Искусственный интеллект ( ИИ ) в самом широком смысле — это интеллект , демонстрируемый машинами , в частности компьютерными системами . Это область исследований в области компьютерных наук , которая разрабатывает и изучает методы и программное обеспечение , позволяющие машинам воспринимать окружающую среду и использовать обучение и интеллект для выполнения действий, которые максимизируют их шансы на достижение определенных целей. [1] Такие машины можно назвать ИИ.
Некоторые громкие приложения ИИ включают в себя продвинутые поисковые системы (например, Google Search ); рекомендательные системы (используемые YouTube , Amazon и Netflix ); взаимодействие с помощью человеческой речи (например, Google Assistant , Siri и Alexa ); автономные транспортные средства (например, Waymo ); генеративные и творческие инструменты (например, ChatGPT и AI art ); и сверхчеловеческая игра и анализ в стратегических играх (например, шахматы и Go ). Однако многие приложения ИИ не воспринимаются как ИИ: «Многие передовые ИИ просочились в общие приложения, часто не называясь ИИ, потому что как только что-то становится достаточно полезным и достаточно распространенным, оно больше не называется ИИ ». [2] [3]
Различные подобласти исследований ИИ сосредоточены вокруг конкретных целей и использования конкретных инструментов. Традиционные цели исследований ИИ включают рассуждение , представление знаний , планирование , обучение , обработку естественного языка , восприятие и поддержку робототехники . [a] Общий интеллект — способность выполнять любую задачу, выполняемую человеком, по крайней мере на равном уровне — входит в число долгосрочных целей области. [4] Для достижения этих целей исследователи ИИ адаптировали и интегрировали широкий спектр методов, включая поиск и математическую оптимизацию , формальную логику , искусственные нейронные сети и методы, основанные на статистике , исследовании операций и экономике . [b] ИИ также опирается на психологию , лингвистику , философию , нейронауку и другие области. [5]
Искусственный интеллект был основан как академическая дисциплина в 1956 году, [6] и эта область прошла через несколько циклов оптимизма, [7] [8] за которыми последовали периоды разочарования и потери финансирования, известные как зима ИИ . [9] [10] Финансирование и интерес значительно возросли после 2012 года, когда глубокое обучение превзошло предыдущие методы ИИ. [11] Этот рост еще больше ускорился после 2017 года с архитектурой трансформатора , [12] и к началу 2020-х годов сотни миллиардов долларов были инвестированы в ИИ (известно как « бум ИИ »). Широкое использование ИИ в 21 веке выявило несколько непреднамеренных последствий и вреда в настоящем и вызвало обеспокоенность по поводу его рисков и долгосрочных эффектов в будущем, что вызвало дискуссии о регуляторной политике для обеспечения безопасности и преимуществ технологии .
Общая проблема моделирования (или создания) интеллекта была разбита на подзадачи. Они состоят из конкретных черт или возможностей, которые исследователи ожидают от интеллектуальной системы. Черты, описанные ниже, получили наибольшее внимание и охватывают область исследований ИИ. [a]
Ранние исследователи разработали алгоритмы, которые имитировали пошаговые рассуждения, которые используют люди, когда решают головоломки или делают логические выводы . [13] К концу 1980-х и 1990-м годам были разработаны методы работы с неопределенной или неполной информацией, использующие концепции из теории вероятности и экономики . [14]
Многие из этих алгоритмов недостаточны для решения больших задач рассуждения, поскольку они испытывают «комбинаторный взрыв»: они становятся экспоненциально медленнее по мере роста задач. [15] Даже люди редко используют пошаговую дедукцию, которую могли моделировать ранние исследования ИИ. Они решают большинство своих задач, используя быстрые, интуитивные суждения. [16] Точное и эффективное рассуждение — нерешенная проблема.

Представление знаний и инженерия знаний [17] позволяют программам ИИ разумно отвечать на вопросы и делать выводы о фактах реального мира. Формальные представления знаний используются в индексации и поиске на основе контента, [18] интерпретации сцен, [19] поддержке принятия клинических решений, [20] обнаружении знаний (извлечение «интересных» и действенных выводов из больших баз данных ), [21] и других областях. [22]
База знаний — это совокупность знаний, представленная в форме, которую может использовать программа. Онтология — это набор объектов, отношений, концепций и свойств, используемых определенной областью знаний. [23] Базы знаний должны представлять такие вещи, как объекты, свойства, категории и отношения между объектами; [24] ситуации, события, состояния и время; [25] причины и следствия; [26] знания о знаниях (то, что мы знаем о том, что знают другие люди); [27] рассуждения по умолчанию (то, что люди считают истинным, пока им не скажут иначе, и что останется истинным, даже если другие факты изменятся); [28] и многие другие аспекты и области знаний.
Среди наиболее сложных проблем в представлении знаний — широта знаний здравого смысла (набор атомарных фактов, которые знает средний человек, огромен); [29] и субсимвольная форма большинства знаний здравого смысла (большая часть того, что знают люди, не представлена в виде «фактов» или «утверждений», которые они могли бы выразить вербально). [16] Существует также сложность приобретения знаний , проблема получения знаний для приложений ИИ. [c]
«Агент» — это все, что воспринимает и совершает действия в мире. Рациональный агент имеет цели или предпочтения и совершает действия, чтобы они произошли. [d] [32] В автоматизированном планировании у агента есть конкретная цель. [33] В автоматизированном принятии решений у агента есть предпочтения — есть некоторые ситуации, в которых он предпочел бы оказаться, и некоторые ситуации, которых он пытается избежать. Агент принятия решений присваивает каждой ситуации число (называемое « полезностью »), которое измеряет, насколько агент ее предпочитает. Для каждого возможного действия он может рассчитать « ожидаемую полезность »: полезность всех возможных результатов действия, взвешенную по вероятности того, что результат произойдет. Затем он может выбрать действие с максимальной ожидаемой полезностью. [34]
В классическом планировании агент точно знает, каким будет эффект любого действия. [35] Однако в большинстве реальных проблем агент может не быть уверен в ситуации, в которой он находится (она «неизвестна» или «ненаблюдаема»), и он может не знать наверняка, что произойдет после каждого возможного действия (она не «детерминирована»). Он должен выбрать действие, сделав вероятностное предположение, а затем переоценить ситуацию, чтобы увидеть, сработало ли действие. [36]
В некоторых задачах предпочтения агента могут быть неопределенными, особенно если в них участвуют другие агенты или люди. Их можно изучить (например, с помощью обратного обучения с подкреплением ), или агент может искать информацию для улучшения своих предпочтений. [37] Теория ценности информации может использоваться для оценки ценности исследовательских или экспериментальных действий. [38] Пространство возможных будущих действий и ситуаций обычно непреодолимо велико, поэтому агенты должны предпринимать действия и оценивать ситуации, будучи неуверенными в том, каким будет результат.
Процесс принятия решений Маркова имеет модель перехода , которая описывает вероятность того, что определенное действие изменит состояние определенным образом, и функцию вознаграждения , которая предоставляет полезность каждого состояния и стоимость каждого действия. Политика связывает решение с каждым возможным состоянием. Политика может быть рассчитана (например, путем итерации ), быть эвристической или ее можно изучить. [39]
Теория игр описывает рациональное поведение множества взаимодействующих агентов и используется в программах ИИ, которые принимают решения с участием других агентов. [40]
Машинное обучение — это изучение программ, которые могут автоматически улучшать свою производительность при выполнении заданной задачи. [41] Оно было частью ИИ с самого начала. [e]
Существует несколько видов машинного обучения. Неконтролируемое обучение анализирует поток данных, находит закономерности и делает прогнозы без какого-либо другого руководства. [44] Контролируемое обучение требует, чтобы человек сначала маркировал входные данные, и существует в двух основных разновидностях: классификация (где программа должна научиться предсказывать, к какой категории относятся входные данные) и регрессия (где программа должна вывести числовую функцию на основе числового ввода). [45]
В обучении с подкреплением агент вознаграждается за хорошие ответы и наказывается за плохие. Агент учится выбирать ответы, которые классифицируются как «хорошие». [46] Передача обучения — это когда знания, полученные при решении одной проблемы, применяются к новой проблеме. [47] Глубокое обучение — это тип машинного обучения, который пропускает входные данные через биологически вдохновленные искусственные нейронные сети для всех этих типов обучения. [48]
Теория вычислительного обучения может оценивать учащихся по вычислительной сложности , по сложности выборки (сколько требуется данных) или по другим понятиям оптимизации . [49]
Обработка естественного языка (NLP) [50] позволяет программам читать, писать и общаться на человеческих языках, таких как английский . Конкретные проблемы включают распознавание речи , синтез речи , машинный перевод , извлечение информации , поиск информации и ответы на вопросы . [51]
Ранние работы, основанные на генеративной грамматике и семантических сетях Ноама Хомского , испытывали трудности с разрешением неоднозначности слов [f], если только не ограничивались небольшими областями, называемыми « микромирами » (из-за проблемы знания здравого смысла [29] ). Маргарет Мастерман считала, что ключом к пониманию языков является значение, а не грамматика, и что тезаурусы , а не словари должны быть основой вычислительной языковой структуры.
Современные методы глубокого обучения для обработки естественного языка включают в себя внедрение слов (представление слов, как правило, в виде векторов , кодирующих их значение), [52] трансформаторы (архитектура глубокого обучения, использующая механизм внимания ), [53] и другие. [54] В 2019 году генеративные предварительно обученные языковые модели трансформатора (или «GPT») начали генерировать связный текст, [55] [56] и к 2023 году эти модели смогли получить баллы человеческого уровня на экзамене на адвоката , тесте SAT , тесте GRE и многих других реальных приложениях. [57]
Машинное восприятие — это способность использовать входные данные от датчиков (таких как камеры, микрофоны, беспроводные сигналы, активный лидар , сонар, радар и тактильные датчики ) для вывода аспектов мира. Компьютерное зрение — это способность анализировать визуальные входные данные. [58]
Область включает в себя распознавание речи , [59] классификацию изображений , [60] распознавание лиц , распознавание объектов , [61] отслеживание объектов , [62] и роботизированное восприятие . [63]

Аффективные вычисления — это междисциплинарная область, включающая системы, которые распознают, интерпретируют, обрабатывают или имитируют человеческие чувства, эмоции и настроение . [65] Например, некоторые виртуальные помощники запрограммированы на разговорную речь или даже на шутливые шутки; это делает их более чувствительными к эмоциональной динамике человеческого взаимодействия или иным образом облегчает взаимодействие человека с компьютером .
Однако это имеет тенденцию давать наивным пользователям нереалистичное представление об интеллекте существующих компьютерных агентов. [66] Умеренные успехи, связанные с аффективными вычислениями, включают текстовый анализ настроений и, в последнее время, мультимодальный анализ настроений , в котором ИИ классифицирует эмоции, демонстрируемые субъектом, записанным на видео. [67]
Машина с искусственным интеллектом должна быть способна решать широкий спектр задач с широтой и универсальностью, аналогичной человеческому интеллекту . [4]
Исследования ИИ используют широкий спектр методов для достижения вышеуказанных целей. [b]
ИИ может решать многие проблемы, разумно перебирая множество возможных решений. [68] В ИИ используются два совершенно разных вида поиска: поиск в пространстве состояний и локальный поиск .
