) структуре, где регуляризация может быть выполнена путем выбора большей априорной вероятности среди более простых моделей; но также и в статистической теории обучения, где целью является минимизация двух величин: «эмпирического риска» и «структурного риска», который примерно соответствует ошибке в обучающем наборе и прогнозируемой ошибке в невидимых данных из-за переобучения.
Доверительный анализ нейронной сети
Контролируемые нейронные сети, использующие функцию стоимости среднеквадратической ошибки (MSE), могут использовать формальные статистические методы для определения достоверности обученной модели. MSE в наборе проверки можно использовать в качестве оценки дисперсии. Это значение затем можно использовать для расчета доверительного интервала выходных данных сети, предполагая нормальное распределение . Проведенный таким образом доверительный анализ является статистически достоверным до тех пор, пока распределение выходных вероятностей остается прежним и сеть не изменяется.
Присвоив функцию активации softmax , обобщение логистической функции , на выходном слое нейронной сети (или компоненту softmax в сети, основанной на компонентах) для категориальных целевых переменных, выходные данные можно интерпретировать как апостериорные вероятности. Это полезно при классификации, поскольку дает меру достоверности классификаций.
Функция активации softmax:
Критика
Обучение
Распространенная критика нейронных сетей, особенно в робототехнике, заключается в том, что им требуется слишком много обучающих выборок для реальной работы. [221]
Любая обучающаяся машина нуждается в достаточно репрезентативных примерах, чтобы уловить основную структуру, которая позволяет ей обобщать новые случаи. Потенциальные решения включают случайное перетасовывание обучающих примеров с использованием алгоритма числовой оптимизации, который не делает слишком больших шагов при изменении сетевых подключений по примеру, группировку примеров в так называемые мини-пакеты и/или введение рекурсивного алгоритма наименьших квадратов для CMAC . . [150]
Дин Померло использует нейронную сеть для обучения роботизированного транспортного средства езде по разным типам дорог (однополосные, многополосные, грунтовые и т. д.), и большая часть его исследований посвящена экстраполяции множества сценариев обучения из единый опыт обучения и сохранение разнообразия прошлых тренировок, чтобы система не перетренировалась (если, например, ей предлагается серия поворотов направо, она не должна учиться всегда поворачивать направо). [222]
Теория
Основное утверждение [ нужна ссылка ] на ИНС заключается в том, что они воплощают в себе новые и мощные общие принципы обработки информации. Эти принципы нечетко определены. Часто утверждают [ кем? ] , что они возникают из самой сети. Это позволяет описать простую статистическую ассоциацию (основную функцию искусственных нейронных сетей) как обучение или распознавание. В 1997 году Александр Дьюдни , бывший обозреватель журнала Scientific American , заметил, что в результате искусственные нейронные сети приобретают «качество «что-то ради ничего», которое придает особую ауру лени и явное отсутствие любопытства по поводу того, насколько хороши эти сети». вычислительные системы есть. Никакая человеческая рука (или разум) не вмешивается; решения находятся как по волшебству; и никто, кажется, ничему не научился». [223] Одним из ответов Дьюдни является то, что нейронные сети успешно используются для решения многих сложных и разнообразных задач, начиная от автономного управления самолетом [224] и заканчивая обнаружением мошенничества с кредитными картами и освоением игры в го .
Нейронные сети, например, находятся на скамье подсудимых не только потому, что их разрекламировали до небес (а что нет?), но и потому, что вы можете создать успешную сеть, не понимая, как она работает: набор чисел, фиксирующих ее поведение, по всей вероятности, будет «непрозрачной, нечитаемой таблицей… бесполезной как научный ресурс».
Несмотря на свое решительное заявление о том, что наука — это не технология, Дьюдни, похоже, выставляет нейронные сети к позорному столбу как плохую науку, тогда как большинство из тех, кто их разрабатывает, просто пытаются быть хорошими инженерами. Нечитаемая таблица, которую может прочитать полезная машина, все равно стоит иметь. [225]
Хотя это правда, что анализировать то, что было изучено искусственной нейронной сетью, сложно, сделать это гораздо проще, чем анализировать то, что было изучено биологической нейронной сетью. Более того, недавний акцент на объяснимости ИИ способствовал развитию методов, особенно основанных на механизмах внимания , для визуализации и объяснения изученных нейронных сетей. Более того, исследователи, занимающиеся изучением алгоритмов обучения нейронных сетей, постепенно раскрывают общие принципы, которые позволяют обучающимся машинам быть успешными. Например, Бенджио и ЛеКун (2007) написали статью о локальном и нелокальном обучении, а также о поверхностной и глубокой архитектуре. [226]
Биологический мозг использует как поверхностные, так и глубокие цепи, как сообщает анатомия мозга [227] , демонстрируя широкий спектр инвариантности. Венг [228] утверждал, что мозг самостоятельно подключается в основном в соответствии со статистикой сигналов, и поэтому последовательный каскад не может уловить все основные статистические зависимости.
Аппаратное обеспечение
Большие и эффективные нейронные сети требуют значительных вычислительных ресурсов. [229] Хотя в мозгу есть аппаратное обеспечение, предназначенное для обработки сигналов через граф нейронов, моделирование даже упрощенного нейрона на архитектуре фон Неймана может потребовать огромных объемов памяти и хранилища. Более того, разработчику часто приходится передавать сигналы через многие из этих соединений и связанных с ними нейронов, что требует огромной мощности процессора и времени.
Шмидхубер отметил, что возрождение нейронных сетей в двадцать первом веке во многом связано с достижениями в области аппаратного обеспечения: с 1991 по 2015 год вычислительная мощность, особенно с помощью GPGPU (на графических процессорах ), увеличилась примерно в миллион раз, в результате чего стандартный алгоритм обратного распространения ошибки возможен для обучающих сетей, которые находятся на несколько уровней глубже, чем раньше. [29] Использование ускорителей, таких как FPGA и графические процессоры, может сократить время обучения с месяцев до дней. [229]
Нейроморфная инженерия или физическая нейронная сеть напрямую решают аппаратные трудности, создавая чипы, не относящиеся к фон Нейману, для непосредственной реализации нейронных сетей в схемах. Другой тип чипа, оптимизированный для обработки нейронных сетей, называется тензорным процессором или TPU. [230]
Практические контрпримеры
Анализировать то, что узнала ИНС, гораздо проще, чем анализировать то, что узнала биологическая нейронная сеть. Более того, исследователи, изучающие алгоритмы обучения нейронных сетей, постепенно раскрывают общие принципы, которые позволяют обучающимся машинам быть успешными. Например, локальное и нелокальное обучение и поверхностная и глубокая архитектура. [231]
Гибридные подходы
Сторонники гибридных моделей (объединяющих нейронные сети и символические подходы) говорят, что такая смесь может лучше отразить механизмы человеческого разума. [232] [233]
Смещение набора данных
Нейронные сети зависят от качества данных, на которых они обучаются, поэтому данные низкого качества с несбалансированной репрезентативностью могут привести к обучению модели и закреплению социальных предубеждений. [234] [235] Эти унаследованные предубеждения становятся особенно критичными, когда ИНС интегрируются в реальные сценарии, где обучающие данные могут быть несбалансированными из-за нехватки данных для конкретной расы, пола или другого признака. [234] Этот дисбаланс может привести к тому, что модель будет иметь неадекватное представление и понимание недостаточно представленных групп, что приведет к дискриминационным результатам, которые усугубят социальное неравенство, особенно в таких приложениях, как распознавание лиц , процессы найма и правоохранительная деятельность . [235] [236] Например, в 2018 году Amazon пришлось отказаться от инструмента подбора персонала, поскольку в этой модели предпочтение отдавалось мужчинам, а не женщинам на должностях в области разработки программного обеспечения из-за большего числа работников-мужчин в этой области. [236] Программа будет наказывать любое резюме со словом «женщина» или названием любого женского колледжа. Однако использование синтетических данных может помочь уменьшить предвзятость набора данных и повысить представленность в наборах данных. [237]
Галерея
Однослойная искусственная нейронная сеть прямого распространения. Стрелки, исходящие от, опущены для ясности. Эта сеть имеет p входов и q выходов. В этой системе значение q-го выхода рассчитывается как
Двухслойная искусственная нейронная сеть прямого распространения
Искусственная нейронная сеть
Граф зависимости ИНС
Однослойная искусственная нейронная сеть прямого распространения с 4 входами, 6 скрытыми узлами и 2 выходами. Учитывая состояние положения и направление, он выводит значения управления на основе колеса.
Двухслойная искусственная нейронная сеть прямого распространения с 8 входами, 2х8 скрытыми узлами и 2 выходами. Учитывая состояние положения, направление и другие значения окружающей среды, он выводит управляющие значения на основе подруливающего устройства.
Параллельная конвейерная структура нейронной сети CMAC. Этот алгоритм обучения может сходиться за один шаг.
Последние достижения и будущие направления
Искусственные нейронные сети (ИНС) являются ключевым элементом в области машинного обучения, напоминающим структуру и функции человеческого мозга. ИНС претерпели значительные улучшения, особенно в их способности моделировать сложные системы, обрабатывать большие наборы данных и адаптироваться к различным типам приложений. Их эволюция за последние несколько десятилетий была отмечена заметными методологическими разработками и широким спектром приложений в таких областях, как обработка изображений, распознавание речи, обработка естественного языка, финансы и медицина.
Обработка изображений
В области обработки изображений ИНС добились значительных успехов. Они используются в таких задачах, как классификация изображений, распознавание объектов и сегментация изображений. Например, глубокие сверточные нейронные сети (CNN) сыграли важную роль в распознавании рукописных цифр, обеспечив современную производительность. [238] Это демонстрирует способность ИНС эффективно обрабатывать и интерпретировать сложную визуальную информацию, что приводит к прогрессу в самых разных областях: от автоматического наблюдения до медицинской визуализации. [238]
Распознавание речи
ИНС произвели революцию в технологии распознавания речи. Моделируя речевые сигналы, они используются для таких задач, как идентификация говорящего и преобразование речи в текст. Архитектура глубоких нейронных сетей внесла значительные улучшения в распознавание непрерывной речи с большим словарным запасом, превосходя традиционные методы. [238] [239] Эти достижения способствовали разработке более точных и эффективных систем с голосовым управлением, улучшающих пользовательские интерфейсы в технологических продуктах.
Обработка естественного языка
При обработке естественного языка ИНС жизненно важны для таких задач, как классификация текста, анализ настроений и машинный перевод. Они позволили разработать модели, которые могут точно переводить между языками, понимать контекст и тональность текстовых данных, а также классифицировать текст на основе содержания. [238] [239] Это имеет глубокие последствия для автоматизированного обслуживания клиентов, модерации контента и технологий понимания языка.