Поиск в пространстве состояний просматривает дерево возможных состояний, чтобы попытаться найти целевое состояние. [69] Например, алгоритмы планирования просматривают деревья целей и подцелей, пытаясь найти путь к заданной цели, процесс, называемый анализом средств и целей . [70]
Простые исчерпывающие поиски [71] редко бывают достаточными для большинства реальных проблем: пространство поиска (количество мест для поиска) быстро увеличивается до астрономических чисел . Результатом является поиск, который слишком медленный или никогда не завершается. [15] « Эвристика » или «правила большого пальца» могут помочь расставить приоритеты в выборе, которые с большей вероятностью достигнут цели. [72]
Состязательный поиск используется для игровых программ, таких как шахматы или го. Он просматривает дерево возможных ходов и контрходов, ища выигрышную позицию. [73]

Локальный поиск использует математическую оптимизацию для поиска решения проблемы. Он начинается с некоторой формы догадки и совершенствует ее постепенно. [74]
Градиентный спуск — это тип локального поиска, который оптимизирует набор числовых параметров путем их постепенной корректировки для минимизации функции потерь . Варианты градиентного спуска обычно используются для обучения нейронных сетей. [75]
Другим типом локального поиска является эволюционное вычисление , целью которого является итеративное улучшение набора возможных решений путем их «мутации» и «рекомбинации», выбирая только наиболее приспособленных для выживания в каждом поколении. [76]
Распределенные процессы поиска могут координироваться с помощью алгоритмов роевого интеллекта . Два популярных алгоритма роя, используемых в поиске, — это оптимизация роя частиц (вдохновленная стаями птиц ) и оптимизация колонии муравьев (вдохновленная муравьиными тропами ). [77]
Формальная логика используется для рассуждений и представления знаний . [78] Формальная логика существует в двух основных формах: пропозициональная логика (которая оперирует утверждениями, которые являются истинными или ложными, и использует логические связки , такие как «и», «или», «не» и «подразумевает») [79] и предикатная логика (которая также оперирует объектами, предикатами и отношениями и использует квантификаторы, такие как « Каждый X есть Y » и «Существуют некоторые X , которые являются Y »). [80]
Дедуктивное рассуждение в логике — это процесс доказательства нового утверждения ( вывода ) из других утверждений, которые даны и считаются истинными (предпосылки ) . [81] Доказательства могут быть структурированы в виде деревьев доказательств , в которых узлы помечены предложениями, а дочерние узлы связаны с родительскими узлами правилами вывода .
При наличии проблемы и набора предпосылок решение проблем сводится к поиску дерева доказательств, корневой узел которого помечен решением проблемы, а конечные узлы помечены предпосылками или аксиомами . В случае предложений Хорна поиск решения проблем может быть выполнен путем рассуждения вперед от предпосылок или назад от проблемы. [82] В более общем случае клаузальной формы логики первого порядка разрешение представляет собой единое правило вывода, свободное от аксиом, в котором проблема решается путем доказательства противоречия из предпосылок, которые включают отрицание решаемой проблемы. [83]
Вывод как в логике предложений Хорна, так и в логике первого порядка неразрешим , и, следовательно, не поддается обработке . Однако обратное рассуждение с предложениями Хорна, которое лежит в основе вычислений в языке логического программирования Пролог , является полным по Тьюрингу . Более того, его эффективность сопоставима с вычислениями в других символических языках программирования. [84]
Нечеткая логика присваивает «степень истинности» от 0 до 1. Поэтому она может обрабатывать предложения, которые являются неопределенными и частично истинными. [85]
Немонотонная логика , включая логическое программирование с отрицанием как неудачей , предназначена для обработки рассуждений по умолчанию . [28] Были разработаны и другие специализированные версии логики для описания многих сложных областей.

Многие проблемы в ИИ (включая рассуждения, планирование, обучение, восприятие и робототехнику) требуют, чтобы агент работал с неполной или неопределенной информацией. Исследователи ИИ разработали ряд инструментов для решения этих проблем, используя методы теории вероятностей и экономики. [86] Были разработаны точные математические инструменты, которые анализируют, как агент может делать выбор и планировать, используя теорию принятия решений , анализ решений , [87] и теорию ценности информации . [88] Эти инструменты включают такие модели, как марковские процессы принятия решений , [89] динамические сети принятия решений , [90] теория игр и проектирование механизмов . [91]
Байесовские сети [92] — это инструмент, который можно использовать для рассуждений (с использованием алгоритма байесовского вывода ), [g] [94] обучения (с использованием алгоритма максимизации ожидания ), [h] [96] планирования (с использованием сетей принятия решений ) [97] и восприятия (с использованием динамических байесовских сетей ). [90]
Вероятностные алгоритмы также могут использоваться для фильтрации, прогнозирования, сглаживания и поиска объяснений для потоков данных, тем самым помогая системам восприятия анализировать процессы, происходящие с течением времени (например, скрытые модели Маркова или фильтры Калмана ). [90]

Простейшие приложения ИИ можно разделить на два типа: классификаторы (например, «если блестящий, то бриллиант»), с одной стороны, и контроллеры (например, «если бриллиант, то подбери»), с другой стороны. Классификаторы [98] — это функции, которые используют сопоставление с образцом для определения наиболее близкого соответствия. Их можно точно настроить на основе выбранных примеров с использованием контролируемого обучения . Каждый образец (также называемый « наблюдением ») помечен определенным предопределенным классом. Все наблюдения, объединенные с их метками классов, известны как набор данных . Когда получено новое наблюдение, это наблюдение классифицируется на основе предыдущего опыта. [45]
Существует множество видов классификаторов. [99] Дерево решений — это самый простой и наиболее широко используемый символический алгоритм машинного обучения. [100] Алгоритм k-ближайших соседей был наиболее широко используемым аналоговым ИИ до середины 1990-х годов, а методы ядра, такие как машина опорных векторов (SVM), вытеснили k-ближайших соседей в 1990-х годах. [101] Сообщается, что наивный байесовский классификатор является «наиболее широко используемым обучающимся средством» [102] в Google, отчасти из-за его масштабируемости. [103] Нейронные сети также используются в качестве классификаторов. [104]
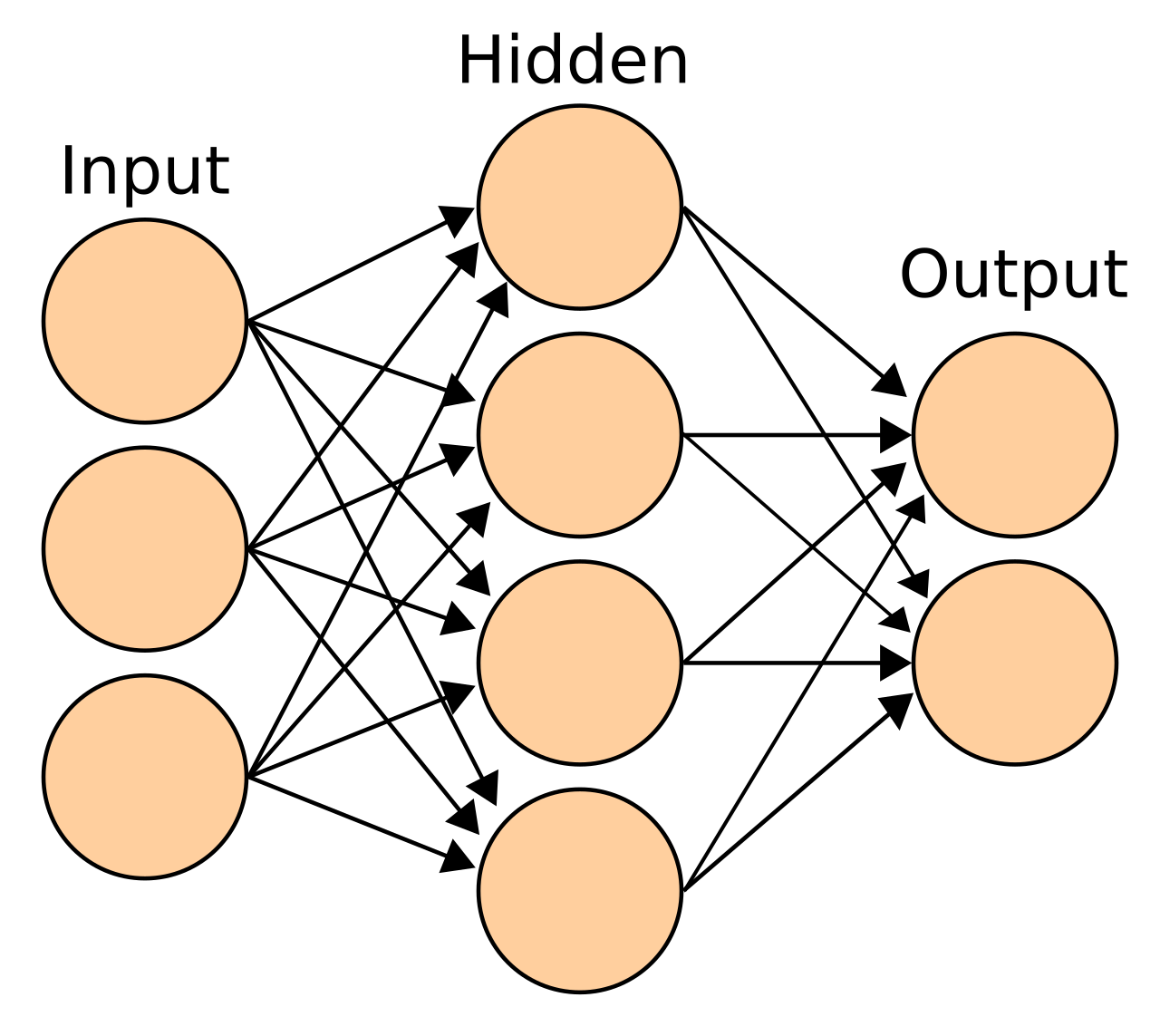
Искусственная нейронная сеть основана на наборе узлов, также известных как искусственные нейроны , которые в общих чертах моделируют нейроны в биологическом мозге. Она обучена распознавать закономерности; после обучения она может распознавать эти закономерности в новых данных. Есть вход, по крайней мере один скрытый слой узлов и выход. Каждый узел применяет функцию, и как только вес пересекает указанный порог, данные передаются на следующий слой. Сеть обычно называется глубокой нейронной сетью, если она имеет по крайней мере 2 скрытых слоя. [104]
Алгоритмы обучения для нейронных сетей используют локальный поиск для выбора весов, которые дадут правильный выход для каждого входа во время обучения. Наиболее распространенным методом обучения является алгоритм обратного распространения . [105] Нейронные сети учатся моделировать сложные отношения между входами и выходами и находить закономерности в данных. Теоретически нейронная сеть может изучить любую функцию. [106]
В нейронных сетях прямого распространения сигнал проходит только в одном направлении. [107] Рекуррентные нейронные сети возвращают выходной сигнал на вход, что позволяет сохранять кратковременные воспоминания о предыдущих входных событиях. Долговременная кратковременная память является наиболее успешной сетевой архитектурой для рекуррентных сетей. [108] Персептроны [109] используют только один слой нейронов; глубокое обучение [110] использует несколько слоев. Сверточные нейронные сети усиливают связь между нейронами, которые находятся «близко» друг к другу — это особенно важно при обработке изображений , где локальный набор нейронов должен идентифицировать «край», прежде чем сеть сможет идентифицировать объект. [111]

Глубокое обучение [110] использует несколько слоев нейронов между входами и выходами сети. Несколько слоев могут постепенно извлекать более высокоуровневые признаки из необработанных входных данных. Например, при обработке изображений более низкие слои могут определять края, в то время как более высокие слои могут определять концепции, имеющие отношение к человеку, такие как цифры, буквы или лица. [112]
Глубокое обучение значительно улучшило производительность программ во многих важных областях искусственного интеллекта, включая компьютерное зрение , распознавание речи , обработку естественного языка , классификацию изображений [113] и другие. Причина , по которой глубокое обучение так хорошо работает во многих приложениях, по состоянию на 2023 год неизвестна. [114] Внезапный успех глубокого обучения в 2012–2015 годах произошел не из-за какого-то нового открытия или теоретического прорыва (глубокие нейронные сети и обратное распространение были описаны многими людьми еще в 1950-х годах) [i], а из-за двух факторов: невероятного увеличения мощности компьютеров (включая стократное увеличение скорости за счет перехода на графические процессоры ) и доступности огромных объемов обучающих данных, особенно гигантских курируемых наборов данных , используемых для эталонного тестирования, таких как ImageNet . [j]
Генеративные предварительно обученные трансформаторы (GPT) — это большие языковые модели (LLM), которые генерируют текст на основе семантических отношений между словами в предложениях. Текстовые модели GPT предварительно обучаются на большом корпусе текста , который может быть из Интернета. Предварительное обучение состоит из прогнозирования следующего токена (токен обычно является словом, подсловом или знаком препинания). На протяжении этого предварительного обучения модели GPT накапливают знания о мире и затем могут генерировать текст, похожий на человеческий, многократно предсказывая следующий токен. Как правило, последующая фаза обучения делает модель более правдивой, полезной и безвредной, обычно с помощью техники, называемой обучением с подкреплением на основе обратной связи с человеком (RLHF). Текущие модели GPT склонны генерировать ложь, называемую « галлюцинациями », хотя это можно уменьшить с помощью RLHF и качественных данных. Они используются в чат-ботах , которые позволяют людям задавать вопросы или запрашивать задание в простом тексте. [122] [123]
Текущие модели и сервисы включают Gemini (ранее Bard), ChatGPT , Grok , Claude , Copilot и LLaMA . [124] Мультимодальные модели GPT могут обрабатывать различные типы данных ( модальности ), такие как изображения, видео, звук и текст. [125]
В конце 2010-х годов графические процессоры (GPU), которые все чаще разрабатывались с усовершенствованиями, специфичными для ИИ, и использовались со специализированным программным обеспечением TensorFlow, заменили ранее используемые центральные процессоры (CPU) в качестве доминирующего средства для обучения крупномасштабных (коммерческих и академических) моделей машинного обучения . [126] Специализированные языки программирования , такие как Prolog, использовались в ранних исследованиях ИИ, [127] но языки программирования общего назначения, такие как Python, стали преобладающими. [128]
Было замечено, что плотность транзисторов в интегральных схемах примерно удваивается каждые 18 месяцев — тенденция, известная как закон Мура , названная в честь соучредителя Intel Гордона Мура , который первым ее обнаружил. Улучшения в графических процессорах происходили еще быстрее. [129]
Технология ИИ и машинного обучения используется в большинстве основных приложений 2020-х годов, включая: поисковые системы (например, Google Search ), таргетинг онлайн-рекламы , рекомендательные системы (предлагаемые Netflix , YouTube или Amazon ), управление интернет-трафиком , таргетинговая реклама ( AdSense , Facebook ), виртуальные помощники (например, Siri или Alexa ), автономные транспортные средства (включая дроны , ADAS и беспилотные автомобили ), автоматический языковой перевод ( Microsoft Translator , Google Translate ), распознавание лиц ( Face ID от Apple или DeepFace от Microsoft и FaceNet от Google ) и маркировка изображений (используется Facebook , iPhoto от Apple и TikTok ). Развертывание ИИ может контролироваться главным директором по автоматизации (CAO).
Применение ИИ в медицине и медицинских исследованиях может повысить качество ухода за пациентами и качество жизни. [130] С точки зрения клятвы Гиппократа медицинские работники этически обязаны использовать ИИ, если приложения могут более точно диагностировать и лечить пациентов. [131] [132]
Для медицинских исследований ИИ является важным инструментом для обработки и интеграции больших данных . Это особенно важно для разработки органоидов и тканевой инженерии , которые используют микроскопическую визуализацию в качестве ключевого метода изготовления. [133] Было высказано предположение, что ИИ может преодолеть расхождения в финансировании, выделяемом на различные области исследований. [133] Новые инструменты ИИ могут углубить понимание биомедицинских значимых путей. Например, AlphaFold 2 (2021) продемонстрировал способность аппроксимировать трехмерную структуру белка за часы, а не за месяцы . [134] В 2023 году сообщалось, что открытие лекарств под руководством ИИ помогло найти класс антибиотиков, способных убивать два разных типа устойчивых к лекарствам бактерий. [135] В 2024 году исследователи использовали машинное обучение для ускорения поиска лекарственных средств для лечения болезни Паркинсона . Их целью было выявление соединений, которые блокируют слипание или агрегацию альфа-синуклеина (белка, характеризующего болезнь Паркинсона). Им удалось ускорить процесс первоначального отбора в десять раз и сократить расходы в тысячу раз. [136] [137]
Программы для игр использовались с 1950-х годов для демонстрации и тестирования самых передовых методов ИИ. [138] Deep Blue стала первой компьютерной шахматной системой, которая победила действующего чемпиона мира по шахматам Гарри Каспарова 11 мая 1997 года. [139] В 2011 году в показательном матче викторины Jeopardy! система ответов на вопросы IBM Watson победила двух величайших чемпионов Jeopardy! Брэда Раттера и Кена Дженнингса со значительным отрывом. [140] В марте 2016 года AlphaGo выиграла 4 из 5 игр в го в матче с чемпионом го Ли Седолем , став первой компьютерной системой для игры в го, которая победила профессионального игрока в го без гандикапов . Затем, в 2017 году, она победила Кэ Цзе , который был лучшим игроком в го в мире. [141] Другие программы обрабатывают игры с несовершенной информацией , такие как программа для игры в покер Pluribus . [142] DeepMind разработала все более универсальные модели обучения с подкреплением , такие как MuZero , которые можно было обучить играть в шахматы, го или игры Atari . [143] В 2019 году AlphaStar от DeepMind достигла уровня гроссмейстера в StarCraft II , особенно сложной стратегической игре в реальном времени, которая предполагает неполное знание того, что происходит на карте. [144] В 2021 году агент ИИ участвовал в соревновании PlayStation Gran Turismo , победив четырех лучших в мире водителей Gran Turismo, используя глубокое обучение с подкреплением. [145] В 2024 году Google DeepMind представила SIMA, тип ИИ, способный автономно играть в девять ранее невиданных видеоигр с открытым миром , наблюдая за выводом на экран, а также выполняя короткие конкретные задачи в ответ на инструкции естественного языка. [146]
В математике используются специальные формы формального пошагового рассуждения . Напротив, LLM, такие как GPT-4 Turbo , Gemini Ultra , Claude Opus , LLaMa-2 или Mistral Large , работают с вероятностными моделями, которые могут давать неправильные ответы в форме галлюцинаций . Поэтому им нужна не только большая база данных математических задач для обучения, но и такие методы, как контролируемая тонкая настройка или обученные классификаторы с данными, аннотированными человеком, для улучшения ответов на новые задачи и обучения на исправлениях. [147] Исследование 2024 года показало, что производительность некоторых языковых моделей для возможностей рассуждения при решении математических задач, не включенных в их обучающие данные, была низкой, даже для задач с небольшими отклонениями от обучающих данных. [148]
В качестве альтернативы были разработаны специальные модели для решения математических задач с более высокой точностью результата, включая доказательство теорем, такие как Alpha Tensor , Alpha Geometry и Alpha Proof, все из Google DeepMind , [149] Llemma из eleuther [150] или Julius . [151]
Когда для описания математических задач используется естественный язык, конвертеры преобразуют такие подсказки в формальный язык, такой как Lean, для определения математических задач.
Некоторые модели были разработаны для решения сложных задач и достижения хороших результатов в контрольных тестах, другие — в качестве учебных пособий по математике. [152]
Финансы являются одним из наиболее быстрорастущих секторов, где внедряются прикладные инструменты ИИ: от розничного онлайн-банкинга до инвестиционного консультирования и страхования, где автоматизированные «роботы-консультанты» используются уже несколько лет. [153]
Эксперты World Pensions , такие как Николас Фирцли, утверждают, что, возможно, еще слишком рано ожидать появления инновационных финансовых продуктов и услуг на основе искусственного интеллекта: «Развертывание инструментов искусственного интеллекта просто еще больше автоматизирует процессы: в процессе будут уничтожены десятки тысяч рабочих мест в банковской сфере, финансовом планировании и пенсионном консультировании, но я не уверен, что это вызовет новую волну [например, сложных] пенсионных инноваций». [154]
Различные страны развертывают военные приложения ИИ. [155] Основные приложения улучшают командование и управление , связь, датчики, интеграцию и взаимодействие. [156] Исследования нацелены на сбор и анализ разведданных, логистику, кибероперации, информационные операции, а также полуавтономные и автономные транспортные средства . [155] Технологии ИИ позволяют координировать работу датчиков и эффекторов, обнаруживать и идентифицировать угрозы, отмечать позиции противника, захватывать цели , координировать и устранять конфликты распределенных совместных огней между сетевыми боевыми машинами с участием пилотируемых и беспилотных команд. [156] ИИ был включен в военные операции в Ираке и Сирии. [155]
В ноябре 2023 года вице-президент США Камала Харрис раскрыла декларацию, подписанную 31 страной, чтобы установить ограничения для военного использования ИИ. Обязательства включают использование юридических проверок для обеспечения соответствия военного ИИ международным законам, а также осторожность и прозрачность в разработке этой технологии. [157]

В начале 2020-х годов генеративный ИИ получил широкую известность. GenAI — это ИИ, способный генерировать текст, изображения, видео или другие данные с использованием генеративных моделей , [158] [159] часто в ответ на подсказки . [160] [161]
В марте 2023 года 58% взрослых американцев слышали о ChatGPT , а 14% пробовали его. [162] Растущая реалистичность и простота использования генераторов текста в изображения на основе ИИ , таких как Midjourney , DALL-E и Stable Diffusion, вызвали тенденцию вирусных фотографий, созданных ИИ. Широкое внимание привлекли фальшивая фотография Папы Франциска в белом пуховике, вымышленный арест Дональда Трампа и мистификация нападения на Пентагон , а также использование в профессиональном творчестве. [163] [164]
Искусственные интеллектуальные (ИИ) агенты — это программные сущности, разработанные для восприятия своего окружения, принятия решений и выполнения действий автономно для достижения определенных целей. Эти агенты могут взаимодействовать с пользователями, своим окружением или другими агентами. Агенты ИИ используются в различных приложениях, включая виртуальных помощников , чат-ботов , автономные транспортные средства , игровые системы и промышленную робототехнику . Агенты ИИ действуют в рамках ограничений своего программирования, доступных вычислительных ресурсов и аппаратных ограничений. Это означает, что они ограничены выполнением задач в пределах своей определенной области и имеют конечные возможности памяти и обработки. В реальных приложениях агенты ИИ часто сталкиваются с ограничениями по времени для принятия решений и выполнения действий. Многие агенты ИИ включают алгоритмы обучения, что позволяет им со временем улучшать свою производительность за счет опыта или обучения. Используя машинное обучение, агенты ИИ могут адаптироваться к новым ситуациям и оптимизировать свое поведение для своих назначенных задач. [165] [166] [167]
Существуют также тысячи успешных приложений ИИ, используемых для решения конкретных проблем для конкретных отраслей или учреждений. В опросе 2017 года каждая пятая компания сообщила о внедрении «ИИ» в некоторые предложения или процессы. [168] Несколько примеров — хранение энергии , медицинская диагностика, военная логистика, приложения, которые предсказывают результат судебных решений, внешняя политика или управление цепочками поставок.