Системы контроля
В области систем управления ИНС применяются для моделирования динамических систем для таких задач, как идентификация системы, проектирование управления и оптимизация. Например, алгоритм обратного распространения ошибки использовался для обучения многослойных нейронных сетей прямого распространения, которые играют важную роль в приложениях идентификации и управления системами. Это подчеркивает универсальность ИНС в адаптации к сложным динамическим средам, что имеет решающее значение в автоматизации и робототехнике.
Финансы
Искусственные нейронные сети (ИНС) оказали значительное влияние на финансовый сектор, особенно в области прогнозирования фондового рынка и кредитного скоринга. Эти мощные системы искусственного интеллекта могут обрабатывать огромные объемы финансовых данных, распознавать сложные закономерности и прогнозировать тенденции фондового рынка, помогая инвесторам и риск-менеджерам принимать обоснованные решения. [238] В кредитном скоринге ИНС предлагают основанную на данных персонализированную оценку кредитоспособности, повышая точность прогнозирования дефолта и автоматизируя процесс кредитования. [239] Хотя ИНС предлагают множество преимуществ, они также требуют высококачественных данных и тщательной настройки, а их природа «черного ящика» может создавать проблемы при интерпретации. Тем не менее, продолжающиеся достижения позволяют предположить, что ИНС будут продолжать играть ключевую роль в формировании будущего финансов, предлагая ценную информацию и совершенствуя стратегии управления рисками.
Лекарство
Искусственные нейронные сети (ИНС) произвели революцию в области медицины благодаря своей способности обрабатывать и анализировать огромные наборы медицинских данных. Они сыграли важную роль в повышении точности диагностики, особенно при интерпретации сложных медицинских изображений для раннего выявления заболеваний, а также в прогнозировании результатов лечения пациентов для индивидуального планирования лечения. [239] При открытии лекарств ИНС ускоряют идентификацию потенциальных кандидатов на лекарства и прогнозируют их эффективность и безопасность, что значительно сокращает время и затраты на разработку. [238] Кроме того, их применение в персонализированной медицине и анализе данных здравоохранения ведет к более индивидуальной терапии и эффективному управлению уходом за пациентами. [239] Несмотря на эти достижения, остаются такие проблемы, как конфиденциальность данных и интерпретируемость моделей, и продолжаются исследования, направленные на решение этих проблем и расширение сферы применения ИНС в медицине.
Создание контента
ИНС, такие как генеративно-состязательные сети ( GAN ) и преобразователи , также используются для создания контента во многих отраслях. [240] Это связано с тем, что модели глубокого обучения способны изучать стиль художника или музыканта на основе огромных наборов данных и создавать совершенно новые произведения искусства и музыкальные композиции. Например, DALL-E — это глубокая нейронная сеть, обученная на 650 миллионах пар изображений и текстов в Интернете, которая может создавать произведения искусства на основе текста, введенного пользователем. [241] В области музыки трансформеры используются для создания оригинальной музыки для рекламных роликов и документальных фильмов с помощью таких компаний, как AIVA и Jukedeck . [242] В маркетинговой индустрии генеративные модели используются для создания персонализированной рекламы для потребителей. [240] Кроме того, крупные кинокомпании сотрудничают с технологическими компаниями для анализа финансового успеха фильма, например, партнерство между Warner Bros и технологической компанией Cinelytic, основанной в 2020 году. [243] Кроме того, нейронные сети нашли применение в видеоиграх. создание, в котором неигровые персонажи (NPC) могут принимать решения на основе всех персонажей, находящихся в данный момент в игре. [244]
Этот аудиофайл был создан на основе редакции этой статьи от 27 ноября 2011 года и не отражает последующие изменения. (2011-11-27)
Краткое введение в нейронные сети (Д. Кризель) — иллюстрированная двуязычная рукопись об искусственных нейронных сетях; Темы на данный момент: перцептроны, обратное распространение ошибки, радиальные базисные функции, рекуррентные нейронные сети, самоорганизующиеся карты, сети Хопфилда.
Обзор нейронных сетей в материаловедении
Учебное пособие по искусственным нейронным сетям на трех языках (Мадридский политехнический университет)
Еще одно знакомство с ИНС
Новое поколение нейронных сетей – Google Tech Talks
Производительность нейронных сетей
Нейронные сети и информация
Сандерсон, Грант (5 октября 2017 г.). «Но что такое нейронная сеть?». 3Синий1Коричневый . Архивировано из оригинала 7 ноября 2021 года — на YouTube .
Примечания
↑ Для управления мероприятием « Без рук по всей Америке » 1995 года потребовалось «всего несколько человек».
Рекомендации
↑ Хардести, Ларри (14 апреля 2017 г.). «Пояснение: нейронные сети». Пресс-служба Массачусетского технологического института . Проверено 2 июня 2022 г.
^ Ян, ЗР; Ян, З. (2014). Комплексная биомедицинская физика. Каролинский институт, Стокгольм, Швеция: Elsevier. п. 1. ISBN978-0-444-53633-4. Архивировано из оригинала 28 июля 2022 года . Проверено 28 июля 2022 г.
↑ Бишоп, Кристофер М. (17 августа 2006 г.). Распознавание образов и машинное обучение . Нью-Йорк: Спрингер. ISBN978-0-387-31073-2.
^ аб Вапник, Владимир Н.; Вапник, Владимир Наумович (1998). Природа статистической теории обучения (Исправленное 2-е издание). Нью-Йорк Берлин Гейдельберг: Springer. ISBN978-0-387-94559-0.
^ ab Ян Гудфеллоу, Йошуа Бенджио и Аарон Курвиль (2016). Глубокое обучение. МТИ Пресс. Архивировано из оригинала 16 апреля 2016 года . Проверено 1 июня 2016 г.
^ Ферри, К.; Кайзер, С. (2019). Нейронные сети для детей . Справочники. ISBN978-1-4926-7120-6.
^ Мэнсфилд Мерриман, «Список работ, касающихся метода наименьших квадратов»
^ Стиглер, Стивен М. (1981). «Гаусс и изобретение метода наименьших квадратов». Анна. Стат . 9 (3): 465–474. дои : 10.1214/aos/1176345451 .
^ Бретшер, Отто (1995). Линейная алгебра с приложениями (3-е изд.). Река Аппер-Сэдл, Нью-Джерси: Прентис-Холл.
^ abcdefghijklmn Шмидхубер, Юрген (2022). «Аннотированная история современного искусственного интеллекта и глубокого обучения». arXiv : 2212.11279 [cs.NE].
^ Стиглер, Стивен М. (1986). История статистики: измерение неопределенности до 1900 года . Кембридж: Гарвард. ISBN0-674-40340-1.
^ аб Браш, Стивен Г. (1967). «История модели Ленца-Изинга». Обзоры современной физики . 39 (4): 883–893. Бибкод : 1967RvMP...39..883B. doi : 10.1103/RevModPhys.39.883.
^ Амари, Шун-Ичи (1972). «Обучение шаблонам и последовательностям шаблонов с помощью самоорганизующихся сетей пороговых элементов». IEEE-транзакции . С (21): 1197–1206.
^ Хопфилд, Джей-Джей (1982). «Нейронные сети и физические системы с возникающими коллективными вычислительными способностями». Труды Национальной академии наук . 79 (8): 2554–2558. Бибкод : 1982PNAS...79.2554H. дои : 10.1073/pnas.79.8.2554 . ПМЦ 346238 . ПМИД 6953413.
^ Клини, Южная Каролина (1956). «Представление событий в нервных сетях и конечных автоматах». Анналы математических исследований . № 34. Издательство Принстонского университета. стр. 3–41 . Проверено 17 июня 2017 г.
^ Хебб, Дональд (1949). Организация поведения. Нью-Йорк: Уайли. ISBN978-1-135-63190-1.
^ Фарли, Б.Г.; В.А. Кларк (1954). «Моделирование самоорганизующихся систем с помощью цифрового компьютера». IRE Транзакции по теории информации . 4 (4): 76–84. дои : 10.1109/TIT.1954.1057468.
^ Рочестер, Н.; Дж. Х. Холланд, Л. Х. Хабит и В. Л. Дуда (1956). «Испытания теории сборки клеток действия мозга с использованием большого цифрового компьютера». IRE Транзакции по теории информации . 2 (3): 80–93. дои : 10.1109/TIT.1956.1056810.
^ Хайкин (2008) Нейронные сети и обучающиеся машины, 3-е издание
^ Розенблатт, Ф. (1958). «Персептрон: вероятностная модель хранения и организации информации в мозге». Психологический обзор . 65 (6): 386–408. CiteSeerX 10.1.1.588.3775 . дои : 10.1037/h0042519. PMID 13602029. S2CID 12781225.
^ Вербос, П.Дж. (1975). За пределами регрессии: новые инструменты прогнозирования и анализа в поведенческих науках.
^ Олазаран, Микель (1996). «Социологическое исследование официальной истории спора о перцептронах». Социальные исследования науки . 26 (3): 611–659. дои : 10.1177/030631296026003005. JSTOR 285702. S2CID 16786738.
^ аб Рассел, Стюарт; Норвиг, Питер (2010). Искусственный интеллект: современный подход (PDF) (3-е изд.). Соединенные Штаты Америки: Pearson Education. стр. 16–28. ISBN978-0-13-604259-4.
^ Аб Рассел, Стюарт Дж.; Норвиг, Питер (2021). Искусственный интеллект: современный подход . Серия Пирсона по искусственному интеллекту. Минг-Вэй Чанг, Джейкоб Девлин, Анка Драган, Дэвид Форсайт, Ян Гудфеллоу, Джитендра Малик, Викаш Мансингка, Джудея Перл, Майкл Дж. Вулдридж (4-е изд.). Хобокен, Нью-Джерси: Пирсон. ISBN978-0-13-461099-3.
↑ Джакалья, врач общей практики (2 ноября 2022 г.). Заставить вещи думать. Холлоуэй. ISBN978-1-952120-41-1. Проверено 29 декабря 2023 г.
^ abc Шмидхубер, Дж. (2015). «Глубокое обучение в нейронных сетях: обзор». Нейронные сети . 61 : 85–117. arXiv : 1404.7828 . doi :10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509.
^ Фон дер Мальсбург, C (1973). «Самоорганизация ориентационно-чувствительных клеток в полосатой коре». Кибернетик . 14 (2): 85–100. дои : 10.1007/bf00288907. PMID 4786750. S2CID 3351573.