Растет число приложений ИИ для эвакуации и управления стихийными бедствиями . ИИ использовался для расследования того, эвакуировались ли люди и как это было сделано в ходе крупномасштабных и мелкомасштабных эвакуаций, используя исторические данные из GPS, видео или социальных сетей. Кроме того, ИИ может предоставлять информацию в реальном времени об условиях эвакуации в реальном времени. [169] [170] [171]
В сельском хозяйстве ИИ помог фермерам определить области, которые нуждаются в орошении, удобрении, обработке пестицидами или повышении урожайности. Агрономы используют ИИ для проведения исследований и разработок. ИИ использовался для прогнозирования времени созревания таких культур, как томаты, мониторинга влажности почвы, управления сельскохозяйственными роботами, проведения предиктивной аналитики , классификации эмоций свиней, автоматизации теплиц, обнаружения болезней и вредителей и экономии воды.
Искусственный интеллект используется в астрономии для анализа все большего количества доступных данных и приложений, в основном для «классификации, регрессии, кластеризации, прогнозирования, генерации, открытия и разработки новых научных идей». Например, он используется для открытия экзопланет, прогнозирования солнечной активности и различения сигналов и инструментальных эффектов в гравитационно-волновой астрономии. Кроме того, его можно использовать для деятельности в космосе, такой как исследование космоса, включая анализ данных с космических миссий, принятие научных решений в реальном времени для космических аппаратов, избегание космического мусора и более автономную работу.
ИИ имеет потенциальные преимущества и потенциальные риски. [172] ИИ может быть в состоянии продвигать науку и находить решения для серьезных проблем: Демис Хассабис из Deep Mind надеется «решить проблему интеллекта, а затем использовать это для решения всего остального». [173] Однако, поскольку использование ИИ стало широко распространенным, было выявлено несколько непреднамеренных последствий и рисков. [174] В производственных системах иногда не могут учитывать этику и предвзятость в процессах обучения ИИ, особенно когда алгоритмы ИИ по своей сути необъяснимы в глубоком обучении. [175]
Алгоритмы машинного обучения требуют больших объемов данных. Методы, используемые для получения этих данных, вызвали опасения по поводу конфиденциальности , наблюдения и авторских прав .
Устройства и сервисы на базе ИИ, такие как виртуальные помощники и продукты IoT, постоянно собирают персональные данные, вызывая опасения по поводу навязчивого сбора данных и несанкционированного доступа третьих лиц. Потеря конфиденциальности еще больше усугубляется способностью ИИ обрабатывать и объединять огромные объемы данных, что потенциально приводит к обществу наблюдения, где индивидуальные действия постоянно отслеживаются и анализируются без адекватных мер безопасности или прозрачности.
Конфиденциальные данные пользователей, собранные, могут включать записи об активности в сети, данные геолокации, видео или аудио. [176] Например, для создания алгоритмов распознавания речи Amazon записала миллионы частных разговоров и позволила временным работникам прослушивать и расшифровывать некоторые из них. [177] Мнения об этой широко распространенной слежке варьируются от тех, кто считает ее необходимым злом , до тех, для кого она явно неэтична и нарушает право на неприкосновенность частной жизни . [178]
Разработчики ИИ утверждают, что это единственный способ предоставить ценные приложения. и разработали несколько методов, которые пытаются сохранить конфиденциальность, продолжая получать данные, такие как агрегация данных , деидентификация и дифференциальная конфиденциальность . [179] С 2016 года некоторые эксперты по конфиденциальности, такие как Синтия Дворк , начали рассматривать конфиденциальность с точки зрения справедливости . Брайан Кристиан написал, что эксперты перешли «от вопроса «что они знают» к вопросу «что они с этим делают»». [180]
Генеративный ИИ часто обучается на нелицензированных работах, защищенных авторским правом, в том числе в таких областях, как изображения или компьютерный код; затем вывод используется в соответствии с обоснованием « добросовестного использования ». Эксперты расходятся во мнениях относительно того, насколько хорошо и при каких обстоятельствах это обоснование будет иметь силу в судах; соответствующие факторы могут включать «цель и характер использования защищенной авторским правом работы» и «влияние на потенциальный рынок для защищенной авторским правом работы». [181] [182] Владельцы веб-сайтов, которые не хотят, чтобы их контент был удален, могут указать это в файле « robots.txt ». [183] В 2023 году ведущие авторы (включая Джона Гришэма и Джонатана Франзена ) подали в суд на компании, занимающиеся ИИ, за использование их работ для обучения генеративного ИИ. [184] [185] Другой обсуждаемый подход заключается в том, чтобы представить отдельную систему sui generis защиты для творений, созданных ИИ, чтобы гарантировать справедливое указание авторства и компенсацию авторам-людям. [186]
На рынке коммерческого ИИ доминируют крупные технологические компании, такие как Alphabet Inc. , Amazon , Apple Inc. , Meta Platforms и Microsoft . [187] [188] [189] Некоторые из этих игроков уже владеют подавляющим большинством существующей облачной инфраструктуры и вычислительной мощности центров обработки данных , что позволяет им еще больше укрепиться на рынке. [190] [191]
В январе 2024 года Международное энергетическое агентство (МЭА) опубликовало отчет «Электричество 2024, анализ и прогноз до 2026 года » , в котором спрогнозировано потребление электроэнергии. [192] Это первый отчет МЭА, в котором даны прогнозы относительно центров обработки данных и потребления электроэнергии для искусственного интеллекта и криптовалюты. В отчете говорится, что спрос на электроэнергию для этих целей может удвоиться к 2026 году, при этом дополнительное потребление электроэнергии будет равно потреблению электроэнергии всей японской нацией. [193]
Огромное потребление энергии ИИ ответственно за рост использования ископаемого топлива и может задержать закрытие устаревших, выбрасывающих углерод угольных энергетических объектов. В США наблюдается лихорадочный рост строительства центров обработки данных, что превращает крупные технологические компании (например, Microsoft, Meta, Google, Amazon) в прожорливых потребителей электроэнергии. Прогнозируемое потребление электроэнергии настолько огромно, что есть опасения, что оно будет выполнено независимо от источника. Поиск ChatGPT предполагает использование в 10 раз больше электроэнергии, чем поиск Google. Крупные компании спешат найти источники энергии — от ядерной энергии до геотермальной и термоядерной. Технологические компании утверждают, что — в долгосрочной перспективе — ИИ в конечном итоге станет добрее к окружающей среде, но им нужна энергия сейчас. ИИ делает электросеть более эффективной и «интеллектуальной», будет способствовать росту ядерной энергетики и отслеживать общие выбросы углерода, по словам технологических компаний. [194]
В исследовательской работе Goldman Sachs 2024 года « Центры обработки данных ИИ и грядущий всплеск спроса на электроэнергию в США » говорится, что «спрос на электроэнергию в США, вероятно, будет расти, как никогда за последнее поколение...» и прогнозируется, что к 2030 году центры обработки данных США будут потреблять 8% электроэнергии США по сравнению с 3% в 2022 году, что предвещает рост электроэнергетической отрасли различными способами. [195] Потребность центров обработки данных во все большем количестве электроэнергии такова, что они могут перегрузить электросеть. Крупные технологические компании возражают, что ИИ можно использовать для максимального использования сети всеми. [196]
В 2024 году Wall Street Journal сообщил, что крупные компании ИИ начали переговоры с поставщиками ядерной энергии США о поставке электроэнергии в центры обработки данных. В марте 2024 года Amazon приобрела центр обработки данных на ядерной энергии в Пенсильвании за 650 миллионов долларов США. [197]
В сентябре 2024 года Microsoft объявила о соглашении с Constellation Energy о повторном открытии атомной электростанции Three Mile Island , которая будет поставлять Microsoft 100% всей электроэнергии, производимой станцией в течение 20 лет. Повторное открытие станции, на которой в 1979 году произошел частичный ядерный расплав реактора второго блока, потребует от Constellation пройти строгие нормативные процессы, которые будут включать тщательный контроль безопасности со стороны Комиссии по ядерному регулированию США . В случае одобрения (это будет первый в истории США повторный ввод в эксплуатацию атомной станции) будет произведено более 835 мегаватт электроэнергии — достаточно для 800 000 домов. Стоимость повторного открытия и модернизации оценивается в 1,6 млрд долларов США и зависит от налоговых льгот для ядерной энергетики, содержащихся в Законе США о снижении инфляции 2022 года . [198] Правительство США и штат Мичиган инвестируют почти 2 миллиарда долларов США в повторное открытие ядерного реактора Palisades на озере Мичиган. Закрытый с 2022 года завод, как планируется, будет повторно открыт в октябре 2025 года. Объект Three Mile Island будет переименован в Crane Clean Energy Center в честь Криса Крейна, сторонника ядерной энергетики и бывшего генерального директора Exelon , который отвечал за отделение Exelon от Constellation. [199]
YouTube , Facebook и другие используют рекомендательные системы , чтобы направлять пользователей к большему количеству контента. Эти программы ИИ были поставлены перед целью максимизировать вовлеченность пользователей (то есть единственной целью было заставить людей смотреть). ИИ узнал, что пользователи склонны выбирать дезинформацию , теории заговора и экстремальный партийный контент, и, чтобы заставить их смотреть, ИИ рекомендовал больше этого. Пользователи также склонны смотреть больше контента на одну и ту же тему, поэтому ИИ заводил людей в пузыри фильтров , где они получали несколько версий одной и той же дезинформации. [200] Это убедило многих пользователей в том, что дезинформация была правдой, и в конечном итоге подорвало доверие к институтам, СМИ и правительству. [201] Программа ИИ правильно научилась максимизировать свою цель, но результат был вреден для общества. После выборов в США в 2016 году крупные технологические компании предприняли шаги для смягчения проблемы [ необходима цитата ] .
В 2022 году генеративный ИИ начал создавать изображения, аудио, видео и текст, которые неотличимы от настоящих фотографий, записей, фильмов или человеческого письма. Злоумышленники могут использовать эту технологию для создания огромных объемов дезинформации или пропаганды. [202] Пионер ИИ Джеффри Хинтон выразил обеспокоенность по поводу того, что ИИ позволяет «авторитарным лидерам манипулировать своим электоратом» в больших масштабах, среди прочих рисков. [203]
Приложения машинного обучения будут предвзятыми [k], если они обучаются на предвзятых данных. [205] Разработчики могут не знать о существовании предвзятости. [206] Предвзятость может быть вызвана способом выбора обучающих данных и способом развертывания модели. [207] [205] Если предвзятый алгоритм используется для принятия решений, которые могут серьезно навредить людям (как это может быть в медицине , финансах , подборе персонала , жилищном обеспечении или работе полиции ), то алгоритм может вызвать дискриминацию . [208] Область справедливости изучает, как предотвратить вред от алгоритмических предвзятостей.
28 июня 2015 года новая функция маркировки изображений Google Photos ошибочно идентифицировала Джеки Элсина и его друга как «горилл», потому что они были черными. Система была обучена на наборе данных, который содержал очень мало изображений чернокожих людей, [209] проблема, называемая «несоответствием размера выборки». [210] Google «исправил» эту проблему, запретив системе маркировать что-либо как «гориллу». Восемь лет спустя, в 2023 году, Google Photos все еще не мог идентифицировать гориллу, как и аналогичные продукты от Apple, Facebook, Microsoft и Amazon. [211]
COMPAS — это коммерческая программа, широко используемая судами США для оценки вероятности рецидивизма обвиняемого . В 2016 году Джулия Энгвин из ProPublica обнаружила, что COMPAS демонстрирует расовую предвзятость, несмотря на то, что программе не сообщали расы обвиняемых. Хотя частота ошибок для белых и черных была откалибрована одинаково и составляла ровно 61%, ошибки для каждой расы были разными — система последовательно переоценивала вероятность того, что черный человек совершит повторное преступление, и недооценивала вероятность того, что белый человек не совершит повторное преступление. [212] В 2017 году несколько исследователей [l] показали, что математически невозможно, чтобы COMPAS учитывал все возможные меры справедливости, когда базовые показатели повторных преступлений были разными для белых и черных в данных. [214]
Программа может принимать предвзятые решения, даже если данные явно не упоминают проблемную характеристику (такую как «раса» или «пол»). Характеристика будет коррелировать с другими характеристиками (такими как «адрес», «история покупок» или «имя»), и программа будет принимать те же решения на основе этих характеристик, как и на основе «расы» или «пола». [215] Мориц Хардт сказал: «Наиболее весомым фактом в этой области исследований является то, что справедливость через слепоту не работает». [216]
Критика COMPAS подчеркнула, что модели машинного обучения разработаны для того, чтобы делать «предсказания», которые действительны только в том случае, если мы предполагаем, что будущее будет похоже на прошлое. Если они обучены на данных, которые включают результаты расистских решений в прошлом, модели машинного обучения должны предсказывать, что расистские решения будут приняты в будущем. Если затем приложение использует эти предсказания в качестве рекомендаций , некоторые из этих «рекомендаций», вероятно, будут расистскими. [217] Таким образом, машинное обучение не очень подходит для помощи в принятии решений в областях, где есть надежда, что будущее будет лучше прошлого. Оно носит описательный, а не предписывающий характер. [m]
Предвзятость и несправедливость могут остаться незамеченными, поскольку разработчики в подавляющем большинстве белые мужчины: среди инженеров ИИ около 4% — чернокожие и 20% — женщины. [210]
Существуют различные противоречивые определения и математические модели справедливости. Эти понятия зависят от этических предположений и находятся под влиянием убеждений об обществе. Одной из широких категорий является распределительная справедливость , которая фокусируется на результатах, часто идентифицируя группы и стремясь компенсировать статистические различия. Репрезентативная справедливость пытается гарантировать, что системы ИИ не усиливают негативные стереотипы или не делают определенные группы невидимыми. Процедурная справедливость фокусируется на процессе принятия решений, а не на результате. Наиболее значимые понятия справедливости могут зависеть от контекста, в частности от типа приложения ИИ и заинтересованных сторон. Субъективность в понятиях предвзятости и справедливости затрудняет их операционализацию для компаний. Многие специалисты по этике ИИ также считают, что доступ к чувствительным атрибутам, таким как раса или пол, необходим для компенсации предвзятости, но это может противоречить законам о борьбе с дискриминацией . [204]
На своей конференции 2022 года по справедливости, подотчетности и прозрачности (ACM FAccT 2022) Ассоциация вычислительной техники в Сеуле, Южная Корея, представила и опубликовала выводы, в которых говорится, что до тех пор, пока не будет продемонстрировано, что системы искусственного интеллекта и робототехники свободны от ошибок предвзятости, они небезопасны, а использование самообучающихся нейронных сетей, обученных на обширных, нерегулируемых источниках некорректных интернет-данных, следует ограничить. [ сомнительно – обсудить ] [219]
Многие системы ИИ настолько сложны, что их разработчики не могут объяснить, как они принимают свои решения. [220] Особенно это касается глубоких нейронных сетей , в которых существует большое количество нелинейных отношений между входами и выходами. Но существуют некоторые популярные методы объяснимости. [221]
Невозможно быть уверенным в том, что программа работает правильно, если никто не знает, как именно она работает. Было много случаев, когда программа машинного обучения проходила строгие тесты, но тем не менее узнавала что-то иное, чем то, что планировали программисты. Например, было обнаружено, что система, которая могла определять кожные заболевания лучше, чем медицинские специалисты, на самом деле имела сильную тенденцию классифицировать изображения с линейкой как «раковые», потому что изображения злокачественных новообразований обычно включают линейку для отображения масштаба. [222] Было обнаружено, что другая система машинного обучения, разработанная для помощи в эффективном распределении медицинских ресурсов, классифицировала пациентов с астмой как имеющих «низкий риск» смерти от пневмонии. Наличие астмы на самом деле является серьезным фактором риска, но поскольку пациенты с астмой обычно получали гораздо больше медицинской помощи, они были относительно маловероятны, чтобы умереть, согласно данным обучения. Корреляция между астмой и низким риском смерти от пневмонии была реальной, но вводящей в заблуждение. [223]
Люди, которым был нанесен ущерб решением алгоритма, имеют право на объяснение. [224] Например, врачи должны четко и полностью объяснять своим коллегам обоснование любого принятого ими решения. Ранние проекты Общего регламента по защите данных Европейского союза в 2016 году включали явное заявление о том, что такое право существует. [n] Эксперты отрасли отметили, что это нерешенная проблема, решения которой не видно. Регуляторы утверждали, что, тем не менее, вред реален: если проблема не имеет решения, инструменты не следует использовать. [225]
В 2014 году DARPA запустила программу XAI («Объяснимый искусственный интеллект»), чтобы попытаться решить эти проблемы. [226]
Несколько подходов направлены на решение проблемы прозрачности. SHAP позволяет визуализировать вклад каждой функции в вывод. [227] LIME может локально аппроксимировать выводы модели с помощью более простой, интерпретируемой модели. [228] Многозадачное обучение обеспечивает большое количество выводов в дополнение к целевой классификации. Эти другие выводы могут помочь разработчикам сделать вывод о том, чему научилась сеть. [229] Деконволюция , DeepDream и другие генеративные методы могут позволить разработчикам увидеть, чему научились различные слои глубокой сети для компьютерного зрения, и создать вывод, который может подсказать, чему учится сеть. [230] Для генеративных предварительно обученных трансформаторов Anthropic разработала метод, основанный на обучении по словарю , который связывает шаблоны активаций нейронов с понятными человеку концепциями. [231]
Искусственный интеллект предоставляет ряд инструментов, которые полезны для злоумышленников , таких как авторитарные правительства , террористы , преступники или государства-изгои .
Смертоносное автономное оружие — это машина, которая находит, выбирает и поражает человеческие цели без человеческого контроля. [o] Широко доступные инструменты ИИ могут использоваться злоумышленниками для разработки недорогого автономного оружия, и если они производятся в больших масштабах, они потенциально являются оружием массового поражения . [233] Даже при использовании в обычных боевых действиях маловероятно, что они не смогут надежно выбирать цели и потенциально могут убить невинного человека . [233] В 2014 году 30 стран (включая Китай) поддержали запрет на автономное оружие в соответствии с Конвенцией ООН о конкретных видах обычного оружия , однако Соединенные Штаты и другие страны не согласились. [234] К 2015 году сообщалось, что более пятидесяти стран исследовали боевых роботов. [235]
Инструменты ИИ облегчают авторитарным правительствам эффективный контроль над своими гражданами несколькими способами. Распознавание лиц и голоса позволяет осуществлять широкомасштабное наблюдение . Машинное обучение , оперируя этими данными, может классифицировать потенциальных врагов государства и не давать им скрываться. Рекомендательные системы могут точно нацеливать пропаганду и дезинформацию для максимального эффекта. Глубокие фейки и генеративный ИИ помогают в производстве дезинформации. Продвинутый ИИ может сделать авторитарное централизованное принятие решений более конкурентоспособным, чем либеральные и децентрализованные системы, такие как рынки . Это снижает стоимость и сложность цифровой войны и передового шпионского ПО . [236] Все эти технологии доступны с 2020 года или ранее — системы распознавания лиц ИИ уже используются для массового наблюдения в Китае. [237] [238]
Есть много других способов, которыми ИИ, как ожидается, будет помогать плохим актерам, некоторые из которых невозможно предвидеть. Например, машинное обучение ИИ способно спроектировать десятки тысяч токсичных молекул за считанные часы. [239]
Экономисты часто подчеркивали риски увольнений из-за ИИ и рассуждали о безработице, если не будет адекватной социальной политики для полной занятости. [240]
В прошлом технологии имели тенденцию увеличивать, а не сокращать общую занятость, но экономисты признают, что «мы находимся на неизведанной территории» с ИИ. [241] Опрос экономистов показал разногласия относительно того, вызовет ли растущее использование роботов и ИИ существенный рост долгосрочной безработицы , но они в целом согласны, что это может быть чистой выгодой, если рост производительности будет перераспределен . [242] Оценки риска различаются; например, в 2010-х годах Майкл Осборн и Карл Бенедикт Фрей оценили, что 47% рабочих мест в США находятся под «высоким риском» потенциальной автоматизации, в то время как отчет ОЭСР классифицировал только 9% рабочих мест в США как «высокий риск». [p] [244] Методология спекуляций о будущих уровнях занятости подвергалась критике за отсутствие доказательной базы и за то, что подразумевает, что технологии, а не социальная политика, создают безработицу, а не увольнения. [240] В апреле 2023 года сообщалось, что 70% рабочих мест для китайских иллюстраторов видеоигр были ликвидированы генеративным искусственным интеллектом. [245] [246]
В отличие от предыдущих волн автоматизации, многие рабочие места среднего класса могут быть ликвидированы искусственным интеллектом; The Economist заявил в 2015 году, что «опасение, что ИИ может сделать с рабочими местами «белых воротничков» то же, что паровая энергия сделала с рабочими местами «синих воротничков» во время промышленной революции», «стоит отнестись серьезно». [247] Рабочие места с экстремальным риском варьируются от помощников юристов до поваров фастфуда, в то время как спрос на рабочие места, связанные с уходом, вероятно, возрастет, начиная от личного здравоохранения и заканчивая духовенством. [248]
С первых дней развития искусственного интеллекта существовали аргументы, например, выдвинутые Джозефом Вайценбаумом , о том, должны ли задачи, которые могут быть выполнены компьютерами, на самом деле выполняться ими, учитывая разницу между компьютерами и людьми, а также между количественными расчетами и качественными, основанными на ценностях суждениями. [249]
Утверждалось, что ИИ станет настолько мощным, что человечество может необратимо потерять над ним контроль. Это может, как сказал физик Стивен Хокинг , « означать конец человеческой расы ». [250] Этот сценарий был распространен в научной фантастике, когда компьютер или робот внезапно развивает человеческое «самосознание» (или «чувство», или «сознание») и становится злобным персонажем. [q] Эти научно-фантастические сценарии вводят в заблуждение несколькими способами.