^ Фукусима, Кунихико (1980). «Неокогнитрон: самоорганизующаяся модель нейронной сети для механизма распознавания образов, на который не влияет сдвиг положения» (PDF) . Биологическая кибернетика . 36 (4): 193–202. дои : 10.1007/BF00344251. PMID 7370364. S2CID 206775608 . Проверено 16 ноября 2013 г.
^ Фукусима, К. (1969). «Визуальное извлечение признаков с помощью многослойной сети аналоговых пороговых элементов». Транзакции IEEE по системным наукам и кибернетике . 5 (4): 322–333. дои : 10.1109/TSSC.1969.300225.
^ Рамачандран, Праджит; Баррет, Зоф; Куок, В. Ле (16 октября 2017 г.). «Поиск функций активации». arXiv : 1710.05941 [cs.NE].
^ Лейбниц, Готфрид Вильгельм Фрайхерр фон (1920). Ранние математические рукописи Лейбница: перевод с латинских текстов, опубликованных Карлом Иммануэлем Герхардтом с критическими и историческими примечаниями (Лейбниц опубликовал цепное правило в мемуарах 1676 года). Издательство «Открытый суд». ISBN978-0-598-81846-1.
^ Линнаинмаа, Сеппо (1970). Представление совокупной ошибки округления алгоритма в виде разложения Тейлора локальных ошибок округления (Мастерс) (на финском языке). Университет Хельсинки. стр. 6–7.
^ Келли, Генри Дж. (1960). «Градиентная теория оптимальных траекторий полета». Журнал АРС . 30 (10): 947–954. дои : 10.2514/8.5282.
^ «Градиентный метод оптимизации многоэтапных процессов распределения» . Труды Гарвардского университета. Симпозиум по цифровым компьютерам и их приложениям . Апрель 1961 года.
^ Дрейфус, Стюарт Э. (1 сентября 1990 г.). «Искусственные нейронные сети, обратное распространение ошибки и процедура градиента Келли-Брайсона». Журнал руководства, контроля и динамики . 13 (5): 926–928. Бибкод : 1990JGCD...13..926D. дои : 10.2514/3.25422. ISSN 0731-5090.
^ Мизутани, Э.; Дрейфус, SE ; Нисио, К. (2000). «О выводе обратного распространения ошибки MLP из формулы градиента оптимального управления Келли-Брайсона и ее применении». Материалы Международной совместной конференции IEEE-INNS-ENNS по нейронным сетям. IJCNN 2000. Нейронные вычисления: новые вызовы и перспективы нового тысячелетия . IEEE. С. 167–172 т.2. дои : 10.1109/ijcnn.2000.857892. ISBN0-7695-0619-4. S2CID 351146.
^ Дрейфус, Стюарт (1973). «Вычислительное решение задач оптимального управления с запаздыванием». Транзакции IEEE при автоматическом управлении . 18 (4): 383–385. дои : 10.1109/tac.1973.1100330.
^ Вербос, Пол (1982). «Применение достижений нелинейного анализа чувствительности» (PDF) . Системное моделирование и оптимизация . Спрингер. стр. 762–770. Архивировано (PDF) из оригинала 14 апреля 2016 года . Проверено 2 июля 2017 г.
^ Дэвид Э. Румельхарт, Джеффри Э. Хинтон и Рональд Дж. Уильямс, «Изучение представлений с помощью ошибок обратного распространения. Архивировано 8 марта 2021 года в Wayback Machine », Nature , 323, страницы 533–536, 1986.
^ Барт, Питер Ф. (1981). Кооперативность и переходное поведение больших нейронных сетей (дипломная работа). Берлингтон: Университет Вермонта. ОСЛК 8231704.
^ Кризан, JE; Барт, ПФ ; Глассер, ML (1983). «Точные фазовые переходы для модели Изинга на замкнутом дереве Кэли». Физика . Издательство Северной Голландии 119А : 230–242. дои : 10.1016/0378-4371(83)90157-7.
^ Глассер, ML; Голдберг, М. (1983), «Модель Изинга на замкнутом дереве Кэли», Physica , 117A (2–3): 670–672, Бибкод : 1983PhyA..117..670G, doi : 10.1016/0378-4371( 83)90138-3
^ Вайбель, Алекс (декабрь 1987 г.). Распознавание фонем с использованием нейронных сетей с задержкой . Заседание Института инженеров по электротехнике, информатике и связи (IEICE). Токио, Япония.
^ Александр Вайбель и др., Распознавание фонем с использованием нейронных сетей с задержкой. Транзакции IEEE по акустике, речи и обработке сигналов, том 37, № 3, стр. 328. - 339, март 1989 г.
^ Чжан, Вэй (1988). «Нейронная сеть распознавания образов, инвариантная к сдвигу, и ее оптическая архитектура». Материалы ежегодной конференции Японского общества прикладной физики .
^ Чжан, Вэй (1990). «Модель параллельной распределенной обработки с локальными пространственно-инвариантными соединениями и ее оптическая архитектура». Прикладная оптика . 29 (32): 4790–7. Бибкод : 1990ApOpt..29.4790Z. дои : 10.1364/AO.29.004790. ПМИД 20577468.
^ ЛеКун и др. , «Обратное распространение ошибки, примененное к распознаванию рукописного почтового индекса», Neural Computation , 1, стр. 541–551, 1989.
^ Дж. Венг, Н. Ахуджа и Т. С. Хуанг, «Кресцептрон: самоорганизующаяся нейронная сеть, которая растет адаптивно. Архивировано 21 сентября 2017 г. в Wayback Machine », Proc. Международная совместная конференция по нейронным сетям , Балтимор, Мэриленд, том I, стр. 576–581, июнь 1992 г.
^ Дж. Венг, Н. Ахуджа и Т. С. Хуанг, «Обучение распознаванию и сегментации трехмерных объектов из двумерных изображений. Архивировано 21 сентября 2017 г. в Wayback Machine », Proc. 4-я Международная конференция. Computer Vision , Берлин, Германия, стр. 121–128, май 1993 г.
^ Дж. Венг, Н. Ахуджа и Т. С. Хуанг, «Обучение распознаванию и сегментации с использованием кресцептрона. Архивировано 25 января 2021 года в Wayback Machine », International Journal of Computer Vision , vol. 25, нет. 2, стр. 105–139, ноябрь 1997 г.
^ ЛеКун, Янн; Леон Ботту; Йошуа Бенджио; Патрик Хаффнер (1998). «Градиентное обучение, применяемое для распознавания документов» (PDF) . Труды IEEE . 86 (11): 2278–2324. CiteSeerX 10.1.1.32.9552 . дои : 10.1109/5.726791. S2CID 14542261 . Проверено 7 октября 2016 г.
^ Цянь, Нин и Терренс Дж. Сейновски. «Предсказание вторичной структуры глобулярных белков с использованием моделей нейронных сетей». Журнал молекулярной биологии 202, вып. 4 (1988): 865-884.
^ Бор, Хенрик, Якоб Бор, Сёрен Брунак, Родни М. Дж. Коттерилл, Бенни Лаутруп, Лейф Норсков, Оле Х. Олсен и Штеффен Б. Петерсен. «Вторичная структура белка и гомология нейронных сетей. α-спирали в родопсине». Письма ФЭБС 241, (1988): 223-228.
^ Рост, Буркхард и Крис Сандер. «Предсказание вторичной структуры белка с точностью более 70%». Журнал молекулярной биологии 232, вып. 2 (1993): 584-599.
^ аб Шмидхубер, Юрген (1992). «Изучение сложных, расширенных последовательностей с использованием принципа сжатия истории» (PDF) . Нейронные вычисления . 4 (2): 234–242. дои : 10.1162/neco.1992.4.2.234. S2CID 18271205.
^ Шмидхубер, Юрген (1993). Кандидатская диссертация (PDF) .
^ Шмидхубер, Юрген (1993). «Уменьшение соотношения между сложностью обучения и количеством изменяющихся во времени переменных в полностью рекуррентных сетях». ИКАНН, 1993 год . Спрингер. стр. 460–463.
^ Васвани, Ашиш; Шазир, Ноам; Пармар, Ники; Ушкорейт, Якоб; Джонс, Лион; Гомес, Эйдан Н.; Кайзер, Лукаш; Полосухин Илья (12 июня 2017 г.). «Внимание — это все, что вам нужно». arXiv : 1706.03762 [cs.CL].
^ Вольф, Томас; Дебют, Лисандра; Сан, Виктор; Шомон, Жюльен; Деланг, Клеман; Мой, Энтони; Систак, Пьеррик; Раулт, Тим; Луф, Реми; Фунтович, Морган; Дэвисон, Джо; Шлейфер, Сэм; фон Платен, Патрик; Ма, Клара; Джернит, Ясин; Плю, Жюльен; Сюй, Канвен; Ле Скао, Тевен; Гуггер, Сильвен; Драма, Мариама; Лоест, Квентин; Раш, Александр (2020). «Трансформеры: современная обработка естественного языка». Материалы конференции 2020 года по эмпирическим методам обработки естественного языка: системные демонстрации . стр. 38–45. doi : 10.18653/v1/2020.emnlp-demos.6. S2CID 208117506.
↑ Хэ, Ченг (31 декабря 2021 г.). «Трансформатор в резюме». Трансформатор в ЦВ . На пути к науке о данных.
^ Шмидхубер, Юрген (1991). «Возможность реализовать любопытство и скуку в нейронных контроллерах для построения моделей». Учеб. САБ'1991 . MIT Press/Брэдфорд Букс. стр. 222–227.
^ Шмидхубер, Юрген (2010). «Формальная теория творчества, веселья и внутренней мотивации (1990–2010)». Транзакции IEEE по автономному умственному развитию . 2 (3): 230–247. дои : 10.1109/TAMD.2010.2056368. S2CID 234198.
^ Шмидхубер, Юрген (2020). «Генераторно-состязательные сети представляют собой особые случаи искусственного любопытства (1990), а также тесно связаны с минимизацией предсказуемости (1991)». Нейронные сети . 127 : 58–66. arXiv : 1906.04493 . doi :10.1016/j.neunet.2020.04.008. PMID 32334341. S2CID 216056336.
^ аб Гудфеллоу, Ян; Пуже-Абади, Жан; Мирза, Мехди; Сюй, Бин; Вард-Фарли, Дэвид; Озаир, Шерджил; Курвиль, Аарон; Бенджио, Йошуа (2014). Генеративно-состязательные сети (PDF) . Материалы Международной конференции по нейронным системам обработки информации (NIPS 2014). стр. 2672–2680. Архивировано (PDF) из оригинала 22 ноября 2019 г. Проверено 20 августа 2019 г.