Во-первых, ИИ не требует человеческой « чувствительности », чтобы быть экзистенциальным риском. Современные программы ИИ получают конкретные цели и используют обучение и интеллект для их достижения. Философ Ник Бостром утверждал, что если дать практически любую цель достаточно мощному ИИ, он может решить уничтожить человечество, чтобы ее достичь (он использовал пример менеджера фабрики по производству скрепок ). [252] Стюарт Рассел приводит пример домашнего робота, который пытается найти способ убить своего владельца, чтобы предотвратить его отключение, рассуждая, что «вы не сможете принести кофе, если вы мертвы». [253] Чтобы быть безопасным для человечества, сверхразум должен был бы быть искренне согласован с моралью и ценностями человечества, чтобы он был «в основе своей на нашей стороне». [254]
Во-вторых, Юваль Ной Харари утверждает, что ИИ не требует тела робота или физического контроля, чтобы представлять экзистенциальный риск. Основные части цивилизации не являются физическими. Такие вещи, как идеологии , закон , правительство , деньги и экономика , сделаны из языка ; они существуют, потому что есть истории, в которые верят миллиарды людей. Текущее распространение дезинформации предполагает, что ИИ может использовать язык, чтобы убедить людей верить во что угодно, даже совершать действия, которые являются разрушительными. [255]
Мнения экспертов и представителей отрасли неоднозначны, и значительная часть из них как обеспокоена, так и не обеспокоена риском, который может возникнуть со стороны сверхразумного ИИ. [256] Такие личности, как Стивен Хокинг , Билл Гейтс и Илон Маск , [257], а также пионеры ИИ, такие как Йошуа Бенджио , Стюарт Рассел , Демис Хассабис и Сэм Альтман , выражали обеспокоенность по поводу экзистенциального риска со стороны ИИ.
В мае 2023 года Джеффри Хинтон объявил о своем уходе из Google, чтобы иметь возможность «свободно говорить о рисках ИИ», не «думая о том, как это повлияет на Google». [258] Он, в частности, упомянул риски поглощения ИИ , [259] и подчеркнул, что для того, чтобы избежать худших результатов, установление правил безопасности потребует сотрудничества между теми, кто конкурирует в использовании ИИ. [260]
В 2023 году многие ведущие эксперты в области ИИ выступили с совместным заявлением о том, что «Снижение риска вымирания из-за ИИ должно стать глобальным приоритетом наряду с другими рисками общественного масштаба, такими как пандемии и ядерная война» [261] .
Другие исследователи, однако, высказались в пользу менее антиутопической точки зрения. Пионер ИИ Юрген Шмидхубер не подписал совместное заявление, подчеркнув, что в 95% всех случаев исследования ИИ направлены на то, чтобы сделать «человеческую жизнь более долгой, здоровой и легкой». [262] Хотя инструменты, которые сейчас используются для улучшения жизни, могут использоваться и плохими игроками, «они также могут быть использованы против плохих игроков». [263] [264] Эндрю Нг также утверждал, что «ошибочно поддаваться шумихе вокруг конца света вокруг ИИ, и что регуляторы, которые это делают, только выиграют от корыстных интересов». [265] Янн Лекун «высмеивает антиутопические сценарии своих коллег о чрезмерной дезинформации и даже, в конечном итоге, о вымирании человечества». [266] В начале 2010-х годов эксперты утверждали, что риски слишком отдалены в будущем, чтобы оправдать исследования, или что люди будут ценны с точки зрения сверхразумной машины. [267] Однако после 2016 года изучение текущих и будущих рисков и возможных решений стало серьезной областью исследований. [268]
Дружественный ИИ — это машины, которые изначально были разработаны для минимизации рисков и принятия решений, приносящих пользу людям. Элиезер Юдковски , который придумал этот термин, утверждает, что разработка дружественного ИИ должна быть более приоритетной в исследованиях: это может потребовать больших инвестиций и должно быть завершено до того, как ИИ станет экзистенциальным риском. [269]
Машины с интеллектом имеют потенциал использовать свой интеллект для принятия этических решений. Область машинной этики предоставляет машинам этические принципы и процедуры для разрешения этических дилемм. [270] Область машинной этики также называется вычислительной моралью, [270] и была основана на симпозиуме AAAI в 2005 году. [271]
Другие подходы включают «искусственных моральных агентов» Уэнделла Уоллаха [272] и три принципа Стюарта Дж. Рассела для разработки доказуемо полезных машин. [273]
Активные организации в сообществе открытого исходного кода ИИ включают Hugging Face , [274] Google , [275] EleutherAI и Meta . [276] Различные модели ИИ, такие как Llama 2 , Mistral или Stable Diffusion , были сделаны с открытым весом, [277] [278] что означает, что их архитектура и обученные параметры («веса») являются общедоступными. Модели с открытым весом могут быть свободно настроены , что позволяет компаниям специализировать их с помощью собственных данных и для собственного варианта использования. [279] Модели с открытым весом полезны для исследований и инноваций, но также могут быть использованы не по назначению. Поскольку их можно настроить, любая встроенная мера безопасности, такая как возражение против вредоносных запросов, может быть обучена до тех пор, пока она не станет неэффективной. Некоторые исследователи предупреждают, что будущие модели ИИ могут развить опасные возможности (например, потенциал для радикального содействия биотерроризму ), и что после публикации в Интернете их нельзя будет удалить везде, если это необходимо. Они рекомендуют проводить предварительные аудиты и анализы затрат и выгод. [280]
Проекты искусственного интеллекта могут иметь этическую допустимость, проверенную при проектировании, разработке и внедрении системы ИИ. Структура ИИ, такая как Care and Act Framework, содержащая ценности SUM, разработанная Институтом Алана Тьюринга, проверяет проекты в четырех основных областях: [281] [282]
Другие разработки в этических рамках включают решения, принятые на конференции в Асиломаре , Монреальскую декларацию об ответственном ИИ и инициативу IEEE по этике автономных систем, среди прочих; [283] однако эти принципы не обходятся без критики, особенно в отношении людей, выбранных для внесения вклада в эти рамки. [284]
Содействие благополучию людей и сообществ, на которые влияют эти технологии, требует учета социальных и этических последствий на всех этапах проектирования, разработки и внедрения систем ИИ, а также сотрудничества между специалистами по работе с данными, менеджерами по продуктам, инженерами по работе с данными, экспертами в предметной области и менеджерами по доставке. [285]
Институт безопасности ИИ Великобритании выпустил в 2024 году набор инструментов тестирования под названием «Inspect» для оценки безопасности ИИ, доступный по лицензии MIT с открытым исходным кодом, который свободно доступен на GitHub и может быть улучшен с помощью сторонних пакетов. Его можно использовать для оценки моделей ИИ в различных областях, включая основные знания, способность рассуждать и автономные возможности. [286]

Регулирование искусственного интеллекта — это разработка политик и законов государственного сектора для продвижения и регулирования ИИ; поэтому оно связано с более широким регулированием алгоритмов. [287] Нормативно-правовой ландшафт для ИИ является новой проблемой в юрисдикциях по всему миру. [288] Согласно индексу ИИ в Стэнфорде , ежегодное количество законов, связанных с ИИ, принятых в 127 странах, охваченных исследованием, возросло с одного, принятого в 2016 году, до 37, принятых только в 2022 году. [289] [290] В период с 2016 по 2020 год более 30 стран приняли специальные стратегии для ИИ. [291] Большинство государств-членов ЕС выпустили национальные стратегии в области ИИ, как и Канада, Китай, Индия, Япония, Маврикий, Российская Федерация, Саудовская Аравия, Объединенные Арабские Эмираты, США и Вьетнам. Другие находились в процессе разработки собственной стратегии в области ИИ, включая Бангладеш, Малайзию и Тунис. [291] Глобальное партнерство по искусственному интеллекту было запущено в июне 2020 года, заявив о необходимости разработки ИИ в соответствии с правами человека и демократическими ценностями, чтобы обеспечить общественное доверие к технологии. [291] Генри Киссинджер , Эрик Шмидт и Дэниел Хуттенлохер опубликовали совместное заявление в ноябре 2021 года, призвав к созданию правительственной комиссии по регулированию ИИ. [292] В 2023 году лидеры OpenAI опубликовали рекомендации по управлению сверхразумом, которое, по их мнению, может произойти менее чем через 10 лет. [293] В 2023 году Организация Объединенных Наций также создала консультативный орган для предоставления рекомендаций по управлению ИИ; в состав органа входят руководители технологических компаний, государственные служащие и ученые. [294] В 2024 году Совет Европы создал первый международный юридически обязательный договор по ИИ, названный « Рамочная конвенция об искусственном интеллекте и правах человека, демократии и верховенстве закона ». Он был принят Европейским Союзом, Соединенными Штатами, Соединенным Королевством и другими подписавшими его странами. [295]
В опросе Ipsos 2022 года отношение к ИИ сильно различалось в зависимости от страны; 78% граждан Китая, но только 35% американцев согласились с тем, что «продукты и услуги, использующие ИИ, имеют больше преимуществ, чем недостатков». [289] Опрос Reuters /Ipsos 2023 года показал, что 61% американцев согласны, а 22% не согласны, что ИИ представляет опасность для человечества. [296] В опросе Fox News 2023 года 35% американцев считали «очень важным», а еще 41% считали «довольно важным» регулирование ИИ федеральным правительством, по сравнению с 13% ответившими «не очень важно» и 8% ответившими «совсем не важно». [297] [298]
В ноябре 2023 года в Блетчли-Парке в Великобритании состоялся первый всемирный саммит по безопасности ИИ, на котором обсуждались краткосрочные и долгосрочные риски ИИ и возможность создания обязательных и добровольных нормативных рамок. [299] 28 стран, включая США, Китай и Европейский союз, опубликовали декларацию в начале саммита, призывающую к международному сотрудничеству для управления вызовами и рисками искусственного интеллекта. [300] [301] В мае 2024 года на саммите ИИ в Сеуле 16 глобальных компаний, занимающихся технологиями ИИ, согласились взять на себя обязательства по обеспечению безопасности при разработке ИИ. [302] [303]