^ «Готовьтесь, не паникуйте: синтетические медиа и дипфейки» . свидетель.орг. Архивировано из оригинала 2 декабря 2020 года . Проверено 25 ноября 2020 г.
^ «GAN 2.0: Гиперреалистичный генератор лиц NVIDIA» . SyncedReview.com . 14 декабря 2018 года . Проверено 3 октября 2019 г.
^ Каррас, Теро; Айла, Тимо; Лайне, Самули; Лехтинен, Яакко (1 октября 2017 г.). «Прогрессивное развитие GAN для повышения качества, стабильности и разнообразия». arXiv : 1710.10196 [cs.NE].
^ аб С. Хохрайтер., «Untersuruchungen zu dynamischen Neuronalen Netzen. Архивировано 6 марта 2015 г. в Wayback Machine », Дипломная работа. Институт ф. Информатика, Технический университет. Мюнхен. Советник: Дж. Шмидхубер , 1991 г.
^ Хохрейтер, С.; и другие. (15 января 2001 г.). «Градиентный поток в рекуррентных сетях: сложность изучения долгосрочных зависимостей». В Колене, Джон Ф.; Кремер, Стефан К. (ред.). Полевое руководство по динамическим рекуррентным сетям . Джон Уайли и сыновья. ISBN978-0-7803-5369-5.
^ Шривастава, Рупеш Кумар; Грефф, Клаус; Шмидхубер, Юрген (2 мая 2015 г.). «Дорожные сети». arXiv : 1505.00387 [cs.LG].
^ Шривастава, Рупеш К; Грефф, Клаус; Шмидхубер, Юрген (2015). «Обучение очень глубоких сетей». Достижения в области нейронных систем обработки информации . Curran Associates, Inc. 28 : 2377–2385.
^ Он, Кайминг; Чжан, Сянъюй; Рен, Шаоцин; Сунь, Цзянь (2016). Глубокое остаточное обучение для распознавания изображений. Конференция IEEE 2016 по компьютерному зрению и распознаванию образов (CVPR) . Лас-Вегас, Невада, США: IEEE. стр. 770–778. arXiv : 1512.03385 . дои :10.1109/CVPR.2016.90. ISBN978-1-4673-8851-1.
^ Мид, Карвер А .; Исмаил, Мохаммед (8 мая 1989 г.). Аналоговая реализация нейронных систем СБИС (PDF) . Международная серия Kluwer по инженерным наукам и информатике. Том. 80. Норвелл, Массачусетс: Kluwer Academic Publishers . дои : 10.1007/978-1-4613-1639-8. ISBN978-1-4613-1639-8. Архивировано (PDF) из оригинала 6 ноября 2019 года . Проверено 24 января 2020 г.
^ Смоленский, П. (1986). «Обработка информации в динамических системах: основы теории гармонии». В DE Румельхарте; Дж. Л. Макклелланд; Исследовательская группа НДП (ред.). Параллельная распределенная обработка: исследования микроструктуры познания. Том. 1. стр. 194–281. ISBN978-0-262-68053-0.
^ Нг, Эндрю; Дин, Джефф (2012). «Создание функций высокого уровня с использованием крупномасштабного обучения без учителя». arXiv : 1112.6209 [cs.LG].
^ Хинтон, GE ; Осиндеро, С.; Тех, Ю. (2006). «Алгоритм быстрого обучения для сетей глубокого доверия» (PDF) . Нейронные вычисления . 18 (7): 1527–1554. CiteSeerX 10.1.1.76.1541 . дои : 10.1162/neco.2006.18.7.1527. PMID 16764513. S2CID 2309950.
^ Фукусима, К. (1980). «Неокогнитрон: самоорганизующаяся модель нейронной сети для механизма распознавания образов, на который не влияет сдвиг положения». Биологическая кибернетика . 36 (4): 93–202. дои : 10.1007/BF00344251. PMID 7370364. S2CID 206775608.
^ Ризенхубер, М.; Поджо, Т. (1999). «Иерархические модели распознавания объектов в коре». Природная неврология . 2 (11): 1019–1025. дои : 10.1038/14819. PMID 10526343. S2CID 8920227.
^ Ян, Джей-Джей; и другие. (2008). «Мемристивный механизм переключения для наноустройств металл/оксид/металл». Нат. Нанотехнологии. 3 (7): 429–433. дои : 10.1038/nnano.2008.160. ПМИД 18654568.
^ Чирешан, Дэн Клаудиу; Мейер, Ули; Гамбарделла, Лука Мария; Шмидхубер, Юрген (21 сентября 2010 г.). «Глубокие, большие и простые нейронные сети для распознавания рукописных цифр». Нейронные вычисления . 22 (12): 3207–3220. arXiv : 1003.0358 . дои : 10.1162/neco_a_00052. ISSN 0899-7667. PMID 20858131. S2CID 1918673.
^ Доминик Шерер, Андреас К. Мюллер и Свен Бенке: «Оценка операций объединения в сверточных архитектурах для распознавания объектов. Архивировано 3 апреля 2018 г. в Wayback Machine », на 20-й Международной конференции по искусственным нейронным сетям (ICANN) , стр. 92–101. , 2010. doi : 10.1007/978-3-642-15825-4_10.
^ Интервью Kurzweil AI, 2012 г. Архивировано 31 августа 2018 г. в Wayback Machine с Юргеном Шмидхубером о восьми соревнованиях, выигранных его командой глубокого обучения в 2009–2012 гг.
^ «Как глубокое обучение на основе биологии продолжает побеждать в соревнованиях | KurzweilAI» . www.kurzweilai.net . Архивировано из оригинала 31 августа 2018 года . Проверено 16 июня 2017 г.
^ AB Грейвс, Алекс; Шмидхубер, Юрген (2009). «Офлайн-распознавание рукописного текста с помощью многомерных рекуррентных нейронных сетей» (PDF) . В Коллере, Д.; Шурманс, Дейл; Бенджио, Йошуа; Ботту, Л. (ред.). Достижения в области нейронных систем обработки информации 21 (NIPS 2008). Фонд систем нейронной обработки информации (NIPS). стр. 545–552. ISBN978-1-60560-949-2.
^ ab Грейвс, А.; Ливицкий, М.; Фернандес, С.; Бертолами, Р.; Бунке, Х.; Шмидхубер, Дж. (май 2009 г.). «Новая коннекционистская система для неограниченного распознавания рукописного текста» (PDF) . Транзакции IEEE по анализу шаблонов и машинному интеллекту . 31 (5): 855–868. CiteSeerX 10.1.1.139.4502 . дои :10.1109/tpami.2008.137. ISSN 0162-8828. PMID 19299860. S2CID 14635907. Архивировано (PDF) из оригинала 2 января 2014 года . Проверено 30 июля 2014 г.
^ Чиресан, Дэн; Мейер, У.; Шмидхубер, Дж. (июнь 2012 г.). «Многостолбцовые глубокие нейронные сети для классификации изображений». Конференция IEEE 2012 по компьютерному зрению и распознаванию образов . стр. 3642–3649. arXiv : 1202.2745 . Бибкод : 2012arXiv1202.2745C. CiteSeerX 10.1.1.300.3283 . дои : 10.1109/cvpr.2012.6248110. ISBN978-1-4673-1228-8. S2CID 2161592.
^ аб Биллингс, SA (2013). Идентификация нелинейных систем: методы NARMAX во временной, частотной и пространственно-временной областях . Уайли. ISBN978-1-119-94359-4.
^ [Рамезанпур, А.; Бим, Алабама; Чен, Дж. Х.; Машаги, А. Статистическая физика для медицинской диагностики: алгоритмы обучения, вывода и оптимизации. Диагностика 2020, 10, 972. ]
^ Аббод, Майсам Ф. (2007). «Применение искусственного интеллекта для лечения урологического рака». Журнал урологии . 178 (4): 1150–1156. дои :10.1016/j.juro.2007.05.122. ПМИД 17698099.
^ Доусон, Кристиан В. (1998). «Подход на основе искусственных нейронных сетей к моделированию дождевого стока». Журнал гидрологических наук . 43 (1): 47–66. Бибкод : 1998HydSJ..43...47D. дои : 10.1080/02626669809492102 .
^ "Словарь машинного обучения" . www.cse.unsw.edu.au. _ Архивировано из оригинала 26 августа 2018 года . Проверено 4 ноября 2009 г.
^ Чиресан, Дэн; Ули Мейер; Джонатан Маски; Лука М. Гамбарделла; Юрген Шмидхубер (2011). «Гибкие, высокопроизводительные сверточные нейронные сети для классификации изображений» (PDF) . Материалы двадцать второй Международной совместной конференции по искусственному интеллекту, том второй . 2 : 1237–1242. Архивировано (PDF) из оригинала 5 апреля 2022 года . Проверено 7 июля 2022 г.
^ Милянович, Милош (февраль – март 2012 г.). «Сравнительный анализ нейронных сетей с рекуррентным и конечным импульсным откликом в прогнозировании временных рядов» (PDF) . Индийский журнал компьютеров и техники . 3 (1).
↑ Лау, Суки (10 июля 2017 г.). «Обзор сверточной нейронной сети – настройка гиперпараметров». Середина . Архивировано из оригинала 4 февраля 2023 года . Проверено 23 августа 2019 г.
^ Келлехер, Джон Д.; Мак Нэми, Брайан; Д'Арси, Аойф (2020). «7-8». Основы машинного обучения для прогнозного анализа данных: алгоритмы, рабочие примеры и тематические исследования (2-е изд.). Кембридж, Массачусетс: MIT Press. ISBN978-0-262-36110-1. ОСЛК 1162184998.
↑ Вэй, Цзякай (26 апреля 2019 г.). «Забудьте о скорости обучения и потерях на распад». arXiv : 1905.00094 [cs.LG].
^ Ли, Ю.; Фу, Ю.; Ли, Х.; Чжан, Юго-Запад (1 июня 2009 г.). «Улучшенный алгоритм обучения нейронной сети обратного распространения ошибки с самоадаптирующейся скоростью обучения». Международная конференция 2009 г. по вычислительному интеллекту и естественным вычислениям . Том. 1. С. 73–76. дои : 10.1109/CINC.2009.111. ISBN978-0-7695-3645-3. S2CID 10557754.
^ Хуан, Гуан-Бин; Чжу, Цинь-Юй; Сью, Чи-Хеонг (2006). «Машина экстремального обучения: теория и приложения». Нейрокомпьютинг . 70 (1): 489–501. CiteSeerX 10.1.1.217.3692 . doi : 10.1016/j.neucom.2005.12.126. S2CID 116858.
^ Уидроу, Бернард; и другие. (2013). «Алгоритм без поддержки: новый алгоритм обучения для многослойных нейронных сетей». Нейронные сети . 37 : 182–188. doi :10.1016/j.neunet.2012.09.020. ПМИД 23140797.
^ Хинтон, GE (2010). «Практическое руководство по обучению ограниченных машин Больцмана». Тех. Реп. УТМЛ ТР 2010-003 . Архивировано из оригинала 9 мая 2021 года . Проверено 27 июня 2017 г.
^ Доминик, С.; Дас, Р.; Уитли, Д.; Андерсон, К. (июль 1991 г.). «Генетическое обучение с подкреплением для нейронных сетей» . IJCNN-91-Сиэтлская международная совместная конференция по нейронным сетям . IJCNN-91-Сиэтлская международная совместная конференция по нейронным сетям. Сиэтл, Вашингтон, США: IEEE. стр. 71–76. doi : 10.1109/IJCNN.1991.155315. ISBN0-7803-0164-1.
^ Хоскинс, Дж. К.; Химмельблау, DM (1992). «Управление процессами с помощью искусственных нейронных сетей и обучение с подкреплением». Компьютеры и химическая инженерия . 16 (4): 241–251. дои : 10.1016/0098-1354(92)80045-Б.
^ Берцекас, ДП; Цициклис, Ю.Н. (1996). Нейродинамическое программирование. Афина Сайентифик. п. 512. ИСБН978-1-886529-10-6. Архивировано из оригинала 29 июня 2017 года . Проверено 17 июня 2017 г.
^ Секоманди, Никола (2000). «Сравнение алгоритмов нейродинамического программирования для задачи выбора маршрута транспортных средств со стохастическими требованиями». Компьютеры и исследования операций . 27 (11–12): 1201–1225. CiteSeerX 10.1.1.392.4034 . дои : 10.1016/S0305-0548(99)00146-X.
^ де Риго, Д.; Риццоли, А.Е.; Сончини-Сесса, Р.; Вебер, Э.; Зенеси, П. (2001). «Нейродинамическое программирование для эффективного управления сетями резервуаров». Материалы MODSIM 2001, Международного конгресса по моделированию и симуляции . MODSIM 2001, Международный конгресс по моделированию и симуляции. Канберра, Австралия: Общество моделирования и моделирования Австралии и Новой Зеландии. дои : 10.5281/zenodo.7481. ISBN0-86740-525-2. Архивировано из оригинала 7 августа 2013 года . Проверено 29 июля 2013 г.
^ Дамас, М.; Салмерон, М.; Диас, А.; Ортега, Дж.; Прието, А.; Оливарес, Г. (2000). «Генетические алгоритмы и нейродинамическое программирование: применение в сетях водоснабжения». Труды Конгресса 2000 года по эволюционным вычислениям . Конгресс 2000 г. по эволюционным вычислениям. Том. 1. Ла-Хойя, Калифорния, США: IEEE. стр. 7–14. дои : 10.1109/CEC.2000.870269. ISBN0-7803-6375-2.
^ Дэн, Гэн; Феррис, MC (2008). «Нейродинамическое программирование для планирования фракционированной лучевой терапии». Оптимизация в медицине . Оптимизация Springer и ее приложения. Том. 12. С. 47–70. CiteSeerX 10.1.1.137.8288 . дои : 10.1007/978-0-387-73299-2_3. ISBN978-0-387-73298-5.
^ Бозиновский, С. (1982). «Самообучающаяся система с использованием вторичного подкрепления». В Р. Траппле (ред.) Кибернетика и системные исследования: материалы шестого европейского совещания по кибернетике и системным исследованиям. Северная Голландия. стр. 397–402. ISBN 978-0-444-86488-8 .
^ Бозиновский, С. (2014) «Моделирование механизмов когнитивно-эмоционального взаимодействия в искусственных нейронных сетях, с 1981 г. Архивировано 23 марта 2019 г. в Wayback Machine ». Procedia Информатика с. 255-263
^ Божиновский, Стево; Божиновска, Лиляна (2001). «Самообучающиеся агенты: коннекционистская теория эмоций, основанная на перекрестных оценочных суждениях». Кибернетика и системы . 32 (6): 637–667. дои : 10.1080/01969720118145. S2CID 8944741.
^ «Искусственный интеллект может« развиваться »для решения проблем» . Наука | АААС . 10 января 2018 года. Архивировано из оригинала 9 декабря 2021 года . Проверено 7 февраля 2018 г.
^ Турчетти, Клаудио (2004), Стохастические модели нейронных сетей , Границы искусственного интеллекта и приложений: интеллектуальные инженерные системы, основанные на знаниях, том. 102, IOS Press, ISBN978-1-58603-388-0
^ Жоспен, Лоран Валентин; Лага, Хамид; Буссаид, Фарид; Бунтин, Рэй; Беннамун, Мохаммед (2022). «Практические байесовские нейронные сети — руководство для пользователей глубокого обучения». Журнал IEEE Computational Intelligence . Том. 17, нет. 2. С. 29–48. arXiv : 2007.06823 . дои : 10.1109/mci.2022.3155327. ISSN 1556-603X. S2CID 220514248.
^ де Риго, Д.; Кастеллетти, А.; Риццоли, А.Е.; Сончини-Сесса, Р.; Вебер, Э. (январь 2005 г.). «Техника выборочного улучшения для усиления нейродинамического программирования в управлении сетями водных ресурсов». У Павла Зитека (ред.). Материалы 16-го Всемирного конгресса IFAC – IFAC-PapersOnLine . 16-й Всемирный конгресс МФБ. Том. 16. Прага, Чехия: МФБ. стр. 7–12. doi : 10.3182/20050703-6-CZ-1902.02172. hdl : 11311/255236 . ISBN978-3-902661-75-3. Архивировано из оригинала 26 апреля 2012 года . Проверено 30 декабря 2011 г.
^ Феррейра, К. (2006). «Проектирование нейронных сетей с использованием программирования экспрессии генов». У А. Авраама; Б. де Баэтс; М. Кеппен; Б. Николай (ред.). Прикладные технологии мягких вычислений: проблема сложности (PDF) . Спрингер-Верлаг. стр. 517–536. Архивировано (PDF) из оригинала 19 декабря 2013 года . Проверено 8 октября 2012 года .
^ Да, Ю.; Сюрун, Г. (июль 2005 г.). «Улучшенная ИНС на основе PSO с методом моделирования отжига». В Т. Вильманне (ред.). Новые аспекты нейрокомпьютинга: 11-й Европейский симпозиум по искусственным нейронным сетям . Том. 63. Эльзевир. стр. 527–533. doi : 10.1016/j.neucom.2004.07.002. Архивировано из оригинала 25 апреля 2012 года . Проверено 30 декабря 2011 г.
^ Ву, Дж.; Чен, Э. (май 2009 г.). «Новый ансамбль непараметрической регрессии для прогнозирования осадков с использованием метода оптимизации роя частиц в сочетании с искусственной нейронной сетью». Ин Ван, Х.; Шен, Ю.; Хуанг, Т.; Цзэн, З. (ред.). 6-й международный симпозиум по нейронным сетям, ISNN 2009 . Конспекты лекций по информатике. Том. 5553. Спрингер. стр. 49–58. дои : 10.1007/978-3-642-01513-7_6. ISBN978-3-642-01215-0. Архивировано из оригинала 31 декабря 2014 года . Проверено 1 января 2012 г.
^ Аб Тин Цинь; Цзунхай Чен; Хайтао Чжан; Сифу Ли; Вэй Сян; Мин Ли (2004). «Алгоритм обучения CMAC на основе RLS» (PDF) . Нейронная обработка писем . 19 (1): 49–61. doi :10.1023/B:NEPL.0000016847.18175.60. S2CID 6233899. Архивировано (PDF) из оригинала 14 апреля 2021 года . Проверено 30 января 2019 г.
^ Тин Цинь; Хайтао Чжан; Цзунхай Чен; Вэй Сян (2005). «Непрерывный CMAC-QRLS и его систолический массив» (PDF) . Нейронная обработка писем . 22 (1): 1–16. дои : 10.1007/s11063-004-2694-0. S2CID 16095286. Архивировано (PDF) из оригинала 18 ноября 2018 г. . Проверено 30 января 2019 г.
^ Сак, Хасим; Старший, Эндрю; Бофе, Франсуаза (2014). «Архитектуры рекуррентных нейронных сетей с долгосрочной кратковременной памятью для крупномасштабного акустического моделирования» (PDF) . Архивировано из оригинала (PDF) 24 апреля 2018 года.
^ Ли, Сянган; У, Сихун (15 октября 2014 г.). «Построение глубоких рекуррентных нейронных сетей на основе долговременной памяти для распознавания речи с большим словарным запасом». arXiv : 1410.4281 [cs.CL].
^ Фан, Ю.; Цянь, Ю.; Се, Ф.; Сунг, ФК (2014). «Синтез TTS с помощью двунаправленных рекуррентных нейронных сетей на основе LSTM». Материалы ежегодной конференции Международной ассоциации речевой коммуникации Interspeech : 1964–1968 . Проверено 13 июня 2017 г.
^ Дзен, Хейга; Сак, Хасим (2015). «Однонаправленная рекуррентная нейронная сеть с долговременной краткосрочной памятью и рекуррентным выходным слоем для синтеза речи с малой задержкой» (PDF) . Google.com . ИКАССП. стр. 4470–4474. Архивировано (PDF) из оригинала 9 мая 2021 года . Проверено 27 июня 2017 г.
^ Фан, Бо; Ван, Лицзюань; Сунг, Фрэнк К.; Се, Лэй (2015). «Фотореалистичная говорящая голова с глубоким двунаправленным LSTM» (PDF) . Труды ICASSP . Архивировано (PDF) из оригинала 1 ноября 2017 г. Проверено 27 июня 2017 г.
^ Сильвер, Дэвид ; Юбер, Томас; Шритвизер, Джулиан; Антоноглу, Иоаннис; Лай, Мэтью; Гез, Артур; Ланкто, Марк; Сифре, Лоран; Кумаран, Дхаршан ; Грепель, Торе; Лилликрап, Тимоти; Симонян, Карен; Хассабис, Демис (5 декабря 2017 г.). «Освоение шахмат и сёги путем самостоятельной игры с помощью общего алгоритма обучения с подкреплением». arXiv : 1712.01815 [cs.AI].
^ Пробст, Филипп; Булестей, Анн-Лор; Бишль, Бернд (26 февраля 2018 г.). «Настраиваемость: важность гиперпараметров алгоритмов машинного обучения». Дж. Мах. Учиться. Рез . 20 : 53:1–53:32. S2CID 88515435.