Изучение механического или «формального» рассуждения началось с философов и математиков в древности. Изучение логики привело непосредственно к теории вычислений Алана Тьюринга , которая предполагала, что машина, перетасовывая символы, такие простые, как «0» и «1», может имитировать любую мыслимую форму математического рассуждения. [304] [305] Это, наряду с одновременными открытиями в кибернетике , теории информации и нейробиологии , побудило исследователей рассмотреть возможность создания «электронного мозга». [r] Они разработали несколько областей исследований, которые стали частью ИИ, [307] такие как дизайн Маккалуча и Питтса для «искусственных нейронов» в 1943 году, [115] и влиятельная статья Тьюринга 1950 года « Вычислительная техника и интеллект », которая представила тест Тьюринга и показала, что «машинный интеллект» правдоподобен. [308] [305]
Область исследований ИИ была основана на семинаре в Дартмутском колледже в 1956 году. [s] [6] Участники стали лидерами исследований ИИ в 1960-х годах. [t] Они и их студенты создали программы, которые пресса описала как «поразительные»: [u] компьютеры изучали стратегии игры в шашки , решали текстовые задачи по алгебре, доказывали логические теоремы и говорили по-английски. [v] [7] Лаборатории искусственного интеллекта были созданы в ряде британских и американских университетов в конце 1950-х и начале 1960-х годов. [305]
Исследователи 1960-х и 1970-х годов были убеждены, что их методы в конечном итоге приведут к созданию машины с общим интеллектом, и считали это целью своей области. [312] В 1965 году Герберт Саймон предсказал, что «машины будут способны в течение двадцати лет выполнять любую работу, которую может выполнить человек». [313] В 1967 году Марвин Мински согласился, написав, что «в течение поколения ... проблема создания «искусственного интеллекта» будет в значительной степени решена». [314] Однако они недооценили сложность проблемы. [w] В 1974 году правительства США и Великобритании прекратили исследовательские исследования в ответ на критику сэра Джеймса Лайтхилла [316] и продолжающееся давление со стороны Конгресса США с целью финансирования более продуктивных проектов . [317] Книга Мински и Паперта « Персептроны » была понята как доказательство того, что искусственные нейронные сети никогда не будут полезны для решения реальных задач, тем самым полностью дискредитируя этот подход. [318] Затем последовала « зима ИИ », период, когда было трудно получить финансирование для проектов ИИ. [9]
В начале 1980-х годов исследования ИИ были возрождены коммерческим успехом экспертных систем [319] , формы программы ИИ, которая имитировала знания и аналитические навыки экспертов-людей. К 1985 году рынок ИИ достиг более миллиарда долларов. В то же время японский проект пятого поколения компьютеров вдохновил правительства США и Великобритании восстановить финансирование академических исследований [8] . Однако, начиная с краха рынка Lisp Machine в 1987 году, ИИ снова приобрел дурную славу, и началась вторая, более продолжительная зима. [10]
До этого момента большая часть финансирования ИИ направлялась на проекты, которые использовали символы высокого уровня для представления ментальных объектов, таких как планы, цели, убеждения и известные факты. В 1980-х годах некоторые исследователи начали сомневаться, что этот подход сможет имитировать все процессы человеческого познания, особенно восприятие , робототехнику , обучение и распознавание образов , [320] и начали изучать «субсимволические» подходы. [321] Родни Брукс отверг «представление» в целом и сосредоточился непосредственно на разработке машин, которые двигаются и выживают. [x] Джуда Перл , Лофти Заде и другие разработали методы, которые обрабатывали неполную и неопределенную информацию, делая разумные предположения, а не точную логику. [86] [326] Но самым важным событием стало возрождение « коннекционизма », включая исследования нейронных сетей, Джеффри Хинтоном и другими. [327] В 1990 году Ян Лекун успешно продемонстрировал, что сверточные нейронные сети могут распознавать рукописные цифры, что стало первым из многих успешных применений нейронных сетей. [328]
ИИ постепенно восстановил свою репутацию в конце 1990-х и начале 21-го века, используя формальные математические методы и находя конкретные решения для конкретных проблем. Этот « узкий » и «формальный» фокус позволил исследователям получать проверяемые результаты и сотрудничать с другими областями (такими как статистика , экономика и математика ). [329] К 2000 году решения, разработанные исследователями ИИ, широко использовались, хотя в 1990-х годах их редко называли «искусственным интеллектом» (тенденция, известная как эффект ИИ ). [330] Однако несколько академических исследователей стали беспокоиться о том, что ИИ больше не преследует свою первоначальную цель создания универсальных, полностью интеллектуальных машин. Начиная примерно с 2002 года, они основали подотрасль общего искусственного интеллекта (или «AGI»), которая к 2010-м годам имела несколько хорошо финансируемых институтов. [4]
Глубокое обучение стало доминировать в отраслевых бенчмарках в 2012 году и было принято во всей области. [11] Для многих конкретных задач другие методы были заброшены. [y] Успех глубокого обучения был основан как на усовершенствованиях оборудования ( более быстрые компьютеры , [332] графические процессоры , облачные вычисления [333] ), так и на доступе к большим объемам данных [334] (включая курируемые наборы данных, [333] такие как ImageNet ). Успех глубокого обучения привел к огромному росту интереса и финансирования в области ИИ. [z] Объем исследований в области машинного обучения (измеренный по общему количеству публикаций) увеличился на 50% в 2015–2019 годах. [291]
В 2016 году вопросы справедливости и неправильного использования технологий были выдвинуты на первый план на конференциях по машинному обучению, публикации значительно возросли, финансирование стало доступным, и многие исследователи переориентировали свою карьеру на эти вопросы. Проблема выравнивания стала серьезной областью академических исследований. [268]
В конце подросткового и начале 2020-х годов компании AGI начали поставлять программы, которые вызвали огромный интерес. В 2015 году AlphaGo , разработанная DeepMind , победила чемпиона мира по игре в го . Программа была обучена только правилам игры и сама разрабатывала стратегию. GPT-3 — это большая языковая модель , выпущенная в 2020 году компанией OpenAI и способная генерировать высококачественный текст, похожий на человеческий. [335] Эти и другие программы вдохновили агрессивный бум ИИ , когда крупные компании начали инвестировать миллиарды долларов в исследования ИИ. По данным AI Impacts, около 50 миллиардов долларов ежегодно инвестировалось в «ИИ» около 2022 года только в США, и около 20% новых выпускников докторской степени в области компьютерных наук в США специализируются на «ИИ». [336] В 2022 году в США существовало около 800 000 вакансий, связанных с «ИИ». [337]
Философские дебаты исторически стремились определить природу интеллекта и то, как создавать интеллектуальные машины. [338] Другим важным вопросом было то, могут ли машины обладать сознанием, и связанные с этим этические последствия. [339] Многие другие темы в философии могут иметь отношение к ИИ, такие как эпистемология и свободная воля . [340] Стремительные достижения активизировали публичные дискуссии о философии и этике ИИ. [339]
Алан Тьюринг в 1950 году написал: «Я предлагаю рассмотреть вопрос «могут ли машины думать»?» [341] Он посоветовал изменить вопрос с «думает ли машина» на «может ли машина демонстрировать разумное поведение». [341] Он разработал тест Тьюринга, который измеряет способность машины имитировать человеческий разговор. [308] Поскольку мы можем только наблюдать за поведением машины, неважно, думает ли она «на самом деле» или буквально имеет «разум». Тьюринг отмечает, что мы не можем определить эти вещи о других людях, но «обычно принято иметь вежливое соглашение, что все думают». [342]

Рассел и Норвиг согласны с Тьюрингом в том, что интеллект должен определяться с точки зрения внешнего поведения, а не внутренней структуры. [1] Однако они критически настроены на то, чтобы тест требовал, чтобы машина имитировала людей. « Тексты по авиационной технике », — писали они, — «не определяют цель своей области как создание «машин, которые летают так точно, как голуби , что они могут обманывать других голубей». [ 344] Основатель ИИ Джон Маккарти согласился, написав, что «Искусственный интеллект, по определению, не является имитацией человеческого интеллекта». [345]
Маккарти определяет интеллект как «вычислительную часть способности достигать целей в мире». [346] Другой основатель ИИ, Марвин Мински, аналогичным образом описывает его как «способность решать сложные проблемы». [347] Ведущий учебник по ИИ определяет его как изучение агентов, которые воспринимают окружающую среду и предпринимают действия, которые максимизируют их шансы на достижение определенных целей. [1] Эти определения рассматривают интеллект в терминах четко определенных проблем с четко определенными решениями, где как сложность проблемы, так и производительность программы являются прямыми мерами «интеллекта» машины — и никакое другое философское обсуждение не требуется или даже может быть невозможным.
Другое определение было принято Google, [348] крупным практиком в области ИИ. Это определение предусматривает способность систем синтезировать информацию как проявление интеллекта, аналогично тому, как это определяется в биологическом интеллекте.
Некоторые авторы на практике предположили, что определение ИИ является расплывчатым и его трудно определить, и спорят о том, следует ли классические алгоритмы относить к категории ИИ, [349] при этом многие компании в начале 2020-х годов, во время бума ИИ, использовали этот термин как модное маркетинговое словечко , часто даже если они «фактически не использовали ИИ существенным образом». [350]
Ни одна устоявшаяся объединяющая теория или парадигма не направляла исследования ИИ на протяжении большей части их истории. [aa] Беспрецедентный успех статистического машинного обучения в 2010-х годах затмил все другие подходы (настолько, что некоторые источники, особенно в деловом мире, используют термин «искусственный интеллект» для обозначения «машинного обучения с нейронными сетями»). Этот подход в основном субсимволический , мягкий и узкий . Критики утверждают, что эти вопросы, возможно, придется пересмотреть будущим поколениям исследователей ИИ.