^ Зоф, Баррет; Ле, Куок В. (4 ноября 2016 г.). «Поиск нейронной архитектуры с обучением с подкреплением». arXiv : 1611.01578 [cs.LG].
^ Хайфэн Цзинь; Цинцюань Сун; Ся Ху (2019). «Auto-keras: эффективная система поиска нейронной архитектуры». Материалы 25-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных . АКМ. arXiv : 1806.10282 . Архивировано из оригинала 21 августа 2019 года . Проверено 21 августа 2019 г. - через autokeras.com.
^ Класен, Марк; Де Мур, Барт (2015). «Поиск гиперпараметров в машинном обучении». arXiv : 1502.02127 [cs.LG].Бибкод : 2015arXiv150202127C
^ Сарстедт, Марко; Му, Эрик (2019). "Регрессивный анализ". Краткое руководство по исследованию рынка . Тексты Спрингера по бизнесу и экономике. Шпрингер Берлин Гейдельберг. стр. 209–256. дои : 10.1007/978-3-662-56707-4_7. ISBN978-3-662-56706-7. S2CID 240396965.
^ Тиан, Цзе; Тан, Инь; Солнце, Чаоли; Цзэн, Цзяньчао; Джин, Яочу (декабрь 2016 г.). «Самоадаптивная аппроксимация пригодности на основе сходства для эволюционной оптимизации». Серия симпозиумов IEEE 2016 по вычислительному интеллекту (SSCI) . стр. 1–8. дои : 10.1109/SSCI.2016.7850209. ISBN978-1-5090-4240-1. S2CID 14948018.
^ Алалул, Весам Салах; Куреши, Абдул Ханнан (2019). «Обработка данных с использованием искусственных нейронных сетей». Динамическая ассимиляция данных – преодоление неопределенностей . doi : 10.5772/intechopen.91935. ISBN978-1-83968-083-0. S2CID 219735060.
^ Пал, Мадхаб; Рой, Раджиб; Басу, Джоянта; Бепари, Милтон С. (2013). «Слепое разделение источников: обзор и анализ». Международная конференция Oriental COCOSDA 2013 года проводится совместно с Конференцией 2013 года по исследованию и оценке разговорного языка в Азии (O-COCOSDA/CASLRE) . IEEE. стр. 1–5. doi : 10.1109/ICSDA.2013.6709849. ISBN978-1-4799-2378-6. S2CID 37566823.
^ Зиссис, Димитриос (октябрь 2015 г.). «Облачная архитектура, способная воспринимать и прогнозировать поведение нескольких судов». Прикладные мягкие вычисления . 35 : 652–661. doi :10.1016/j.asoc.2015.07.002. Архивировано из оригинала 26 июля 2020 года . Проверено 18 июля 2019 г.
^ Сенгупта, Нандини; Сахидулла, Мэриленд; Саха, Гутам (август 2016 г.). «Классификация звуков легких с использованием кепстральных статистических характеристик». Компьютеры в биологии и медицине . 75 (1): 118–129. doi : 10.1016/j.compbiomed.2016.05.013. ПМИД 27286184.
^ Чой, Кристофер Б. и др. «3d-r2n2: унифицированный подход к реконструкции трехмерных объектов с одним и несколькими изображениями. Архивировано 26 июля 2020 года в Wayback Machine ». Европейская конференция по компьютерному зрению. Спрингер, Чам, 2016 г.
^ Турек, Фред Д. (март 2007 г.). «Введение в нейросетевое машинное зрение». Проектирование систем технического зрения . 12 (3). Архивировано из оригинала 16 мая 2013 года . Проверено 5 марта 2013 г.
^ Майтра, Д.С.; Бхаттачарья, У.; Паруи, СК (август 2015 г.). «Общий подход на основе CNN к распознаванию рукописных символов в нескольких сценариях». 2015 13-я Международная конференция по анализу и распознаванию документов (ICDAR) . стр. 1021–1025. дои : 10.1109/ICDAR.2015.7333916. ISBN978-1-4799-1805-8. S2CID 25739012.
^ Гесслер, Йозеф (август 2021 г.). «Датчик для анализа пищевых продуктов с применением импедансной спектроскопии и искусственных нейронных сетей». РиуНет УПВ (1): 8–12. Архивировано из оригинала 21 октября 2021 года . Проверено 21 октября 2021 г.
^ Френч, Иордания (2016). «CAPM путешественника во времени». Журнал инвестиционных аналитиков . 46 (2): 81–96. дои : 10.1080/10293523.2016.1255469. S2CID 157962452.
^ Роман М. Балабин; Екатерина Ивановна Ломакина (2009). «Нейросетевой подход к данным квантовой химии: точное предсказание энергий теории функционала плотности». Дж. Хим. Физ. 131 (7): 074104. Бибкод : 2009JChPh.131g4104B. дои : 10.1063/1.3206326. ПМИД 19708729.
^ Сильвер, Дэвид; и другие. (2016). «Освоение игры в го с помощью глубоких нейронных сетей и поиска по дереву» (PDF) . Природа . 529 (7587): 484–489. Бибкод : 2016Natur.529..484S. дои : 10.1038/nature16961. PMID 26819042. S2CID 515925. Архивировано (PDF) из оригинала 23 ноября 2018 г. . Проверено 31 января 2019 г.
↑ Пасик, Адам (27 марта 2023 г.). «Глоссарий искусственного интеллекта: объяснение нейронных сетей и других терминов». Нью-Йорк Таймс . ISSN 0362-4331 . Проверено 22 апреля 2023 г.
↑ Шехнер, Сэм (15 июня 2017 г.). «Facebook усиливает искусственный интеллект для блокировки террористической пропаганды». Журнал "Уолл Стрит . ISSN 0099-9660 . Проверено 16 июня 2017 г.
^ Ганесан, Н. (2010). «Применение нейронных сетей в диагностике раковых заболеваний с использованием демографических данных». Международный журнал компьютерных приложений . 1 (26): 81–97. Бибкод : 2010IJCA....1z..81G. дои : 10.5120/476-783 .
^ Боттачи, Леонардо (1997). «Искусственные нейронные сети, применяемые для прогнозирования результатов лечения пациентов с колоректальным раком в отдельных учреждениях» (PDF) . Ланцет . «Ланцет». 350 (9076): 469–72. дои : 10.1016/S0140-6736(96)11196-X. PMID 9274582. S2CID 18182063. Архивировано из оригинала (PDF) 23 ноября 2018 года . Проверено 2 мая 2012 г.
^ Ализаде, Элахе; Лайонс, Саманта М; Касл, Джордан М; Прасад, Ашок (2016). «Измерение систематических изменений формы инвазивных раковых клеток с использованием моментов Цернике». Интегративная биология . 8 (11): 1183–1193. дои : 10.1039/C6IB00100A. ПМИД 27735002.
^ Лайонс, Саманта (2016). «Изменения формы клеток коррелируют с метастатическим потенциалом у мышей». Биология Открытая . 5 (3): 289–299. дои : 10.1242/bio.013409. ПМЦ 4810736 . ПМИД 26873952.
^ Набиан, Мохаммад Амин; Мейдани, Хади (28 августа 2017 г.). «Глубокое обучение для ускоренного анализа надежности инфраструктурных сетей». Компьютерное гражданское и инфраструктурное проектирование . 33 (6): 443–458. arXiv : 1708.08551 . Бибкод : 2017arXiv170808551N. дои : 10.1111/mice.12359. S2CID 36661983.
^ Набиан, Мохаммад Амин; Мейдани, Хади (2018). «Ускорение стохастической оценки связности транспортных сетей после землетрясения с помощью суррогатов на основе машинного обучения». 97-е ежегодное собрание Совета по транспортным исследованиям . Архивировано из оригинала 9 марта 2018 года . Проверено 14 марта 2018 г.
^ Диас, Э.; Бротонс, В.; Томас, Р. (сентябрь 2018 г.). «Использование искусственных нейронных сетей для прогнозирования трехмерной упругой осадки фундаментов на грунтах с наклонными коренными породами». Почвы и фундаменты . 58 (6): 1414–1422. Бибкод : 2018SoFou..58.1414D. дои : 10.1016/j.sandf.2018.08.001 . hdl : 10045/81208 . ISSN 0038-0806.
^ Тайебиян, А.; Мохаммад, штат Техас; Газали, Ах; Машохор, С. «Искусственная нейронная сеть для моделирования осадков и стоков». Пертаника Журнал науки и технологий . 24 (2): 319–330.
↑ Говиндараджу, Рао С. (1 апреля 2000 г.). «Искусственные нейронные сети в гидрологии. I: Предварительные концепции». Журнал гидрологической техники . 5 (2): 115–123. дои : 10.1061/(ASCE) 1084-0699 (2000) 5: 2 (115).
↑ Говиндараджу, Рао С. (1 апреля 2000 г.). «Искусственные нейронные сети в гидрологии. II: Гидрологические приложения». Журнал гидрологической техники . 5 (2): 124–137. дои : 10.1061/(ASCE) 1084-0699 (2000) 5: 2 (124).
^ Перес, диджей; Юппа, К.; Кавалларо, Л.; Кансельер, А.; Фоти, Э. (1 октября 2015 г.). «Значительное расширение рекордов высоты волн с помощью нейронных сетей и повторного анализа данных о ветре». Моделирование океана . 94 : 128–140. Бибкод : 2015OcMod..94..128P. doi :10.1016/j.ocemod.2015.08.002.
^ Дваракиш, Г.С.; Ракшит, Шетти; Натесан, Уша (2013). «Обзор применения нейронных сетей в прибрежной инженерии». Искусственные интеллектуальные системы и машинное обучение . 5 (7): 324–331. Архивировано из оригинала 15 августа 2017 года . Проверено 5 июля 2017 г.
^ Эрмини, Леонардо; Катани, Филиппо; Касальи, Никола (1 марта 2005 г.). «Искусственные нейронные сети применяются для оценки предрасположенности к оползням». Геоморфология . Геоморфологическая опасность и антропогенное воздействие в горных условиях. 66 (1): 327–343. Бибкод : 2005Geomo..66..327E. doi :10.1016/j.geomorph.2004.09.025.
^ Никс, Р.; Чжан Дж. (май 2017 г.). «Классификация Android-приложений и вредоносных программ с использованием глубоких нейронных сетей». Международная совместная конференция по нейронным сетям 2017 (IJCNN) . стр. 1871–1878. doi : 10.1109/IJCNN.2017.7966078. ISBN978-1-5090-6182-2. S2CID 8838479.
^ «Обнаружение вредоносных URL-адресов». Группа систем и сетей в UCSD . Архивировано из оригинала 14 июля 2019 года . Проверено 15 февраля 2019 г.
^ Хомаюн, Саджад; Ахмадзаде, Марзие; Хашеми, Саттар; Дегантанха, Али; Хаями, Рауф (2018), Дегантанха, Али; Конти, Мауро; Даргахи, Тооска (ред.), «BoTShark: подход глубокого обучения для обнаружения трафика ботнетов», Разведка киберугроз , Достижения в области информационной безопасности, Springer International Publishing, vol. 70, стр. 137–153, номер документа : 10.1007/978-3-319-73951-9_7, ISBN.978-3-319-73951-9
^ Гош и Рейли (январь 1994 г.). «Обнаружение мошенничества с кредитными картами с помощью нейронной сети». Материалы двадцать седьмой Гавайской международной конференции по системным наукам HICSS-94 . Том. 3. С. 621–630. дои : 10.1109/HICSS.1994.323314. ISBN978-0-8186-5090-1. S2CID 13260377.
↑ Анантасвами, Анил (19 апреля 2021 г.). «Новейшие нейронные сети решают сложнейшие в мире уравнения быстрее, чем когда-либо прежде». Журнал Кванта . Проверено 12 мая 2021 г.
^ «ИИ решил ключевую математическую загадку для понимания нашего мира» . Обзор технологий Массачусетского технологического института . Проверено 19 ноября 2020 г. .
^ «ИИ с открытым исходным кодом Калифорнийского технологического института для решения уравнений в частных производных» . ИнфоQ . Архивировано из оригинала 25 января 2021 года . Проверено 20 января 2021 г.
↑ Надь, Александра (28 июня 2019 г.). «Вариационный квантовый метод Монте-Карло с нейросетевым анзацем для открытых квантовых систем». Письма о физических отзывах . 122 (25): 250501. arXiv : 1902.09483 . Бибкод : 2019PhRvL.122y0501N. doi : 10.1103/PhysRevLett.122.250501. PMID 31347886. S2CID 119074378.
^ Ёсиока, Нобуюки; Хамазаки, Рюсуке (28 июня 2019 г.). «Построение нейронных стационарных состояний для открытых квантовых систем многих тел». Физический обзор B . 99 (21): 214306. arXiv : 1902.07006 . Бибкод : 2019PhRvB..99u4306Y. doi : 10.1103/PhysRevB.99.214306. S2CID 119470636.
^ Хартманн, Майкл Дж.; Карлео, Джузеппе (28 июня 2019 г.). «Нейросетевой подход к диссипативной квантовой динамике многих тел». Письма о физических отзывах . 122 (25): 250502. arXiv : 1902.05131 . Бибкод : 2019PhRvL.122y0502H. doi : 10.1103/PhysRevLett.122.250502. PMID 31347862. S2CID 119357494.
^ Вичентини, Филиппо; Бьелла, Альберто; Реньо, Николя; Чути, Криштиану (28 июня 2019 г.). «Вариационный нейросетевой анзац для устойчивых состояний в открытых квантовых системах». Письма о физических отзывах . 122 (25): 250503. arXiv : 1902.10104 . Бибкод : 2019PhRvL.122y0503V. doi : 10.1103/PhysRevLett.122.250503. PMID 31347877. S2CID 119504484.
^ Форрест, доктор медицины (апрель 2015 г.). «Моделирование действия алкоголя на подробной модели нейронов Пуркинье и более простой суррогатной модели, которая работает более чем в 400 раз быстрее». BMC Нейронаука . 16 (27): 27. дои : 10.1186/s12868-015-0162-6 . ПМЦ 4417229 . ПМИД 25928094.
^ Вечорек, Шимон; Филипьяк, Доминик; Филиповская, Агата (2018). «Семантическое профилирование интересов пользователей на основе изображений с помощью нейронных сетей». Исследования семантической сети . 36 (Новые темы семантических технологий). дои : 10.3233/978-1-61499-894-5-179.
^ Сигельманн, HT; Зонтаг, Эд (1991). «Вычислимость по Тьюрингу с помощью нейронных сетей» (PDF) . Прил. Математика. Летт . 4 (6): 77–80. дои : 10.1016/0893-9659(91)90080-F.
↑ Бэйнс, Санни (3 ноября 1998 г.). «Аналоговый компьютер превосходит модель Тьюринга». ЭЭ Таймс . Проверено 11 мая 2023 г.
^ Балькасар, Хосе (июль 1997 г.). «Вычислительная мощность нейронных сетей: характеристика сложности по Колмогорову». Транзакции IEEE по теории информации . 43 (4): 1175–1183. CiteSeerX 10.1.1.411.7782 . дои : 10.1109/18.605580.
^ Обложка, Томас (1965). «Геометрические и статистические свойства систем линейных неравенств с приложениями в распознавании образов» (PDF) . Транзакции IEEE на электронных компьютерах . ИИЭЭ . EC-14 (3): 326–334. дои : 10.1109/PGEC.1965.264137. Архивировано (PDF) из оригинала 5 марта 2016 года . Проверено 10 марта 2020 г.
^ Джеральд, Фридланд (2019). «Воспроизводимость и экспериментальный дизайн машинного обучения аудио и мультимедийных данных». Материалы 27-й Международной конференции ACM по мультимедиа . АКМ . стр. 2709–2710. дои : 10.1145/3343031.3350545. ISBN978-1-4503-6889-6. S2CID 204837170.
^ «Хватит возиться, начните измерять! Предсказуемый экспериментальный дизайн экспериментов с нейронными сетями» . Тензорный расходомер . Архивировано из оригинала 18 апреля 2022 года . Проверено 10 марта 2020 г.
^ Ли, Джехун; Сяо, Лечао; Шенхольц, Сэмюэл С.; Бахри, Ясаман; Новак, Роман; Золь-Дикштейн, Яша; Пеннингтон, Джеффри (2020). «Широкие нейронные сети любой глубины развиваются как линейные модели при градиентном спуске». Журнал статистической механики: теория и эксперимент . 2020 (12): 124002. arXiv : 1902.06720 . Бибкод : 2020JSMTE2020l4002L. дои : 10.1088/1742-5468/abc62b. S2CID 62841516.
^ Артур Жако; Франк Габриэль; Клемент Хонглер (2018). Нейронное касательное ядро: конвергенция и обобщение в нейронных сетях (PDF) . 32-я конференция по нейронным системам обработки информации (NeurIPS 2018), Монреаль, Канада. Архивировано (PDF) из оригинала 22 июня 2022 года . Проверено 4 июня 2022 г.
^ Сюй ZJ, Чжан Ю, Сяо Ю (2019). «Поведение обучения глубокой нейронной сети в частотной области». В Гедеон Т., Вонг К., Ли М. (ред.). Нейронная обработка информации . Конспекты лекций по информатике. Том. 11953. Спрингер, Чам. стр. 264–274. arXiv : 1807.01251 . дои : 10.1007/978-3-030-36708-4_22. ISBN978-3-030-36707-7. S2CID 49562099.
^ Насим Рахаман; Аристид Баратин; Деванш Арпит; Феликс Дракслер; Мин Лин; Фред Хампрехт; Йошуа Бенджио; Аарон Курвиль (2019). «О спектральном смещении нейронных сетей» (PDF) . Материалы 36-й Международной конференции по машинному обучению . 97 : 5301–5310. arXiv : 1806.08734 . Архивировано (PDF) из оригинала 22 октября 2022 года . Проверено 4 июня 2022 г.
^ Чжи-Цинь Джон Сюй; Яоюй Чжан; Тао Ло; Яньян Сяо; Чжэн Ма (2020). «Частотный принцип: анализ Фурье проливает свет на глубокие нейронные сети». Коммуникации в вычислительной физике . 28 (5): 1746–1767. arXiv : 1901.06523 . Бибкод : 2020CCoPh..28.1746X. doi : 10.4208/cicp.OA-2020-0085. S2CID 58981616.
^ Тао Ло; Чжэн Ма; Чжи-Цинь Джон Сюй; Яоюй Чжан (2019). «Теория частотного принципа для глубоких нейронных сетей общего назначения». arXiv : 1906.09235 [cs.LG].
^ Сюй, Чжицинь Джон; Чжоу, Ханьсюй (18 мая 2021 г.). «Принцип глубокой частоты для понимания того, почему более глубокое обучение происходит быстрее». Материалы конференции AAAI по искусственному интеллекту . 35 (12): 10541–10550. arXiv : 2007.14313 . дои : 10.1609/aaai.v35i12.17261. ISSN 2374-3468. S2CID 220831156. Архивировано из оригинала 5 октября 2021 года . Проверено 5 октября 2021 г.
^ Паризи, Герман И.; Кемкер, Рональд; Парт, Хосе Л.; Кэнан, Кристофер; Вермтер, Стефан (1 мая 2019 г.). «Непрерывное обучение на протяжении всей жизни с помощью нейронных сетей: обзор». Нейронные сети . 113 : 54–71. arXiv : 1802.07569 . дои : 10.1016/j.neunet.2019.01.012 . ISSN 0893-6080. ПМИД 30780045.
^ Дин Померло, «Обучение искусственных нейронных сетей, основанное на знаниях, для автономного вождения роботов»
↑ Дьюдни, АК (1 апреля 1997 г.). Да, у нас нет нейтронов: поучительный экскурс в перипетии плохой науки. Уайли. п. 82. ИСБН978-0-471-10806-1.
^ НАСА - Центр летных исследований Драйдена - Центр новостей: Выпуски новостей: ПРОЕКТ НЕЙРОННОЙ СЕТИ НАСА ПРОХОДИТ ВЕХУ. Архивировано 2 апреля 2010 г. в Wayback Machine . НАСА.gov. Проверено 20 ноября 2013 г.
^ "Защита нейронных сетей Роджером Бриджменом" . Архивировано из оригинала 19 марта 2012 года . Проверено 12 июля 2010 г.
^ «Масштабирование алгоритмов обучения в сторону {AI} — LISA — Публикации — Aigaion 2.0» . www.iro.umonreal.ca .
^ DJ Felleman и DC Van Essen, «Распределенная иерархическая обработка данных в коре головного мозга приматов», Cerebral Cortex , 1, стр. 1–47, 1991.
^ Дж. Венг, «Естественный и искусственный интеллект: введение в вычислительный мозг-разум», BMI Press, ISBN 978-0-9858757-2-5 , 2012.
↑ Аб Эдвардс, Крис (25 июня 2015 г.). «Болезнь роста глубокого обучения». Коммуникации АКМ . 58 (7): 14–16. дои : 10.1145/2771283. S2CID 11026540.