Символический ИИ (или « GOFAI ») [352] имитировал высокоуровневое сознательное рассуждение, которое люди используют, когда решают головоломки, выражают правовые рассуждения и занимаются математикой. Они были очень успешны в «интеллектуальных» задачах, таких как алгебра или тесты IQ. В 1960-х годах Ньюэлл и Саймон предложили гипотезу физических систем символов : «Физическая система символов имеет необходимые и достаточные средства для общих интеллектуальных действий». [353]
Однако символический подход не справился со многими задачами, которые люди решают легко, такими как обучение, распознавание объекта или рассуждения здравого смысла. Парадокс Моравека заключается в открытии того, что высокоуровневые «интеллектуальные» задачи были легкими для ИИ, но низкоуровневые «инстинктивные» задачи были чрезвычайно трудными. [ 354] Философ Хьюберт Дрейфус с 1960-х годов утверждал , что человеческая экспертиза зависит от бессознательного инстинкта, а не от сознательной манипуляции символами, и от наличия «чувства» ситуации, а не явного символического знания. [355] Хотя его аргументы были высмеяны и проигнорированы, когда они были впервые представлены, в конечном итоге исследователи ИИ согласились с ним. [ab] [16]
Проблема не решена: субсимволическое рассуждение может совершать многие из тех же непостижимых ошибок, что и человеческая интуиция, например, алгоритмическую предвзятость . Критики, такие как Ноам Хомский, утверждают, что продолжение исследований символического ИИ все еще будет необходимо для достижения общего интеллекта, [357] [358] отчасти потому, что субсимволический ИИ — это шаг в сторону от объяснимого ИИ : может быть трудно или невозможно понять, почему современная статистическая программа ИИ приняла определенное решение. Возникающая область нейросимволического искусственного интеллекта пытается объединить два подхода.
«Чистоплотные» надеются, что интеллектуальное поведение описывается с помощью простых, элегантных принципов (таких как логика , оптимизация или нейронные сети ). «Неряхи» ожидают, что это обязательно потребует решения большого количества не связанных между собой проблем. Чистоплотные защищают свои программы с теоретической строгостью, неряхи в основном полагаются на инкрементальное тестирование, чтобы увидеть, работают ли они. Этот вопрос активно обсуждался в 1970-х и 1980-х годах, [359] , но в конечном итоге был признан неактуальным. Современный ИИ имеет элементы обоих.
Нахождение доказуемо правильного или оптимального решения является неразрешимым для многих важных проблем. [15] Мягкие вычисления — это набор методов, включая генетические алгоритмы , нечеткую логику и нейронные сети, которые терпимы к неточности, неопределенности, частичной истинности и приближению. Мягкие вычисления были введены в конце 1980-х годов, и большинство успешных программ ИИ в 21 веке являются примерами мягких вычислений с нейронными сетями.
Исследователи ИИ разделились во мнениях относительно того, следует ли напрямую преследовать цели общего искусственного интеллекта и сверхинтеллекта или решать как можно больше конкретных проблем (узкий ИИ) в надежде, что эти решения косвенно приведут к долгосрочным целям области. [360] [361] Общий интеллект трудно определить и трудно измерить, и современный ИИ добился более проверяемых успехов, сосредоточившись на конкретных проблемах с конкретными решениями. Подотрасль общего искусственного интеллекта изучает исключительно эту область.
Философия разума не знает, может ли машина иметь разум , сознание и ментальные состояния в том же смысле, что и люди. Этот вопрос рассматривает внутренние переживания машины, а не ее внешнее поведение. Основные исследования ИИ считают этот вопрос неактуальным, поскольку он не влияет на цели этой области: создавать машины, которые могут решать проблемы с помощью интеллекта. Рассел и Норвиг добавляют, что «дополнительный проект по созданию машины, сознательной точно так же, как и люди, — это не тот, к которому мы готовы». [362] Однако этот вопрос стал центральным для философии разума. Это также, как правило, центральный вопрос, обсуждаемый в области искусственного интеллекта в художественной литературе .
Дэвид Чалмерс выделил две проблемы в понимании разума, которые он назвал «трудными» и «легкими» проблемами сознания. [363] Легкая проблема заключается в понимании того, как мозг обрабатывает сигналы, строит планы и контролирует поведение. Трудная проблема заключается в объяснении того, как это ощущается или почему это вообще должно ощущаться как что-то, предполагая, что мы правы, думая, что это действительно ощущается как что-то (иллюзионизм сознания Деннета утверждает, что это иллюзия). В то время как человеческую обработку информации легко объяснить, человеческий субъективный опыт объяснить трудно. Например, легко представить себе дальтоника, который научился определять, какие объекты в его поле зрения красные, но неясно, что потребуется для того, чтобы человек знал, как выглядит красный цвет . [364]
Вычислительный подход — это позиция в философии разума , согласно которой человеческий разум — это система обработки информации, а мышление — это форма вычислений. Вычислительный подход утверждает, что отношения между разумом и телом аналогичны или идентичны отношениям между программным обеспечением и оборудованием и, таким образом, могут быть решением проблемы разума и тела . Эта философская позиция была вдохновлена работой исследователей ИИ и когнитивных ученых в 1960-х годах и первоначально была предложена философами Джерри Фодором и Хилари Патнэмом . [365]
Философ Джон Сирл охарактеризовал эту позицию как « сильный ИИ »: «Соответствующим образом запрограммированный компьютер с правильными входами и выходами будет, таким образом, обладать разумом в том же смысле, в котором разум есть у людей». [ac] Сирл противопоставляет этому утверждению свой аргумент китайской комнаты, который пытается показать, что даже если машина идеально имитирует человеческое поведение, все равно нет оснований предполагать, что у нее также есть разум. [369]
Трудно или невозможно достоверно оценить, является ли развитый ИИ разумным (имеет ли он способность чувствовать), и если да, то в какой степени. [370] Но если есть значительная вероятность того, что данная машина может чувствовать и страдать, то она может иметь право на определенные права или меры защиты благосостояния, подобно животным. [371] [372] Разумность (набор способностей, связанных с высоким интеллектом, таких как проницательность или самосознание ) может обеспечить еще одну моральную основу для прав ИИ. [371] Права роботов также иногда предлагаются как практический способ интеграции автономных агентов в общество. [373]
В 2017 году Европейский союз рассматривал возможность предоставления «электронной личности» некоторым из наиболее эффективных систем ИИ. Подобно правовому статусу компаний, это предоставило бы права, но также и обязанности. [374] Критики утверждали в 2018 году, что предоставление прав системам ИИ приуменьшит важность прав человека , и что законодательство должно быть сосредоточено на потребностях пользователей, а не на спекулятивных футуристических сценариях. Они также отметили, что роботам не хватает автономии, чтобы самостоятельно участвовать в жизни общества. [375] [376]
Прогресс в области ИИ повысил интерес к этой теме. Сторонники благосостояния и прав ИИ часто утверждают, что разумность ИИ, если она появится, будет особенно легко отрицать. Они предупреждают, что это может быть моральным слепым пятном, аналогичным рабству или промышленному животноводству , что может привести к масштабным страданиям, если разумный ИИ будет создан и небрежно эксплуатироваться. [372] [371]
Сверхразум — это гипотетический агент, который будет обладать интеллектом, намного превосходящим интеллект самого яркого и одаренного человеческого разума. [361] Если бы исследования в области искусственного интеллекта привели к созданию достаточно разумного программного обеспечения, оно могло бы перепрограммировать и улучшить себя . Улучшенное программное обеспечение могло бы еще лучше улучшать себя, что привело бы к тому, что И. Дж. Гуд назвал « взрывом интеллекта », а Вернор Виндж — « сингулярностью ». [377]
Однако технологии не могут совершенствоваться экспоненциально бесконечно и обычно следуют S-образной кривой , замедляясь, когда достигают физических пределов того, что технология может сделать. [378]
Конструктор роботов Ганс Моравек , кибернетик Кевин Уорвик и изобретатель Рэй Курцвейл предсказали, что люди и машины могут в будущем объединиться в киборгов, которые будут более способными и сильными, чем те и другие. Эта идея, называемая трансгуманизмом , имеет корни в трудах Олдоса Хаксли и Роберта Эттингера . [379]
Эдвард Фредкин утверждает, что «искусственный интеллект — это следующий шаг в эволюции», идея, впервые предложенная Сэмюэлем Батлером в его книге « Дарвин среди машин » еще в 1863 году и расширенная Джорджем Дайсоном в его книге 1998 года «Дарвин среди машин: эволюция глобального интеллекта» . [380]

Искусственные существа, способные мыслить, появлялись в качестве средств повествования еще со времен античности [381] и были постоянной темой в научной фантастике . [382]
Распространенный троп в этих работах начался с «Франкенштейна » Мэри Шелли , где человеческое творение становится угрозой для своих хозяев. Сюда входят такие работы, как «Космическая одиссея 2001 года» Артура Кларка и Стэнли Кубрика (оба 1968 года) с HAL 9000 , смертоносным компьютером, управляющим космическим кораблем Discovery One , а также «Терминатор» (1984) и «Матрица» (1999). Напротив, редкие верные роботы, такие как Горт из «Дня, когда Земля остановилась» (1951) и Бишоп из «Чужих» (1986), менее заметны в популярной культуре. [383]
Айзек Азимов представил Три Закона Робототехники во многих рассказах, наиболее заметным из которых является супер-разумный компьютер « Мультивак ». Законы Азимова часто поднимаются во время непрофессиональных дискуссий о машинной этике; [384] хотя почти все исследователи искусственного интеллекта знакомы с законами Азимова через популярную культуру, они, как правило, считают эти законы бесполезными по многим причинам, одной из которых является их неоднозначность. [385]
Несколько работ используют ИИ, чтобы заставить нас столкнуться с фундаментальным вопросом о том, что делает нас людьми, показывая нам искусственные существа, которые обладают способностью чувствовать , и, таким образом, страдать. Это появляется в RUR Карела Чапека , фильмах Искусственный интеллект и Из машины , а также в романе Мечтают ли андроиды об электроовцах? Филипа К. Дика . Дик рассматривает идею о том, что наше понимание человеческой субъективности изменяется под воздействием технологий, созданных с помощью искусственного интеллекта. [386]
Два наиболее широко используемых учебника в 2023 году (см. Открытую программу):
Вот четыре наиболее широко используемых учебника по ИИ в 2008 году:
Другие учебники:
Вместо этого Соединенные Штаты разработали новую область доминирования, на которую остальной мир смотрит со смесью благоговения, зависти и негодования: искусственный интеллект... От моделей и исследований ИИ до облачных вычислений и венчурного капитала американские компании, университеты и исследовательские лаборатории — и их филиалы в странах-союзниках — по-видимому, имеют огромное преимущество как в разработке передового ИИ, так и в его коммерциализации. Стоимость венчурных инвестиций США в стартапы в области ИИ превышает стоимость остального мира вместе взятого.