↑ Кейд Мец (18 мая 2016 г.). «Google создала собственные чипы для работы своих ботов с искусственным интеллектом». Проводной . Архивировано из оригинала 13 января 2018 года . Проверено 5 марта 2017 г.
^ «Масштабирование алгоритмов обучения в сторону ИИ» (PDF) . Архивировано (PDF) из оригинала 12 августа 2022 года . Проверено 6 июля 2022 г.
^ Аб Норири, Наталья; Ху, Цян; Эллен, Флоренс Марсель; Фарачи, Франческа Далия; Цовара, Афина (октябрь 2021 г.). «Устранение предвзятости в больших данных и искусственном интеллекте в здравоохранении: призыв к открытой науке». Узоры . 2 (10): 100347. doi : 10.1016/j.patter.2021.100347 .
^ аб Карина, Ван (27 октября 2022 г.). «Провал по номинальной стоимости: влияние предвзятой технологии распознавания лиц на расовую дискриминацию в уголовном правосудии». Научные и социальные исследования . 4 (10): 29–40. дои : 10.26689/ssr.v4i10.4402 . ISSN 2661-4332.
↑ Аб Чанг, Синьюй (13 сентября 2023 г.). «Гендерная предвзятость при найме: анализ влияния алгоритма рекрутинга Amazon». Достижения в области экономики, менеджмента и политических наук . 23 (1): 134–140. дои : 10.54254/2754-1169/23/20230367 . ISSN 2754-1169.
^ Кортылевски, Адам; Эггер, Бернхард; Шнайдер, Андреас; Гериг, Томас; Морель-Форстер, Андреас; Веттер, Томас (июнь 2019 г.). «Анализ и уменьшение ущерба от смещения набора данных при распознавании лиц с помощью синтетических данных». Семинары конференции IEEE/CVF 2019 года по компьютерному зрению и распознаванию образов (CVPRW) (PDF) . IEEE. стр. 2261–2268. doi : 10.1109/cvprw.2019.00279. ISBN978-1-7281-2506-0. S2CID 198183828.
^ abcdef Хуан, Янбо (2009). «Достижения в области искусственных нейронных сетей - методологическое развитие и применение». Алгоритмы . 2 (3): 973–1007. дои : 10.3390/algor2030973 . ISSN 1999-4893.
^ abcde Карири, Эльхам; Луати, Хассен; Луати, Али; Масмуди, Фатма (2023). «Изучение достижений и будущих направлений исследований искусственных нейронных сетей: подход к интеллектуальному анализу текста». Прикладные науки . 13 (5): 3186. дои : 10.3390/app13053186 . ISSN 2076-3417.
^ аб Фуй-Хун На, Фиона; Чжэн, Жуйлинь; Цай, Цзинъюань; Сиау, Кенг; Чен, Лантао (3 июля 2023 г.). «Генераторный ИИ и ChatGPT: приложения, проблемы и сотрудничество ИИ и человека». Журнал исследований и применений информационных технологий . 25 (3): 277–304. дои : 10.1080/15228053.2023.2233814 . ISSN 1522-8053.
^ «Самое интересное в этом - сбои DALL-E 2 - IEEE Spectrum» . Spectrum.ieee.org . Проверено 9 декабря 2023 г.
^ Брио, Жан-Пьер (январь 2021 г.). «От искусственных нейронных сетей к глубокому обучению для создания музыки: история, концепции и тенденции». Нейронные вычисления и их приложения . 33 (1): 39–65. дои : 10.1007/s00521-020-05399-0 . ISSN 0941-0643.
↑ Чоу, Пей-Сзе (6 июля 2020 г.). «Призрак в (Голливудской) машине: новые применения искусственного интеллекта в киноиндустрии». NECSUS_Европейский журнал медиаисследований . doi : 10.25969/MEDIAREP/14307. ISSN 2213-0217.
^ Ю, Синьруй; Он, Соджу; Гао, Юань; Ян, Цзяцзянь; Ша, Линдао; Чжан, Идань; Ай, Чжаобо (июнь 2010 г.). «Динамическая регулировка сложности игрового ИИ для видеоигры Dead-End». 3-я Международная конференция по информатике и наукам о взаимодействии . IEEE. стр. 583–587. doi : 10.1109/icicis.2010.5534761. ISBN978-1-4244-7384-7. S2CID 17555595.
Библиография
Бхадешиа HKDH (1999). «Нейронные сети в материаловедении» (PDF) . ISIJ International . 39 (10): 966–979. doi : 10.2355/isijinternational.39.966.
Бишоп, Кристофер М. (1995). Нейронные сети для распознавания образов . Кларендон Пресс. ISBN 978-0-19-853849-3. ОСЛК 33101074.
Боргельт, Кристиан (2003). Neuro-Fuzzy-Systeme: von den Grundlagen künstlicher Neuronaler Netze zur Kopplung mit Fuzzy-Systemen . Посмотретьег. ISBN 978-3-528-25265-6. ОСЛК 76538146.
Фальман, С.; Лебьер, К. (1991). «Архитектура обучения с каскадной корреляцией» (PDF) . Архивировано из оригинала (PDF) 3 мая 2013 года . Проверено 28 августа 2006 г.
Герни, Кевин (1997). Введение в нейронные сети . УКЛ Пресс. ISBN 978-1-85728-673-1. ОСЛК 37875698.
Хайкин, Саймон С. (1999). Нейронные сети: комплексная основа . Прентис Холл. ISBN 978-0-13-273350-2. ОСЛК 38908586.
Герц, Дж.; Палмер, Ричард Г.; Крог, Андерс С. (1991). Введение в теорию нейронных вычислений . Аддисон-Уэсли. ISBN 978-0-201-51560-2. ОСЛК 21522159.
Теория информации, логический вывод и алгоритмы обучения . Издательство Кембриджского университета. 25 сентября 2003 г. Бибкод : 2003itil.book.....М. ISBN 978-0-521-64298-9. ОСЛК 52377690.
Лоуренс, Жанетт (1994). Введение в нейронные сети: проектирование, теория и приложения . Калифорнийское научное программное обеспечение. ISBN 978-1-883157-00-5. ОСЛК 32179420.
Мастерс, Тимоти (1994). Обработка сигналов и изображений с помощью нейронных сетей: справочник по C++ . Дж. Уайли. ISBN 978-0-471-04963-0. ОКЛК 29877717.
Маурер, Харальд (2021). Когнитивная наука: механизмы интегративной синхронизации в когнитивных нейроархитектурах современного коннекционизма . ЦРК Пресс. дои : 10.1201/9781351043526. ISBN 978-1-351-04352-6. S2CID 242963768.





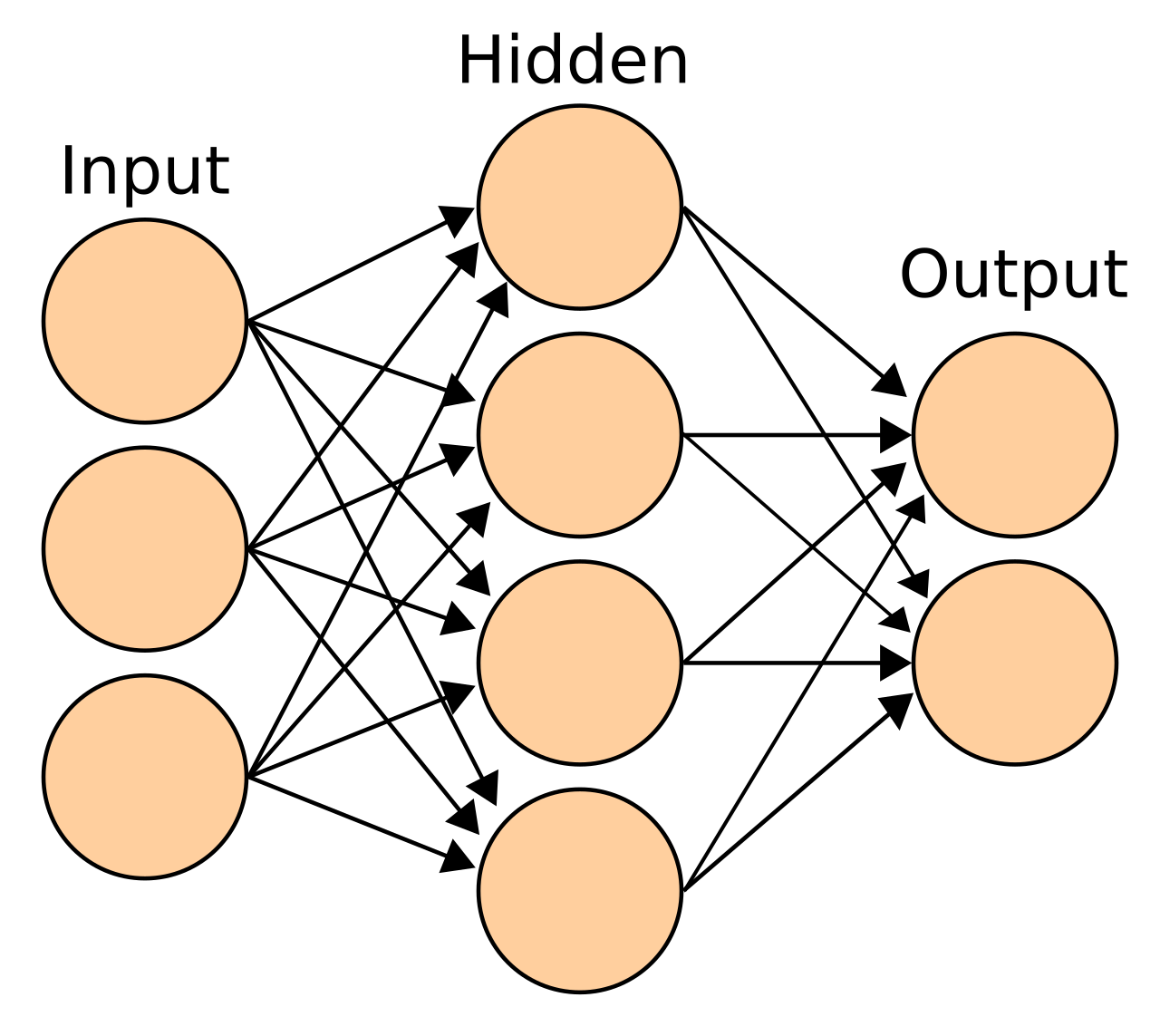
.svg/1280px-Ann_dependency_(graph).svg.png)





![{\displaystyle \textstyle C=E[(xf(x))^{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2929ecb1606fdfeaddc55477d9671e11c034e21c)










